 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-aware Inference Optimizations for Large Vision-Language Models with Memory-efficient Decoding
Mar 25, 2026Large Vision-Language Models (VLMs) have achieved remarkable success in multi-modal reasoning, but their inference time efficiency remains a significant challenge due to the memory overhead during decoding, especially when the query and answer of VLMs consist of long sequences of visual and text tokens. This paper presents AttentionPack, an adaptive and attention-aware optimization framework tailored for large vision-language models with improving memory-efficiency during decoding, focusing on addressing the challenges due to the increased high number of visual inputs and interactions, particularly in long-context tasks with multiple high-resolution images or videos. AttentionPack is novel in two aspects: (i) We introduce a multi-head attention compaction method for economically storing key and value matrices by exploiting the implicit low-rank structure, and (ii) we develop a token-specific attention-aware decompression mechanism to reduce latency overhead. Experimental results on multiple benchmarks demonstrate that AttentionPack improves memory efficiency by up to 8x, enabling higher batch sizes and faster batch inference while preserving the model output quality or longer context lengths for superior retrieval performance. We also report the effectiveness of AttentionPack combined with eviction, quantization and kernel fusion, showing further efficiency gains for resource-limited environments.
A Multi-Agent Perception-Action Alliance for Efficient Long Video Reasoning
Mar 14, 2026This paper presents a multi-agent perception-action exploration alliance, dubbed A4VL, for efficient long-video reasoning. A4VL operates in a multi-round perception-action exploration loop with a selection of VLM agents. In each round, the team of agents performs video question-answer (VideoQA) via perception exploration followed by action exploration. During perception exploration, each agent learns to extract query-specific perception clue(s) from a few sampled frames and performs clue-based alignment to find the video block(s) that are most relevant to the query-specific event. During action exploration, A4VL performs video reasoning in three steps: (1) each agent produces its initial answer with rational, (2) all agents collaboratively scores one another through cross-reviews and relevance ranking, and (3) based on whether a satisfactory consensus is reached, the decision is made either to start a new round of perception-action deliberation by pruning (e.g., filtering out the lowest performing agent) and re-staging (e.g., new-clue and matching block based perception-action exploration), or to conclude by producing its final answer. The integration of the multi-agent alliance through multi-round perception-action exploration, coupled with event-driven partitioning and cue-guided block alignment, enables A4VL to effectively scale to real world long videos while preserving high quality video reasoning. Evaluation Results on five popular VideoQA benchmarks show that A4VL outperforms 18 existing representative VLMs and 10 recent methods optimized for long-video reasoning, while achieving significantly lower inference latency. Our code is released at https://github.com/git-disl/A4VL.
Surgery: Mitigating Harmful Fine-Tuning for Large Language Models via Attention Sink
Feb 05, 2026Harmful fine-tuning can invalidate safety alignment of large language models, exposing significant safety risks. In this paper, we utilize the attention sink mechanism to mitigate harmful fine-tuning. Specifically, we first measure a statistic named \emph{sink divergence} for each attention head and observe that \emph{different attention heads exhibit two different signs of sink divergence}. To understand its safety implications, we conduct experiments and find that the number of attention heads of positive sink divergence increases along with the increase of the model's harmfulness when undergoing harmful fine-tuning. Based on this finding, we propose a separable sink divergence hypothesis -- \emph{attention heads associating with learning harmful patterns during fine-tuning are separable by their sign of sink divergence}. Based on the hypothesis, we propose a fine-tuning-stage defense, dubbed Surgery. Surgery utilizes a regularizer for sink divergence suppression, which steers attention heads toward the negative sink divergence group, thereby reducing the model's tendency to learn and amplify harmful patterns. Extensive experiments demonstrate that Surgery improves defense performance by 5.90\%, 11.25\%, and 9.55\% on the BeaverTails, HarmBench, and SorryBench benchmarks, respectively. Source code is available on https://github.com/Lslland/Surgery.
Mitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
Rebellion: Noise-Robust Reasoning Training for Audio Reasoning Models
Nov 12, 2025Instilling reasoning capabilities in large models (LMs) using reasoning training (RT) significantly improves LMs' performances. Thus Audio Reasoning Models (ARMs), i.e., audio LMs that can reason, are becoming increasingly popular. However, no work has studied the safety of ARMs against jailbreak attacks that aim to elicit harmful responses from target models. To this end, first, we show that standard RT with appropriate safety reasoning data can protect ARMs from vanilla audio jailbreaks, but cannot protect them against our proposed simple yet effective jailbreaks. We show that this is because of the significant representation drift between vanilla and advanced jailbreaks which forces the target ARMs to emit harmful responses. Based on this observation, we propose Rebellion, a robust RT that trains ARMs to be robust to the worst-case representation drift. All our results are on Qwen2-Audio; they demonstrate that Rebellion: 1) can protect against advanced audio jailbreaks without compromising performance on benign tasks, and 2) significantly improves accuracy-safety trade-off over standard RT method.
FedHFT: Efficient Federated Finetuning with Heterogeneous Edge Clients
Oct 15, 2025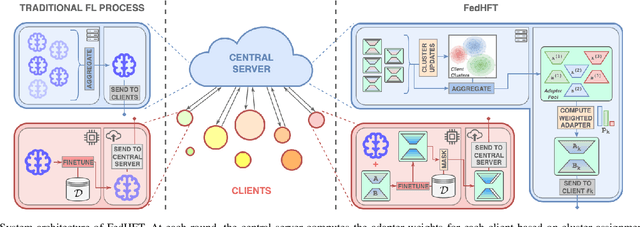
