 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Inference-time Computation of LLM Reasoning
Feb 12, 2025
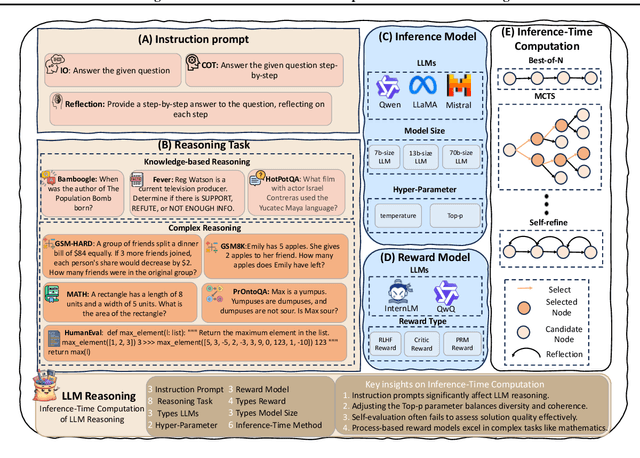
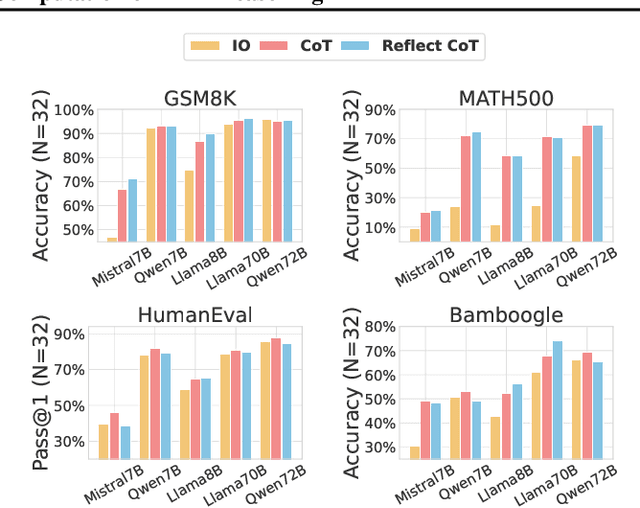
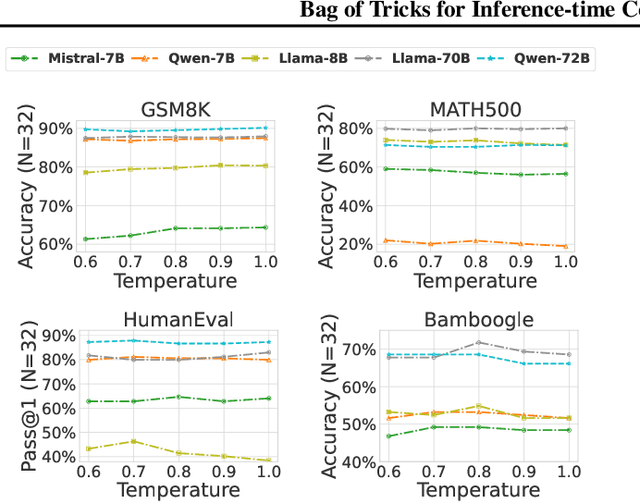
With the advancement of large language models (LLMs), solving complex reasoning tasks has gained increasing attention. Inference-time computation methods (e.g., Best-of-N, beam search, et al.) are particularly valuable as they can enhance reasoning performance without modifying model parameters or requiring additional training. However, these techniques come with implementation challenges, and most existing methods remain at the proof-of-concept stage with limited practical adoption due to their computational complexity and varying effectiveness across different tasks. In this paper, we investigate and benchmark diverse inference-time computation strategies across reasoning tasks of varying complexity. Since most current methods rely on a proposer-verifier pipeline that first generates candidate solutions (e.g., reasoning solutions) and then selects the best one based on reward signals (e.g., RLHF rewards, process rewards), our research focuses on optimizing both candidate solution generation (e.g., instructing prompts, hyperparameters such as temperature and top-p) and reward mechanisms (e.g., self-evaluation, reward types). Through extensive experiments (more than 20,000 A100-80G GPU hours with over 1,000 experiments) across a variety of models (e.g., Llama, Qwen, and Mistral families) of various sizes, our ablation studies reveal that previously overlooked strategies can significantly enhance performance (e.g., tuning temperature can improve reasoning task performance by up to 5%). Furthermore, we establish a standardized benchmark for inference-time computation by systematically evaluating six representative methods across eight reasoning tasks. These findings provide a stronger foundation for future research. The code is available at https://github.com/usail-hkust/benchmark_inference_time_computation_LL
Large Language Model Enhanced Hard Sample Identification for Denoising Recommendation
Sep 16, 2024
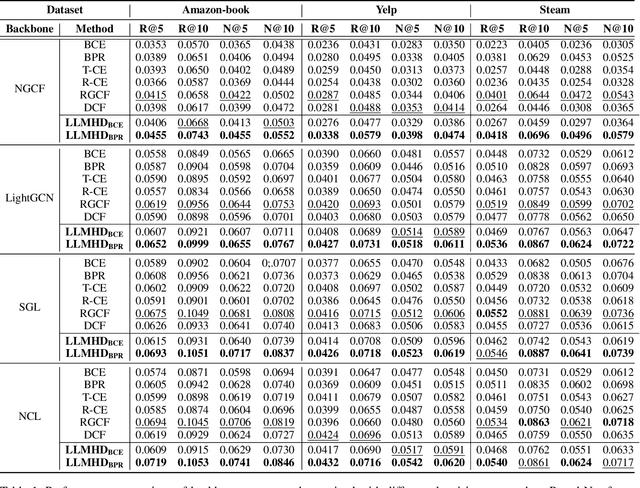


