 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-DeepResearch: A Simple and Effective Multimodal Agentic Search Baseline
Mar 01, 2026We aim to develop a multimodal research agent capable of explicit reasoning and planning, multi-tool invocation, and cross-modal information synthesis, enabling it to conduct deep research tasks. However, we observe three main challenges in developing such agents: (1) scarcity of search-intensive multimodal QA data, (2) lack of effective search trajectories, and (3) prohibitive cost of training with online search APIs. To tackle them, we first propose Hyper-Search, a hypergraph-based QA generation method that models and connects visual and textual nodes within and across modalities, enabling to generate search-intensive multimodal QA pairs that require invoking various search tools to solve. Second, we introduce DR-TTS, which first decomposes search-involved tasks into several categories according to search tool types, and respectively optimize specialized search tool experts for each tool. It then recomposes tool experts to jointly explore search trajectories via tree search, producing trajectories that successfully solve complex tasks using various search tools. Third, we build an offline search engine supporting multiple search tools, enabling agentic reinforcement learning without using costly online search APIs. With the three designs, we develop MM-DeepResearch, a powerful multimodal deep research agent, and extensive results shows its superiority across benchmarks. Code is available at https://github.com/HJYao00/MM-DeepResearch
Atomicity for Agents: Exposing, Exploiting, and Mitigating TOCTOU Vulnerabilities in Browser-Use Agents
Feb 28, 2026Browser-use agents are widely used for everyday tasks. They enable automated interaction with web pages through structured DOM based interfaces or vision language models operating on page screenshots. However, web pages often change between planning and execution, causing agents to execute actions based on stale assumptions. We view this temporal mismatch as a time of check to time of use (TOCTOU) vulnerability in browser-use agents. Dynamic or adversarial web content can exploit this window to induce unintended actions. We present a large scale empirical study of TOCTOU vulnerabilities in browser-use agents using a benchmark that spans synthesized and real world websites. Using this benchmark, we evaluate 10 popular open source agents and show that TOCTOU vulnerabilities are widespread. We design a lightweight mitigation based on pre-execution validation. It monitors DOM and layout changes during planning and validates the page state immediately before action execution. This approach reduces the risk of insecure execution and mitigates unintended side effects in browser-use agents.
Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System
Feb 09, 2026Integrating Large Language Models (LLMs) with external tools via multi-agent systems offers a promising new paradigm for decomposing and solving complex problems. However, training these systems remains notoriously difficult due to the credit assignment challenge, as it is often unclear which specific functional agent is responsible for the success or failure of decision trajectories. Existing methods typically rely on sparse or globally broadcast rewards, failing to capture individual contributions and leading to inefficient reinforcement learning. To address these limitations, we introduce the Shapley-based Hierarchical Attribution for Reinforcement Policy (SHARP), a novel framework for optimizing multi-agent reinforcement learning via precise credit attribution. SHARP effectively stabilizes training by normalizing agent-specific advantages across trajectory groups, primarily through a decomposed reward mechanism comprising a global broadcast-accuracy reward, a Shapley-based marginal-credit reward for each agent, and a tool-process reward to improve execution efficiency. Extensive experiments across various real-world benchmarks demonstrate that SHARP significantly outperforms recent state-of-the-art baselines, achieving average match improvements of 23.66% and 14.05% over single-agent and multi-agent approaches, respectively.
Darwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
Language-based Trial and Error Falls Behind in the Era of Experience
Jan 29, 2026While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Apr 30, 2025



