 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixAR: Mixture Autoregressive Image Generation
Nov 15, 2025Autoregressive (AR) approaches, which represent images as sequences of discrete tokens from a finite codebook, have achieved remarkable success in image generation. However, the quantization process and the limited codebook size inevitably discard fine-grained information, placing bottlenecks on fidelity. Motivated by this limitation, recent studies have explored autoregressive modeling in continuous latent spaces, which offers higher generation quality. Yet, unlike discrete tokens constrained by a fixed codebook, continuous representations lie in a vast and unstructured space, posing significant challenges for efficient autoregressive modeling. To address these challenges, we introduce MixAR, a novel framework that leverages mixture training paradigms to inject discrete tokens as prior guidance for continuous AR modeling. MixAR is a factorized formulation that leverages discrete tokens as prior guidance for continuous autoregressive prediction. We investigate several discrete-continuous mixture strategies, including self-attention (DC-SA), cross-attention (DC-CA), and a simple approach (DC-Mix) that replaces homogeneous mask tokens with informative discrete counterparts. Moreover, to bridge the gap between ground-truth training tokens and inference tokens produced by the pre-trained AR model, we propose Training-Inference Mixture (TI-Mix) to achieve consistent training and generation distributions. In our experiments, we demonstrate a favorable balance of the DC-Mix strategy between computational efficiency and generation fidelity, and consistent improvement of TI-Mix.
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
Oct 25, 2023
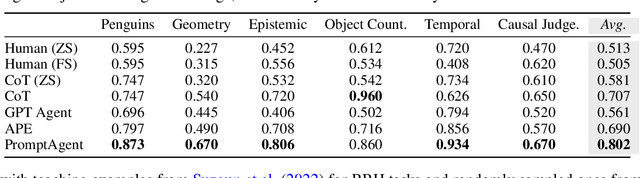
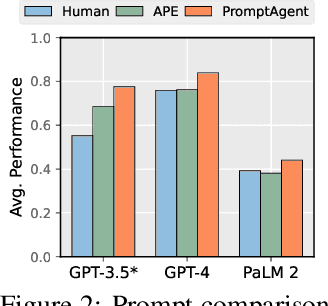
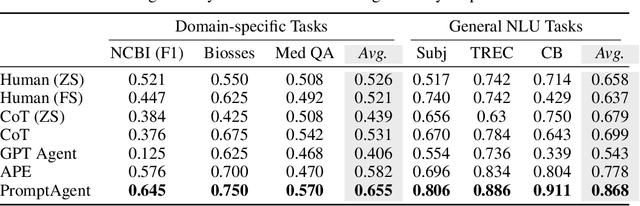
Highly effective, task-specific prompts are often heavily engineered by experts to integrate detailed instructions and domain insights based on a deep understanding of both instincts of large language models (LLMs) and the intricacies of the target task. However, automating the generation of such expert-level prompts remains elusive. Existing prompt optimization methods tend to overlook the depth of domain knowledge and struggle to efficiently explore the vast space of expert-level prompts. Addressing this, we present PromptAgent, an optimization method that autonomously crafts prompts equivalent in quality to those handcrafted by experts. At its core, PromptAgent views prompt optimization as a strategic planning problem and employs a principled planning algorithm, rooted in Monte Carlo tree search, to strategically navigate the expert-level prompt space. Inspired by human-like trial-and-error exploration, PromptAgent induces precise expert-level insights and in-depth instructions by reflecting on model errors and generating constructive error feedback. Such a novel framework allows the agent to iteratively examine intermediate prompts (states), refine them based on error feedbacks (actions), simulate future rewards, and search for high-reward paths leading to expert prompts. We apply PromptAgent to 12 tasks spanning three practical domains: BIG-Bench Hard (BBH), as well as domain-specific and general NLP tasks, showing it significantly outperforms strong Chain-of-Thought and recent prompt optimization baselines. Extensive analyses emphasize its capability to craft expert-level, detailed, and domain-insightful prompts with great efficiency and generalizability.
GraphPrompt: Biomedical Entity Normalization Using Graph-based Prompt Templates
Nov 13, 2021



Biomedical entity normalization unifies the language across biomedical experiments and studies, and further enables us to obtain a holistic view of life sciences. Current approaches mainly study the normalization of more standardized entities such as diseases and drugs, while disregarding the more ambiguous but crucial entities such as pathways, functions and cell types, hindering their real-world applications. To achieve biomedical entity normalization on these under-explored entities, we first introduce an expert-curated dataset OBO-syn encompassing 70 different types of entities and 2 million curated entity-synonym pairs. To utilize the unique graph structure in this dataset, we propose GraphPrompt, a prompt-based learning approach that creates prompt templates according to the graphs. GraphPrompt obtained 41.0% and 29.9% improvement on zero-shot and few-shot settings respectively, indicating the effectiveness of these graph-based prompt templates. We envision that our method GraphPrompt and OBO-syn dataset can be broadly applied to graph-based NLP tasks, and serve as the basis for analyzing diverse and accumulating biomedical data.