 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning
Feb 26, 2026Chain-of-Thought (CoT) has substantially empowered Large Language Models (LLMs) to tackle complex reasoning tasks, yet the verbose nature of explicit reasoning steps incurs prohibitive inference latency and computational costs, limiting real-world deployment. While existing compression methods - ranging from self-training to Reinforcement Learning (RL) with length constraints - attempt to mitigate this, they often sacrifice reasoning capability for brevity. We identify a critical failure mode in these approaches: explicitly optimizing for shorter trajectories triggers rapid entropy collapse, which prematurely shrinks the exploration space and stifles the discovery of valid reasoning paths, particularly for challenging questions requiring extensive deduction. To address this issue, we propose Compress responses for Easy questions and Explore Hard ones (CEEH), a difficulty-aware approach to RL-based efficient reasoning. CEEH dynamically assesses instance difficulty to apply selective entropy regularization: it preserves a diverse search space for currently hard questions to ensure robustness, while permitting aggressive compression on easier instances where the reasoning path is well-established. In addition, we introduce a dynamic optimal-length penalty anchored to the historically shortest correct response, which effectively counteracts entropy-induced length inflation and stabilizes the reward signal. Across six reasoning benchmarks, CEEH consistently reduces response length while maintaining accuracy comparable to the base model, and improves Pass@k relative to length-only optimization.
Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System
Feb 09, 2026Integrating Large Language Models (LLMs) with external tools via multi-agent systems offers a promising new paradigm for decomposing and solving complex problems. However, training these systems remains notoriously difficult due to the credit assignment challenge, as it is often unclear which specific functional agent is responsible for the success or failure of decision trajectories. Existing methods typically rely on sparse or globally broadcast rewards, failing to capture individual contributions and leading to inefficient reinforcement learning. To address these limitations, we introduce the Shapley-based Hierarchical Attribution for Reinforcement Policy (SHARP), a novel framework for optimizing multi-agent reinforcement learning via precise credit attribution. SHARP effectively stabilizes training by normalizing agent-specific advantages across trajectory groups, primarily through a decomposed reward mechanism comprising a global broadcast-accuracy reward, a Shapley-based marginal-credit reward for each agent, and a tool-process reward to improve execution efficiency. Extensive experiments across various real-world benchmarks demonstrate that SHARP significantly outperforms recent state-of-the-art baselines, achieving average match improvements of 23.66% and 14.05% over single-agent and multi-agent approaches, respectively.
Agent-Omit: Training Efficient LLM Agents for Adaptive Thought and Observation Omission via Agentic Reinforcement Learning
Feb 04, 2026Managing agent thought and observation during multi-turn agent-environment interactions is an emerging strategy to improve agent efficiency. However, existing studies treat the entire interaction trajectories equally, overlooking the thought necessity and observation utility varies across turns. To this end, we first conduct quantitative investigations into how thought and observation affect agent effectiveness and efficiency. Based on our findings, we propose Agent-Omit, a unified training framework that empowers LLM agents to adaptively omit redundant thoughts and observations. Specifically, we first synthesize a small amount of cold-start data, including both single-turn and multi-turn omission scenarios, to fine-tune the agent for omission behaviors. Furthermore, we introduce an omit-aware agentic reinforcement learning approach, incorporating a dual sampling mechanism and a tailored omission reward to incentivize the agent's adaptive omission capability. Theoretically, we prove that the deviation of our omission policy is upper-bounded by KL-divergence. Experimental results on five agent benchmarks show that our constructed Agent-Omit-8B could obtain performance comparable to seven frontier LLM agent, and achieve the best effectiveness-efficiency trade-off than seven efficient LLM agents methods. Our code and data are available at https://github.com/usail-hkust/Agent-Omit.
Mitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
Darwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
SafeThinker: Reasoning about Risk to Deepen Safety Beyond Shallow Alignment
Jan 23, 2026Despite the intrinsic risk-awareness of Large Language Models (LLMs), current defenses often result in shallow safety alignment, rendering models vulnerable to disguised attacks (e.g., prefilling) while degrading utility. To bridge this gap, we propose SafeThinker, an adaptive framework that dynamically allocates defensive resources via a lightweight gateway classifier. Based on the gateway's risk assessment, inputs are routed through three distinct mechanisms: (i) a Standardized Refusal Mechanism for explicit threats to maximize efficiency; (ii) a Safety-Aware Twin Expert (SATE) module to intercept deceptive attacks masquerading as benign queries; and (iii) a Distribution-Guided Think (DDGT) component that adaptively intervenes during uncertain generation. Experiments show that SafeThinker significantly lowers attack success rates across diverse jailbreak strategies without compromising utility, demonstrating that coordinating intrinsic judgment throughout the generation process effectively balances robustness and practicality.
R1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress
Not All Thoughts are Generated Equal: Efficient LLM Reasoning via Multi-Turn Reinforcement Learning
May 17, 2025



Compressing long chain-of-thought (CoT) from large language models (LLMs) is an emerging strategy to improve the reasoning efficiency of LLMs. Despite its promising benefits, existing studies equally compress all thoughts within a long CoT, hindering more concise and effective reasoning. To this end, we first investigate the importance of different thoughts by examining their effectiveness and efficiency in contributing to reasoning through automatic long CoT chunking and Monte Carlo rollouts. Building upon the insights, we propose a theoretically bounded metric to jointly measure the effectiveness and efficiency of different thoughts. We then propose Long$\otimes$Short, an efficient reasoning framework that enables two LLMs to collaboratively solve the problem: a long-thought LLM for more effectively generating important thoughts, while a short-thought LLM for efficiently generating remaining thoughts. Specifically, we begin by synthesizing a small amount of cold-start data to fine-tune LLMs for long-thought and short-thought reasoning styles, respectively. Furthermore, we propose a synergizing-oriented multi-turn reinforcement learning, focusing on the model self-evolution and collaboration between long-thought and short-thought LLMs. Experimental results show that our method enables Qwen2.5-7B and Llama3.1-8B to achieve comparable performance compared to DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B, while reducing token length by over 80% across the MATH500, AIME24/25, AMC23, and GPQA Diamond benchmarks. Our data and code are available at https://github.com/yasNing/Long-otimes-Short/.
AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Apr 30, 2025