Recently, long-thought reasoning models achieve strong performance on complex reasoning tasks, but often incur substantial inference overhead, making efficiency a critical concern. Our empirical analysis reveals that the benefit of using Long-CoT varies across problems: while some problems require elaborate reasoning, others show no improvement, or even degraded accuracy. This motivates adaptive reasoning strategies that tailor reasoning depth to the input. However, prior work primarily reduces redundancy within long reasoning paths, limiting exploration of more efficient strategies beyond the Long-CoT paradigm. To address this, we propose a novel two-stage framework for adaptive and efficient reasoning. First, we construct a hybrid reasoning model by merging long and short CoT models to enable diverse reasoning styles. Second, we apply bi-level preference training to guide the model to select suitable reasoning styles (group-level), and prefer concise and correct reasoning within each style group (instance-level). Experiments demonstrate that our method significantly reduces inference costs compared to other baseline approaches, while maintaining performance. Notably, on five mathematical datasets, the average length of reasoning is reduced by more than 50%, highlighting the potential of adaptive strategies to optimize reasoning efficiency in large language models. Our code is coming soon at https://github.com/StarDewXXX/AdaR1
Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation
Jan 30, 2025



Harmful fine-tuning attack introduces significant security risks to the fine-tuning services. Mainstream defenses aim to vaccinate the model such that the later harmful fine-tuning attack is less effective. However, our evaluation results show that such defenses are fragile -- with a few fine-tuning steps, the model still can learn the harmful knowledge. To this end, we do further experiment and find that an embarrassingly simple solution -- adding purely random perturbations to the fine-tuned model, can recover the model from harmful behavior, though it leads to a degradation in the model's fine-tuning performance. To address the degradation of fine-tuning performance, we further propose Panacea, which optimizes an adaptive perturbation that will be applied to the model after fine-tuning. Panacea maintains model's safety alignment performance without compromising downstream fine-tuning performance. Comprehensive experiments are conducted on different harmful ratios, fine-tuning tasks and mainstream LLMs, where the average harmful scores are reduced by up-to 21.5%, while maintaining fine-tuning performance. As a by-product, we analyze the optimized perturbation and show that different layers in various LLMs have distinct safety coefficients. Source code available at https://github.com/w-yibo/Panacea
Latent Distance Guided Alignment Training for Large Language Models
Apr 13, 2024Ensuring alignment with human preferences is a crucial characteristic of large language models (LLMs). Presently, the primary alignment methods, RLHF and DPO, require extensive human annotation, which is expensive despite their efficacy. The significant expenses associated with current alignment techniques motivate researchers to investigate the development of annotation-free alignment training methods. In pursuit of improved alignment without relying on external annotation, we introduce Latent Distance Guided Alignment Training (LD-Align). This approach seeks to align the model with a high-quality supervised fine-tune dataset using guidance from a latent space. The latent space is generated through sample reconstruction, akin to auto-encoding. Consequently, we utilize the distance between sample pairs in the latent space to guide DPO-based alignment training. Extensive experimentation and evaluation show the efficacy of our proposed method in achieving notable alignment.
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Apr 08, 2024Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
Vector-Quantized Prompt Learning for Paraphrase Generation
Nov 25, 2023

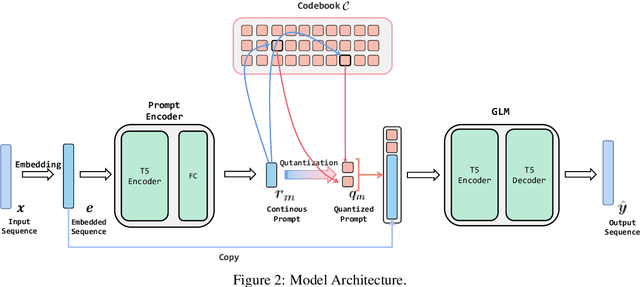

Deep generative modeling of natural languages has achieved many successes, such as producing fluent sentences and translating from one language into another. However, the development of generative modeling techniques for paraphrase generation still lags behind largely due to the challenges in addressing the complex conflicts between expression diversity and semantic preservation. This paper proposes to generate diverse and high-quality paraphrases by exploiting the pre-trained models with instance-dependent prompts. To learn generalizable prompts, we assume that the number of abstract transforming patterns of paraphrase generation (governed by prompts) is finite and usually not large. Therefore, we present vector-quantized prompts as the cues to control the generation of pre-trained models. Extensive experiments demonstrate that the proposed method achieves new state-of-art results on three benchmark datasets, including Quora, Wikianswers, and MSCOCO. We will release all the code upon acceptance.