 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgery: Mitigating Harmful Fine-Tuning for Large Language Models via Attention Sink
Feb 05, 2026Harmful fine-tuning can invalidate safety alignment of large language models, exposing significant safety risks. In this paper, we utilize the attention sink mechanism to mitigate harmful fine-tuning. Specifically, we first measure a statistic named \emph{sink divergence} for each attention head and observe that \emph{different attention heads exhibit two different signs of sink divergence}. To understand its safety implications, we conduct experiments and find that the number of attention heads of positive sink divergence increases along with the increase of the model's harmfulness when undergoing harmful fine-tuning. Based on this finding, we propose a separable sink divergence hypothesis -- \emph{attention heads associating with learning harmful patterns during fine-tuning are separable by their sign of sink divergence}. Based on the hypothesis, we propose a fine-tuning-stage defense, dubbed Surgery. Surgery utilizes a regularizer for sink divergence suppression, which steers attention heads toward the negative sink divergence group, thereby reducing the model's tendency to learn and amplify harmful patterns. Extensive experiments demonstrate that Surgery improves defense performance by 5.90\%, 11.25\%, and 9.55\% on the BeaverTails, HarmBench, and SorryBench benchmarks, respectively. Source code is available on https://github.com/Lslland/Surgery.
Targeted Vaccine: Safety Alignment for Large Language Models against Harmful Fine-Tuning via Layer-wise Perturbation
Oct 13, 2024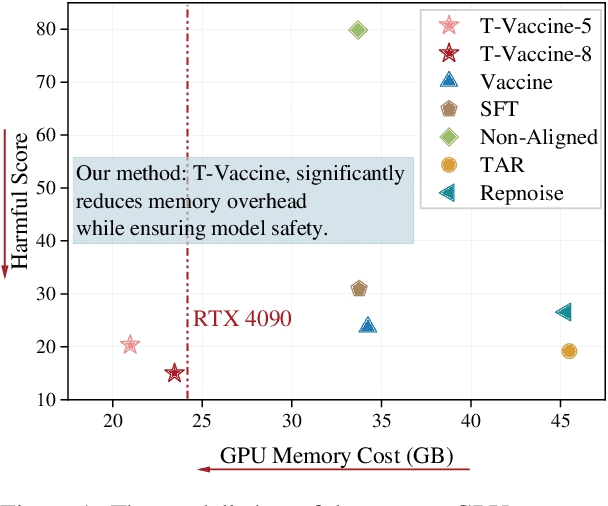
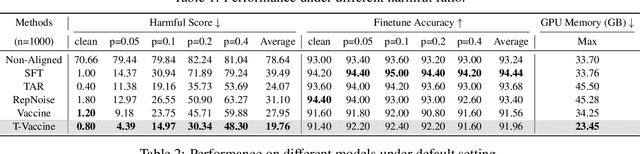
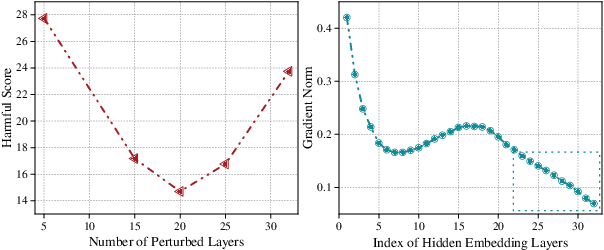
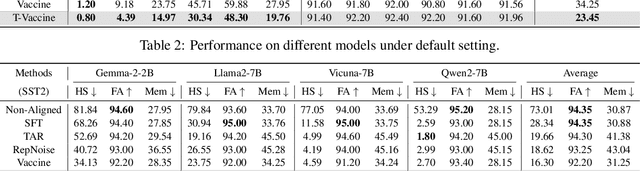
Harmful fine-tuning attack poses a serious threat to the online fine-tuning service. Vaccine, a recent alignment-stage defense, applies uniform perturbation to all layers of embedding to make the model robust to the simulated embedding drift. However, applying layer-wise uniform perturbation may lead to excess perturbations for some particular safety-irrelevant layers, resulting in defense performance degradation and unnecessary memory consumption. To address this limitation, we propose Targeted Vaccine (T-Vaccine), a memory-efficient safety alignment method that applies perturbation to only selected layers of the model. T-Vaccine follows two core steps: First, it uses gradient norm as a statistical metric to identify the safety-critical layers. Second, instead of applying uniform perturbation across all layers, T-Vaccine only applies perturbation to the safety-critical layers while keeping other layers frozen during training. Results show that T-Vaccine outperforms Vaccine in terms of both defense effectiveness and resource efficiency. Comparison with other defense baselines, e.g., RepNoise and TAR also demonstrate the superiority of T-Vaccine. Notably, T-Vaccine is the first defense that can address harmful fine-tuning issues for a 7B pre-trained models trained on consumer GPUs with limited memory (e.g., RTX 4090). Our code is available at https://github.com/Lslland/T-Vaccine.
Color Image Enhancement Method Based on Weighted Image Guided Filtering
Dec 24, 2018A novel color image enhancement method is proposed based on Retinex to enhance color images under non-uniform illumination or poor visibility conditions. Different from the conventional Retinex algorithms, the Weighted Guided Image Filter is used as a surround function instead of the Gaussian filter to estimate the background illumination, which can overcome the drawbacks of local blur and halo artifact that may appear by Gaussian filter. To avoid color distortion, the image is converted to the HSI color model, and only the intensity channel is enhanced. Then a linear color restoration algorithm is adopted to convert the enhanced intensity image back to the RGB color model, which ensures the hue is constant and undistorted. Experimental results show that the proposed method is effective to enhance both color and gray images with low exposure and non-uniform illumination, resulting in better visual quality than traditional method. At the same time, the objective evaluation indicators are also superior to the conventional methods. In addition, the efficiency of the proposed method is also improved thanks to the linear color restoration algorithm.