 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoCurate:Modeling Interaction Topology for Tool-Use Agent Training
Mar 02, 2026Training tool-use agents typically relies on outcome-based filtering: Supervised Fine-Tuning (SFT) on successful trajectories and Reinforcement Learning (RL) on pass-rate-selected tasks. However, this paradigm ignores interaction dynamics: successful trajectories may lack error recovery or exhibit redundancy, while pass rates fail to distinguish structurally informative tasks from trivial ones. We propose \textbf{TopoCurate}, an interaction-aware framework that projects multi-trial rollouts from the same task into a unified semantic quotient topology. By merging equivalent action-observation states, this projection transforms scattered linear trajectories into a structured manifold that explicitly captures how tool invocations and environmental responses drive the divergence between effective strategies and failure modes. Leveraging this representation, we introduce a dual-selection mechanism: for SFT, we prioritize trajectories demonstrating reflective recovery, semantic efficiency, and strategic diversity to mitigate covariate shift and mode collapse; for RL, we select tasks with high error branch ratios and strategic heterogeneity, maximizing gradient Signal-to-Noise Ratio to address vanishing signals in sparse-reward settings. Evaluations on BFCLv3 and Tau2 Bench show that TopoCurate achieves consistent gains of 4.2\% (SFT) and 6.9\% (RL) over state-of-the-art baselines. We will release the code and data soon for further investigations.
ExpertWeaver: Unlocking the Inherent MoE in Dense LLMs with GLU Activation Patterns
Feb 17, 2026Mixture-of-Experts (MoE) effectively scales model capacity while preserving computational efficiency through sparse expert activation. However, training high-quality MoEs from scratch is prohibitively expensive. A promising alternative is to convert pretrained dense models into sparse MoEs. Existing dense-to-MoE methods fall into two categories: \textbf{dynamic structural pruning} that converts dense models into MoE architectures with moderate sparsity to balance performance and inference efficiency, and \textbf{downcycling} approaches that use pretrained dense models to initialize highly sparse MoE architectures. However, existing methods break the intrinsic activation patterns within dense models, leading to suboptimal expert construction. In this work, we argue that the Gated Linear Unit (GLU) mechanism provides a natural blueprint for dense-to-MoE conversion. We show that the fine-grained neural-wise activation patterns of GLU reveal a coarse-grained structure, uncovering an inherent MoE architecture composed of consistently activated universal neurons and dynamically activated specialized neurons. Leveraging this discovery, we introduce ExpertWeaver, a training-free framework that partitions neurons according to their activation patterns and constructs shared experts and specialized routed experts with layer-adaptive configurations. Our experiments demonstrate that ExpertWeaver significantly outperforms existing methods, both as a training-free dynamic structural pruning technique and as a downcycling strategy for superior MoE initialization.
SIGHT: Reinforcement Learning with Self-Evidence and Information-Gain Diverse Branching for Search Agent
Feb 12, 2026Reinforcement Learning (RL) has empowered Large Language Models (LLMs) to master autonomous search for complex question answering. However, particularly within multi-turn search scenarios, this interaction introduces a critical challenge: search results often suffer from high redundancy and low signal-to-noise ratios. Consequently, agents easily fall into "Tunnel Vision," where the forced interpretation of early noisy retrievals leads to irreversible error accumulation. To address these challenges, we propose SIGHT, a framework that enhances search-based reasoning through Self-Evidence Support (SES) and Information-Gain Driven Diverse Branching. SIGHT distills search results into high-fidelity evidence via SES and calculates an Information Gain score to pinpoint pivotal states where observations maximally reduce uncertainty. This score guides Dynamic Prompting Interventions - including de-duplication, reflection, or adaptive branching - to spawn new branches with SES. Finally, by integrating SES and correctness rewards via Group Relative Policy Optimization, SIGHT internalizes robust exploration strategies without external verifiers. Experiments on single-hop and multi-hop QA benchmarks demonstrate that SIGHT significantly outperforms existing approaches, particularly in complex reasoning scenarios, using fewer search steps.
Pushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
Jan 30, 2026Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
LRAS: Advanced Legal Reasoning with Agentic Search
Jan 12, 2026While Large Reasoning Models (LRMs) have demonstrated exceptional logical capabilities in mathematical domains, their application to the legal field remains hindered by the strict requirements for procedural rigor and adherence to legal logic. Existing legal LLMs, which rely on "closed-loop reasoning" derived solely from internal parametric knowledge, frequently suffer from lack of self-awareness regarding their knowledge boundaries, leading to confident yet incorrect conclusions. To address this challenge, we present Legal Reasoning with Agentic Search (LRAS), the first framework designed to transition legal LLMs from static and parametric "closed-loop thinking" to dynamic and interactive "Active Inquiry". By integrating Introspective Imitation Learning and Difficulty-aware Reinforcement Learning, LRAS enables LRMs to identify knowledge boundaries and handle legal reasoning complexity. Empirical results demonstrate that LRAS outperforms state-of-the-art baselines by 8.2-32\%, with the most substantial gains observed in tasks requiring deep reasoning with reliable knowledge. We will release our data and models for further exploration soon.
Noise Projection: Closing the Prompt-Agnostic Gap Behind Text-to-Image Misalignment in Diffusion Models
Oct 16, 2025In text-to-image generation, different initial noises induce distinct denoising paths with a pretrained Stable Diffusion (SD) model. While this pattern could output diverse images, some of them may fail to align well with the prompt. Existing methods alleviate this issue either by altering the denoising dynamics or by drawing multiple noises and conducting post-selection. In this paper, we attribute the misalignment to a training-inference mismatch: during training, prompt-conditioned noises lie in a prompt-specific subset of the latent space, whereas at inference the noise is drawn from a prompt-agnostic Gaussian prior. To close this gap, we propose a noise projector that applies text-conditioned refinement to the initial noise before denoising. Conditioned on the prompt embedding, it maps the noise to a prompt-aware counterpart that better matches the distribution observed during SD training, without modifying the SD model. Our framework consists of these steps: we first sample some noises and obtain token-level feedback for their corresponding images from a vision-language model (VLM), then distill these signals into a reward model, and finally optimize the noise projector via a quasi-direct preference optimization. Our design has two benefits: (i) it requires no reference images or handcrafted priors, and (ii) it incurs small inference cost, replacing multi-sample selection with a single forward pass. Extensive experiments further show that our prompt-aware noise projection improves text-image alignment across diverse prompts.
AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Apr 30, 2025