Recently, long-thought reasoning models achieve strong performance on complex reasoning tasks, but often incur substantial inference overhead, making efficiency a critical concern. Our empirical analysis reveals that the benefit of using Long-CoT varies across problems: while some problems require elaborate reasoning, others show no improvement, or even degraded accuracy. This motivates adaptive reasoning strategies that tailor reasoning depth to the input. However, prior work primarily reduces redundancy within long reasoning paths, limiting exploration of more efficient strategies beyond the Long-CoT paradigm. To address this, we propose a novel two-stage framework for adaptive and efficient reasoning. First, we construct a hybrid reasoning model by merging long and short CoT models to enable diverse reasoning styles. Second, we apply bi-level preference training to guide the model to select suitable reasoning styles (group-level), and prefer concise and correct reasoning within each style group (instance-level). Experiments demonstrate that our method significantly reduces inference costs compared to other baseline approaches, while maintaining performance. Notably, on five mathematical datasets, the average length of reasoning is reduced by more than 50%, highlighting the potential of adaptive strategies to optimize reasoning efficiency in large language models. Our code is coming soon at https://github.com/StarDewXXX/AdaR1
Bag of Tricks for Inference-time Computation of LLM Reasoning
Feb 12, 2025
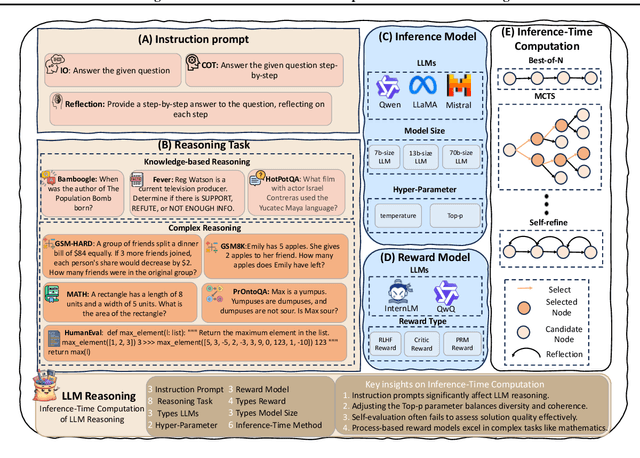
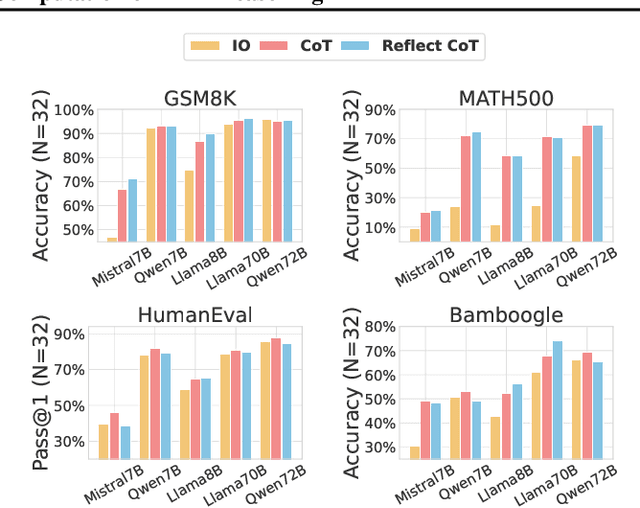
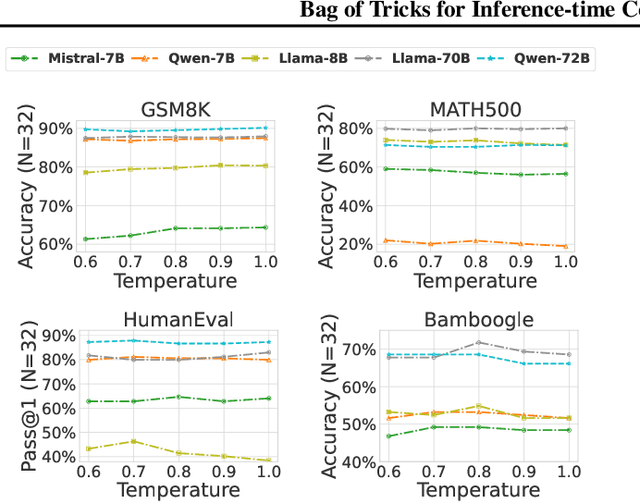
With the advancement of large language models (LLMs), solving complex reasoning tasks has gained increasing attention. Inference-time computation methods (e.g., Best-of-N, beam search, et al.) are particularly valuable as they can enhance reasoning performance without modifying model parameters or requiring additional training. However, these techniques come with implementation challenges, and most existing methods remain at the proof-of-concept stage with limited practical adoption due to their computational complexity and varying effectiveness across different tasks. In this paper, we investigate and benchmark diverse inference-time computation strategies across reasoning tasks of varying complexity. Since most current methods rely on a proposer-verifier pipeline that first generates candidate solutions (e.g., reasoning solutions) and then selects the best one based on reward signals (e.g., RLHF rewards, process rewards), our research focuses on optimizing both candidate solution generation (e.g., instructing prompts, hyperparameters such as temperature and top-p) and reward mechanisms (e.g., self-evaluation, reward types). Through extensive experiments (more than 20,000 A100-80G GPU hours with over 1,000 experiments) across a variety of models (e.g., Llama, Qwen, and Mistral families) of various sizes, our ablation studies reveal that previously overlooked strategies can significantly enhance performance (e.g., tuning temperature can improve reasoning task performance by up to 5%). Furthermore, we establish a standardized benchmark for inference-time computation by systematically evaluating six representative methods across eight reasoning tasks. These findings provide a stronger foundation for future research. The code is available at https://github.com/usail-hkust/benchmark_inference_time_computation_LL