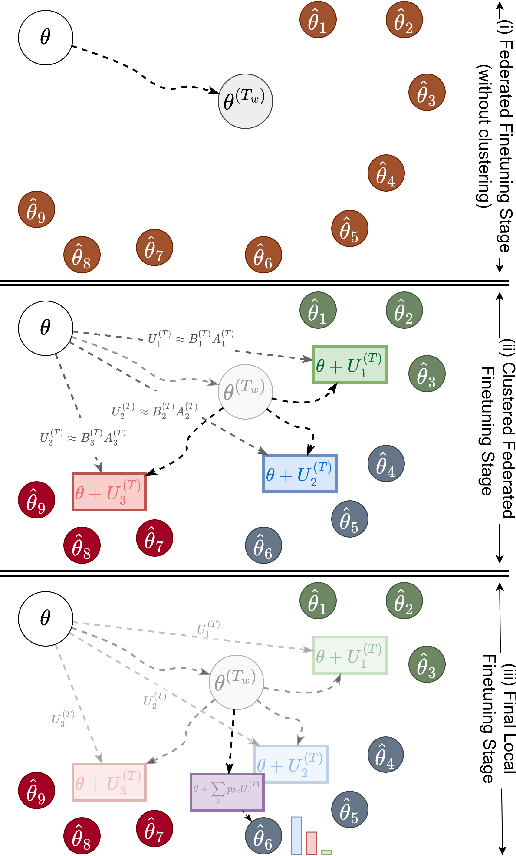
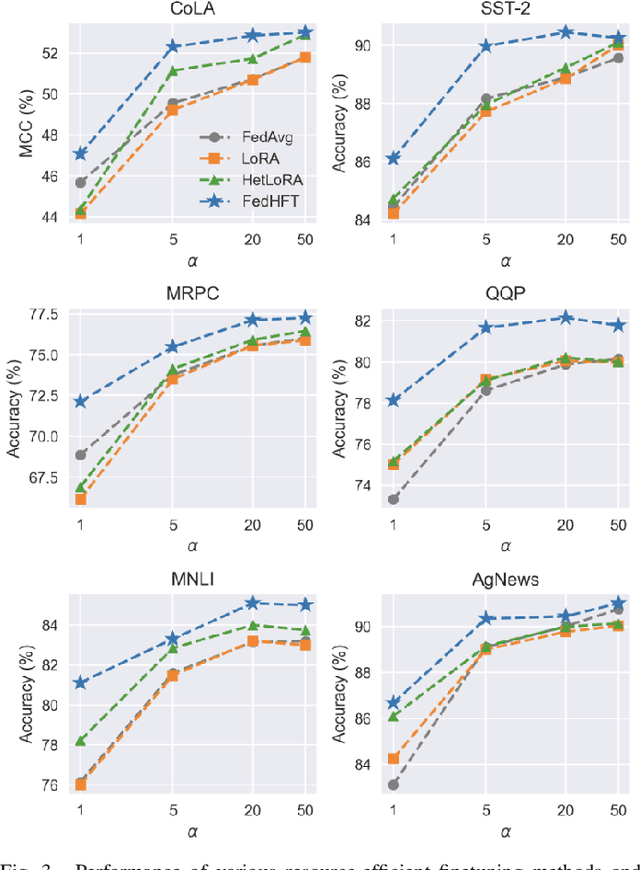
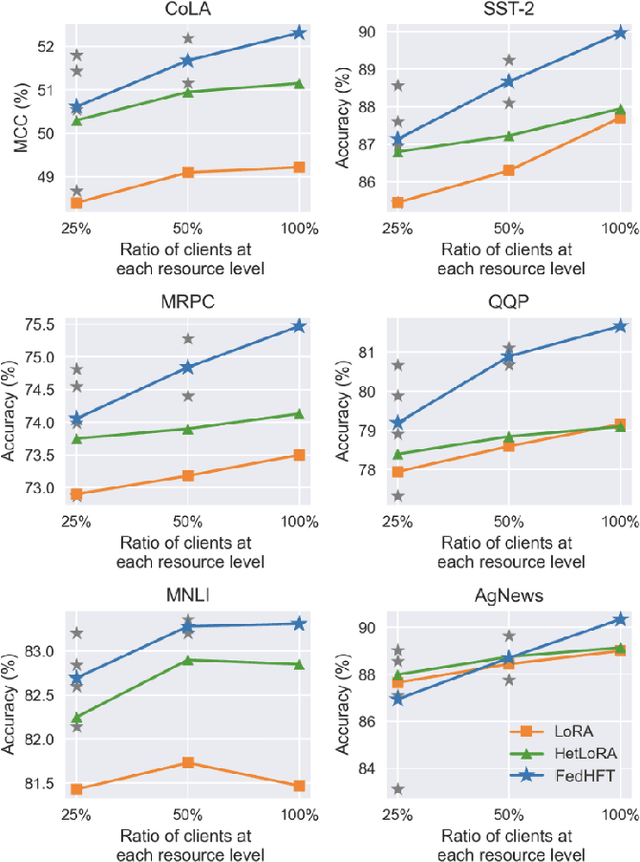
Fine-tuning pre-trained large language models (LLMs) has become a common practice for personalized natural language understanding (NLU) applications on downstream tasks and domain-specific datasets. However, there are two main challenges: (i) limited and/or heterogeneous data for fine-tuning due to proprietary data confidentiality or privacy requirements, and (ii) varying computation resources available across participating clients such as edge devices. This paper presents FedHFT - an efficient and personalized federated fine-tuning framework to address both challenges. First, we introduce a mixture of masked adapters to handle resource heterogeneity across participating clients, enabling high-performance collaborative fine-tuning of pre-trained language model(s) across multiple clients in a distributed setting, while keeping proprietary data local. Second, we introduce a bi-level optimization approach to handle non-iid data distribution based on masked personalization and client clustering. Extensive experiments demonstrate significant performance and efficiency improvements over various natural language understanding tasks under data and resource heterogeneity compared to representative heterogeneous federated learning methods.