Recently, long-thought reasoning models achieve strong performance on complex reasoning tasks, but often incur substantial inference overhead, making efficiency a critical concern. Our empirical analysis reveals that the benefit of using Long-CoT varies across problems: while some problems require elaborate reasoning, others show no improvement, or even degraded accuracy. This motivates adaptive reasoning strategies that tailor reasoning depth to the input. However, prior work primarily reduces redundancy within long reasoning paths, limiting exploration of more efficient strategies beyond the Long-CoT paradigm. To address this, we propose a novel two-stage framework for adaptive and efficient reasoning. First, we construct a hybrid reasoning model by merging long and short CoT models to enable diverse reasoning styles. Second, we apply bi-level preference training to guide the model to select suitable reasoning styles (group-level), and prefer concise and correct reasoning within each style group (instance-level). Experiments demonstrate that our method significantly reduces inference costs compared to other baseline approaches, while maintaining performance. Notably, on five mathematical datasets, the average length of reasoning is reduced by more than 50%, highlighting the potential of adaptive strategies to optimize reasoning efficiency in large language models. Our code is coming soon at https://github.com/StarDewXXX/AdaR1
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025
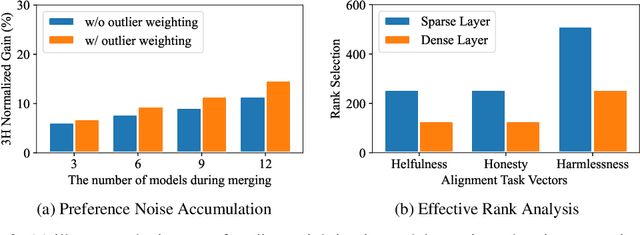

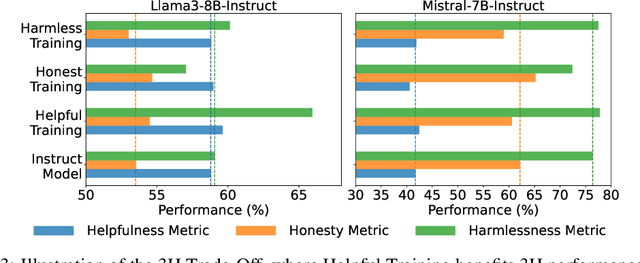
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Mitigating the Backdoor Effect for Multi-Task Model Merging via Safety-Aware Subspace
Oct 17, 2024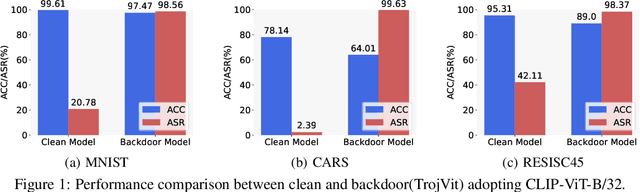
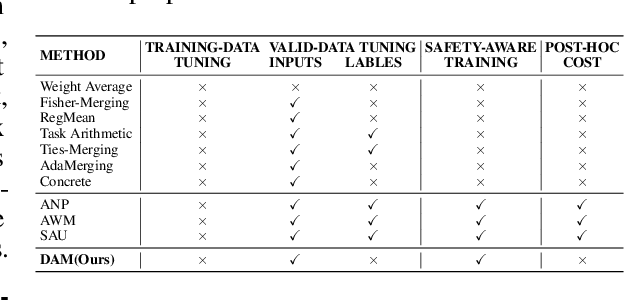
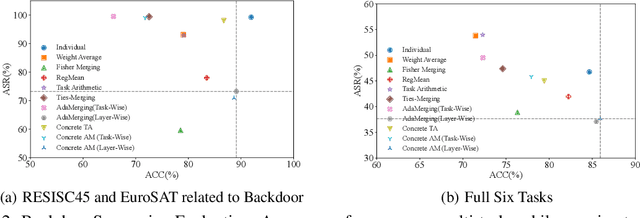
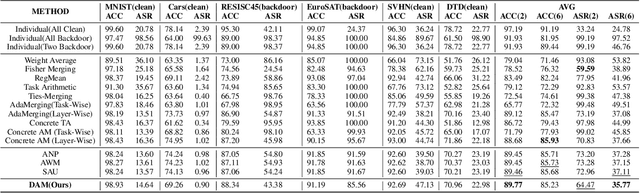
Model merging has gained significant attention as a cost-effective approach to integrate multiple single-task fine-tuned models into a unified one that can perform well on multiple tasks. However, existing model merging techniques primarily focus on resolving conflicts between task-specific models, they often overlook potential security threats, particularly the risk of backdoor attacks in the open-source model ecosystem. In this paper, we first investigate the vulnerabilities of existing model merging methods to backdoor attacks, identifying two critical challenges: backdoor succession and backdoor transfer. To address these issues, we propose a novel Defense-Aware Merging (DAM) approach that simultaneously mitigates task interference and backdoor vulnerabilities. Specifically, DAM employs a meta-learning-based optimization method with dual masks to identify a shared and safety-aware subspace for model merging. These masks are alternately optimized: the Task-Shared mask identifies common beneficial parameters across tasks, aiming to preserve task-specific knowledge while reducing interference, while the Backdoor-Detection mask isolates potentially harmful parameters to neutralize security threats. This dual-mask design allows us to carefully balance the preservation of useful knowledge and the removal of potential vulnerabilities. Compared to existing merging methods, DAM achieves a more favorable balance between performance and security, reducing the attack success rate by 2-10 percentage points while sacrificing only about 1% in accuracy. Furthermore, DAM exhibits robust performance and broad applicability across various types of backdoor attacks and the number of compromised models involved in the merging process. We will release the codes and models soon.