 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard vs. Noise: Resolving Hard-Noisy Sample Confusion in Recommender Systems via Large Language Models
Nov 11, 2025Implicit feedback, employed in training recommender systems, unavoidably confronts noise due to factors such as misclicks and position bias. Previous studies have attempted to identify noisy samples through their diverged data patterns, such as higher loss values, and mitigate their influence through sample dropping or reweighting. However, we observed that noisy samples and hard samples display similar patterns, leading to hard-noisy confusion issue. Such confusion is problematic as hard samples are vital for modeling user preferences. To solve this problem, we propose LLMHNI framework, leveraging two auxiliary user-item relevance signals generated by Large Language Models (LLMs) to differentiate hard and noisy samples. LLMHNI obtains user-item semantic relevance from LLM-encoded embeddings, which is used in negative sampling to select hard negatives while filtering out noisy false negatives. An objective alignment strategy is proposed to project LLM-encoded embeddings, originally for general language tasks, into a representation space optimized for user-item relevance modeling. LLMHNI also exploits LLM-inferred logical relevance within user-item interactions to identify hard and noisy samples. These LLM-inferred interactions are integrated into the interaction graph and guide denoising with cross-graph contrastive alignment. To eliminate the impact of unreliable interactions induced by LLM hallucination, we propose a graph contrastive learning strategy that aligns representations from randomly edge-dropped views to suppress unreliable edges. Empirical results demonstrate that LLMHNI significantly improves denoising and recommendation performance.
MM-Agent: LLM as Agents for Real-world Mathematical Modeling Problem
May 20, 2025Mathematical modeling is a cornerstone of scientific discovery and engineering practice, enabling the translation of real-world problems into formal systems across domains such as physics, biology, and economics. Unlike mathematical reasoning, which assumes a predefined formulation, modeling requires open-ended problem analysis, abstraction, and principled formalization. While Large Language Models (LLMs) have shown strong reasoning capabilities, they fall short in rigorous model construction, limiting their utility in real-world problem-solving. To this end, we formalize the task of LLM-powered real-world mathematical modeling, where agents must analyze problems, construct domain-appropriate formulations, and generate complete end-to-end solutions. We introduce MM-Bench, a curated benchmark of 111 problems from the Mathematical Contest in Modeling (MCM/ICM), spanning the years 2000 to 2025 and across ten diverse domains such as physics, biology, and economics. To tackle this task, we propose MM-Agent, an expert-inspired framework that decomposes mathematical modeling into four stages: open-ended problem analysis, structured model formulation, computational problem solving, and report generation. Experiments on MM-Bench show that MM-Agent significantly outperforms baseline agents, achieving an 11.88\% improvement over human expert solutions while requiring only 15 minutes and \$0.88 per task using GPT-4o. Furthermore, under official MCM/ICM protocols, MM-Agent assisted two undergraduate teams in winning the Finalist Award (\textbf{top 2.0\% among 27,456 teams}) in MCM/ICM 2025, demonstrating its practical effectiveness as a modeling copilot. Our code is available at https://github.com/usail-hkust/LLM-MM-Agent
Large Language Model Enhanced Hard Sample Identification for Denoising Recommendation
Sep 16, 2024
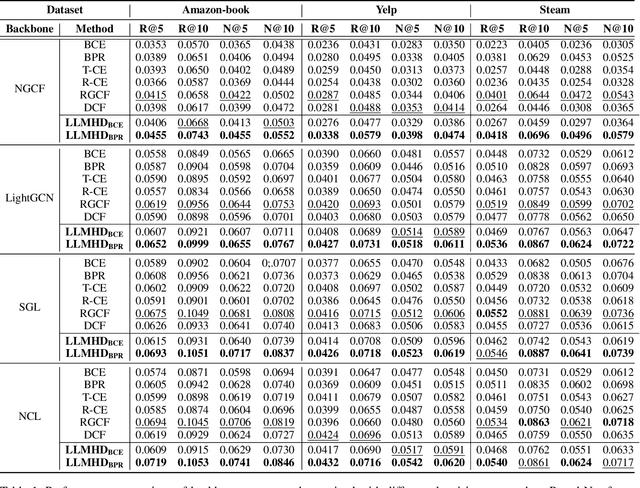


Implicit feedback, often used to build recommender systems, unavoidably confronts noise due to factors such as misclicks and position bias. Previous studies have attempted to alleviate this by identifying noisy samples based on their diverged patterns, such as higher loss values, and mitigating the noise through sample dropping or reweighting. Despite the progress, we observe existing approaches struggle to distinguish hard samples and noise samples, as they often exhibit similar patterns, thereby limiting their effectiveness in denoising recommendations. To address this challenge, we propose a Large Language Model Enhanced Hard Sample Denoising (LLMHD) framework. Specifically, we construct an LLM-based scorer to evaluate the semantic consistency of items with the user preference, which is quantified based on summarized historical user interactions. The resulting scores are used to assess the hardness of samples for the pointwise or pairwise training objectives. To ensure efficiency, we introduce a variance-based sample pruning strategy to filter potential hard samples before scoring. Besides, we propose an iterative preference update module designed to continuously refine summarized user preference, which may be biased due to false-positive user-item interactions. Extensive experiments on three real-world datasets and four backbone recommenders demonstrate the effectiveness of our approach.