 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgery: Mitigating Harmful Fine-Tuning for Large Language Models via Attention Sink
Feb 05, 2026Harmful fine-tuning can invalidate safety alignment of large language models, exposing significant safety risks. In this paper, we utilize the attention sink mechanism to mitigate harmful fine-tuning. Specifically, we first measure a statistic named \emph{sink divergence} for each attention head and observe that \emph{different attention heads exhibit two different signs of sink divergence}. To understand its safety implications, we conduct experiments and find that the number of attention heads of positive sink divergence increases along with the increase of the model's harmfulness when undergoing harmful fine-tuning. Based on this finding, we propose a separable sink divergence hypothesis -- \emph{attention heads associating with learning harmful patterns during fine-tuning are separable by their sign of sink divergence}. Based on the hypothesis, we propose a fine-tuning-stage defense, dubbed Surgery. Surgery utilizes a regularizer for sink divergence suppression, which steers attention heads toward the negative sink divergence group, thereby reducing the model's tendency to learn and amplify harmful patterns. Extensive experiments demonstrate that Surgery improves defense performance by 5.90\%, 11.25\%, and 9.55\% on the BeaverTails, HarmBench, and SorryBench benchmarks, respectively. Source code is available on https://github.com/Lslland/Surgery.
Targeted Vaccine: Safety Alignment for Large Language Models against Harmful Fine-Tuning via Layer-wise Perturbation
Oct 13, 2024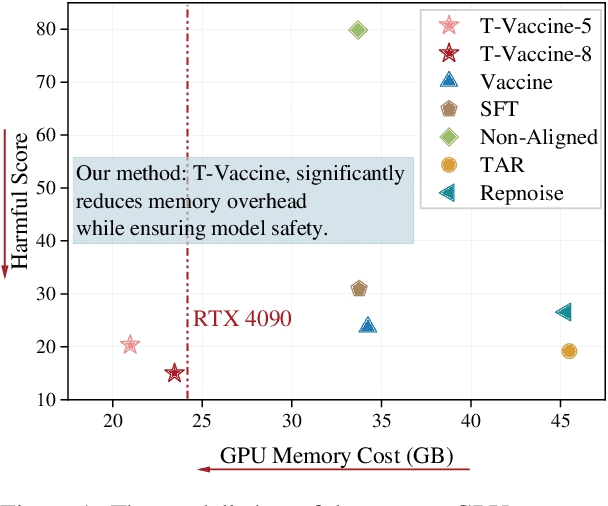
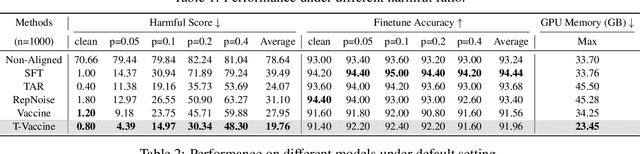
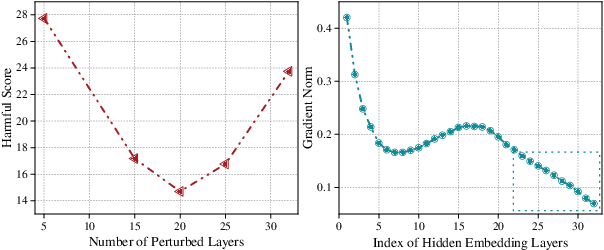
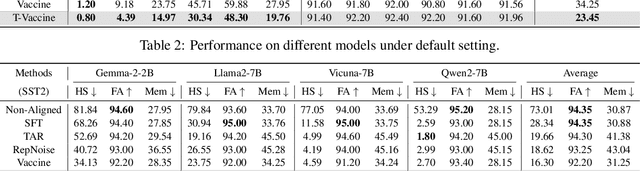
Harmful fine-tuning attack poses a serious threat to the online fine-tuning service. Vaccine, a recent alignment-stage defense, applies uniform perturbation to all layers of embedding to make the model robust to the simulated embedding drift. However, applying layer-wise uniform perturbation may lead to excess perturbations for some particular safety-irrelevant layers, resulting in defense performance degradation and unnecessary memory consumption. To address this limitation, we propose Targeted Vaccine (T-Vaccine), a memory-efficient safety alignment method that applies perturbation to only selected layers of the model. T-Vaccine follows two core steps: First, it uses gradient norm as a statistical metric to identify the safety-critical layers. Second, instead of applying uniform perturbation across all layers, T-Vaccine only applies perturbation to the safety-critical layers while keeping other layers frozen during training. Results show that T-Vaccine outperforms Vaccine in terms of both defense effectiveness and resource efficiency. Comparison with other defense baselines, e.g., RepNoise and TAR also demonstrate the superiority of T-Vaccine. Notably, T-Vaccine is the first defense that can address harmful fine-tuning issues for a 7B pre-trained models trained on consumer GPUs with limited memory (e.g., RTX 4090). Our code is available at https://github.com/Lslland/T-Vaccine.
CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
Sep 27, 2024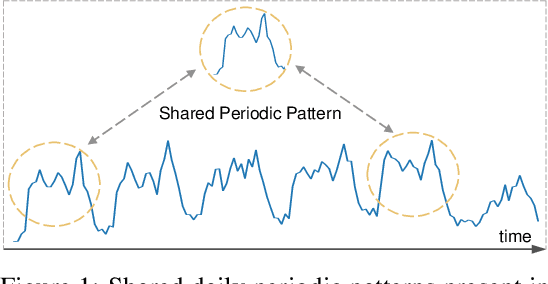
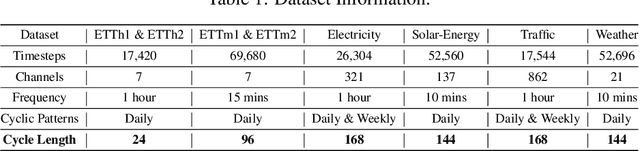
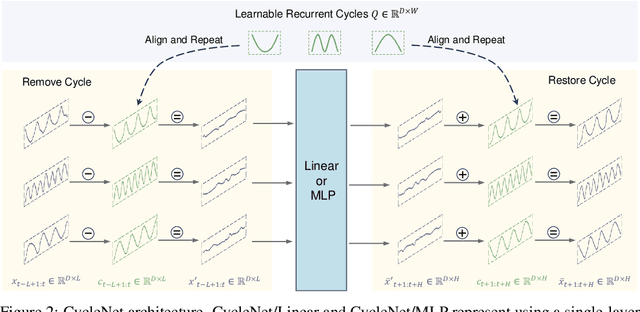
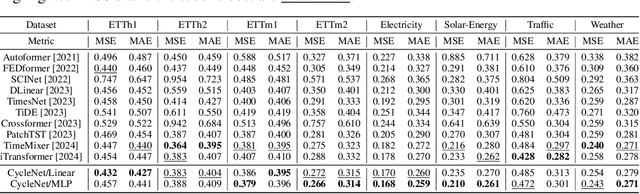
The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting
Aug 22, 2023



RNN-based methods have faced challenges in the Long-term Time Series Forecasting (LTSF) domain when dealing with excessively long look-back windows and forecast horizons. Consequently, the dominance in this domain has shifted towards Transformer, MLP, and CNN approaches. The substantial number of recurrent iterations are the fundamental reasons behind the limitations of RNNs in LTSF. To address these issues, we propose two novel strategies to reduce the number of iterations in RNNs for LTSF tasks: Segment-wise Iterations and Parallel Multi-step Forecasting (PMF). RNNs that combine these strategies, namely SegRNN, significantly reduce the required recurrent iterations for LTSF, resulting in notable improvements in forecast accuracy and inference speed. Extensive experiments demonstrate that SegRNN not only outperforms SOTA Transformer-based models but also reduces runtime and memory usage by more than 78%. These achievements provide strong evidence that RNNs continue to excel in LTSF tasks and encourage further exploration of this domain with more RNN-based approaches. The source code is coming soon.