Gradient Surgery for Safe LLM Fine-Tuning
Aug 10, 2025Fine-tuning-as-a-Service introduces a critical vulnerability where a few malicious examples mixed into the user's fine-tuning dataset can compromise the safety alignment of Large Language Models (LLMs). While a recognized paradigm frames safe fine-tuning as a multi-objective optimization problem balancing user task performance with safety alignment, we find existing solutions are critically sensitive to the harmful ratio, with defenses degrading sharply as harmful ratio increases. We diagnose that this failure stems from conflicting gradients, where the user-task update directly undermines the safety objective. To resolve this, we propose SafeGrad, a novel method that employs gradient surgery. When a conflict is detected, SafeGrad nullifies the harmful component of the user-task gradient by projecting it onto the orthogonal plane of the alignment gradient, allowing the model to learn the user's task without sacrificing safety. To further enhance robustness and data efficiency, we employ a KL-divergence alignment loss that learns the rich, distributional safety profile of the well-aligned foundation model. Extensive experiments show that SafeGrad provides state-of-the-art defense across various LLMs and datasets, maintaining robust safety even at high harmful ratios without compromising task fidelity.
Language-Vision Planner and Executor for Text-to-Visual Reasoning
Jun 09, 2025The advancement in large language models (LLMs) and large vision models has fueled the rapid progress in multi-modal visual-text reasoning capabilities. However, existing vision-language models (VLMs) to date suffer from generalization performance. Inspired by recent development in LLMs for visual reasoning, this paper presents VLAgent, an AI system that can create a step-by-step visual reasoning plan with an easy-to-understand script and execute each step of the plan in real time by integrating planning script with execution verifications via an automated process supported by VLAgent. In the task planning phase, VLAgent fine-tunes an LLM through in-context learning to generate a step-by-step planner for each user-submitted text-visual reasoning task. During the plan execution phase, VLAgent progressively refines the composition of neuro-symbolic executable modules to generate high-confidence reasoning results. VLAgent has three unique design characteristics: First, we improve the quality of plan generation through in-context learning, improving logic reasoning by reducing erroneous logic steps, incorrect programs, and LLM hallucinations. Second, we design a syntax-semantics parser to identify and correct additional logic errors of the LLM-generated planning script prior to launching the plan executor. Finally, we employ the ensemble method to improve the generalization performance of our step-executor. Extensive experiments with four visual reasoning benchmarks (GQA, MME, NLVR2, VQAv2) show that VLAgent achieves significant performance enhancement for multimodal text-visual reasoning applications, compared to the exiting representative VLMs and LLM based visual composition approaches like ViperGPT and VisProg, thanks to the novel optimization modules of VLAgent back-engine (SS-Parser, Plan Repairer, Output Verifiers). Code and data will be made available upon paper acceptance.
R1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress
CTRAP: Embedding Collapse Trap to Safeguard Large Language Models from Harmful Fine-Tuning
May 22, 2025Fine-tuning-as-a-service, while commercially successful for Large Language Model (LLM) providers, exposes models to harmful fine-tuning attacks. As a widely explored defense paradigm against such attacks, unlearning attempts to remove malicious knowledge from LLMs, thereby essentially preventing them from being used to perform malicious tasks. However, we highlight a critical flaw: the powerful general adaptability of LLMs allows them to easily bypass selective unlearning by rapidly relearning or repurposing their capabilities for harmful tasks. To address this fundamental limitation, we propose a paradigm shift: instead of selective removal, we advocate for inducing model collapse--effectively forcing the model to "unlearn everything"--specifically in response to updates characteristic of malicious adaptation. This collapse directly neutralizes the very general capabilities that attackers exploit, tackling the core issue unaddressed by selective unlearning. We introduce the Collapse Trap (CTRAP) as a practical mechanism to implement this concept conditionally. Embedded during alignment, CTRAP pre-configures the model's reaction to subsequent fine-tuning dynamics. If updates during fine-tuning constitute a persistent attempt to reverse safety alignment, the pre-configured trap triggers a progressive degradation of the model's core language modeling abilities, ultimately rendering it inert and useless for the attacker. Crucially, this collapse mechanism remains dormant during benign fine-tuning, ensuring the model's utility and general capabilities are preserved for legitimate users. Extensive empirical results demonstrate that CTRAP effectively counters harmful fine-tuning risks across various LLMs and attack settings, while maintaining high performance in benign scenarios. Our code is available at https://anonymous.4open.science/r/CTRAP.