Implicit feedback, often used to build recommender systems, unavoidably confronts noise due to factors such as misclicks and position bias. Previous studies have attempted to alleviate this by identifying noisy samples based on their diverged patterns, such as higher loss values, and mitigating the noise through sample dropping or reweighting. Despite the progress, we observe existing approaches struggle to distinguish hard samples and noise samples, as they often exhibit similar patterns, thereby limiting their effectiveness in denoising recommendations. To address this challenge, we propose a Large Language Model Enhanced Hard Sample Denoising (LLMHD) framework. Specifically, we construct an LLM-based scorer to evaluate the semantic consistency of items with the user preference, which is quantified based on summarized historical user interactions. The resulting scores are used to assess the hardness of samples for the pointwise or pairwise training objectives. To ensure efficiency, we introduce a variance-based sample pruning strategy to filter potential hard samples before scoring. Besides, we propose an iterative preference update module designed to continuously refine summarized user preference, which may be biased due to false-positive user-item interactions. Extensive experiments on three real-world datasets and four backbone recommenders demonstrate the effectiveness of our approach.
Make Large Language Model a Better Ranker
Mar 28, 2024



The evolution of Large Language Models (LLMs) has significantly enhanced capabilities across various fields, leading to a paradigm shift in how Recommender Systems (RSs) are conceptualized and developed. However, existing research primarily focuses on point-wise and pair-wise recommendation paradigms. These approaches prove inefficient in LLM-based recommenders due to the high computational cost of utilizing Large Language Models. While some studies have delved into list-wise approaches, they fall short in ranking tasks. This shortfall is attributed to the misalignment between the objectives of ranking and language generation. To this end, this paper introduces the Language Model Framework with Aligned Listwise Ranking Objectives (ALRO). ALRO is designed to bridge the gap between the capabilities of LLMs and the nuanced requirements of ranking tasks within recommender systems. A key feature of ALRO is the introduction of soft lambda loss, an adaptation of lambda loss tailored to suit language generation tasks. Additionally, ALRO incorporates a permutation-sensitive learning mechanism that addresses position bias, a prevalent issue in generative models, without imposing additional computational burdens during inference. Our evaluative studies reveal that ALRO outperforms existing embedding-based recommendation methods and the existing LLM-based recommendation baselines, highlighting its efficacy.
Harnessing Large Language Models for Text-Rich Sequential Recommendation
Mar 20, 2024Recent advances in Large Language Models (LLMs) have been changing the paradigm of Recommender Systems (RS). However, when items in the recommendation scenarios contain rich textual information, such as product descriptions in online shopping or news headlines on social media, LLMs require longer texts to comprehensively depict the historical user behavior sequence. This poses significant challenges to LLM-based recommenders, such as over-length limitations, extensive time and space overheads, and suboptimal model performance. To this end, in this paper, we design a novel framework for harnessing Large Language Models for Text-Rich Sequential Recommendation (LLM-TRSR). Specifically, we first propose to segment the user historical behaviors and subsequently employ an LLM-based summarizer for summarizing these user behavior blocks. Particularly, drawing inspiration from the successful application of Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) models in user modeling, we introduce two unique summarization techniques in this paper, respectively hierarchical summarization and recurrent summarization. Then, we construct a prompt text encompassing the user preference summary, recent user interactions, and candidate item information into an LLM-based recommender, which is subsequently fine-tuned using Supervised Fine-Tuning (SFT) techniques to yield our final recommendation model. We also use Low-Rank Adaptation (LoRA) for Parameter-Efficient Fine-Tuning (PEFT). We conduct experiments on two public datasets, and the results clearly demonstrate the effectiveness of our approach.
A Cross-View Hierarchical Graph Learning Hypernetwork for Skill Demand-Supply Joint Prediction
Jan 31, 2024


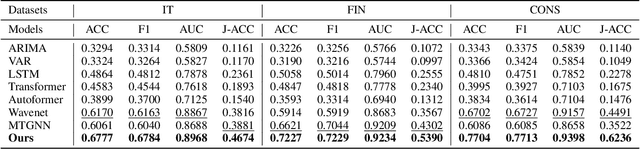
The rapidly changing landscape of technology and industries leads to dynamic skill requirements, making it crucial for employees and employers to anticipate such shifts to maintain a competitive edge in the labor market. Existing efforts in this area either rely on domain-expert knowledge or regarding skill evolution as a simplified time series forecasting problem. However, both approaches overlook the sophisticated relationships among different skills and the inner-connection between skill demand and supply variations. In this paper, we propose a Cross-view Hierarchical Graph learning Hypernetwork (CHGH) framework for joint skill demand-supply prediction. Specifically, CHGH is an encoder-decoder network consisting of i) a cross-view graph encoder to capture the interconnection between skill demand and supply, ii) a hierarchical graph encoder to model the co-evolution of skills from a cluster-wise perspective, and iii) a conditional hyper-decoder to jointly predict demand and supply variations by incorporating historical demand-supply gaps. Extensive experiments on three real-world datasets demonstrate the superiority of the proposed framework compared to seven baselines and the effectiveness of the three modules.