 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePred&Guide: Labeled Target Class Prediction for Guiding Semi-Supervised Domain Adaptation
Nov 22, 2022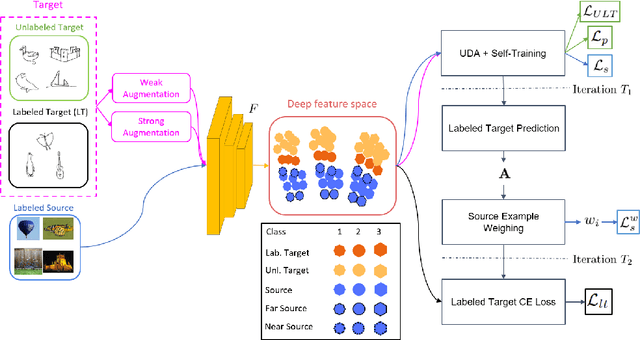
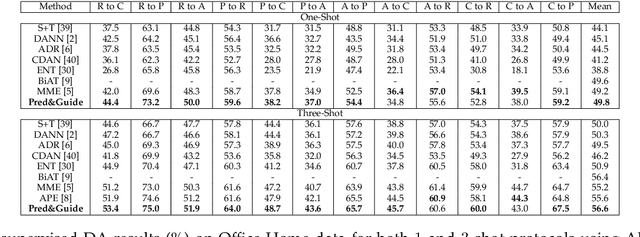
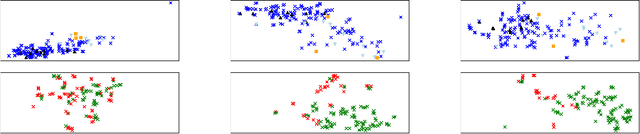

Semi-supervised domain adaptation aims to classify data belonging to a target domain by utilizing a related label-rich source domain and very few labeled examples of the target domain. Here, we propose a novel framework, Pred&Guide, which leverages the inconsistency between the predicted and the actual class labels of the few labeled target examples to effectively guide the domain adaptation in a semi-supervised setting. Pred&Guide consists of three stages, as follows (1) First, in order to treat all the target samples equally, we perform unsupervised domain adaptation coupled with self-training; (2) Second is the label prediction stage, where the current model is used to predict the labels of the few labeled target examples, and (3) Finally, the correctness of the label predictions are used to effectively weigh source examples class-wise to better guide the domain adaptation process. Extensive experiments show that the proposed Pred&Guide framework achieves state-of-the-art results for two large-scale benchmark datasets, namely Office-Home and DomainNet.
GraphPrompt: Biomedical Entity Normalization Using Graph-based Prompt Templates
Nov 13, 2021



Biomedical entity normalization unifies the language across biomedical experiments and studies, and further enables us to obtain a holistic view of life sciences. Current approaches mainly study the normalization of more standardized entities such as diseases and drugs, while disregarding the more ambiguous but crucial entities such as pathways, functions and cell types, hindering their real-world applications. To achieve biomedical entity normalization on these under-explored entities, we first introduce an expert-curated dataset OBO-syn encompassing 70 different types of entities and 2 million curated entity-synonym pairs. To utilize the unique graph structure in this dataset, we propose GraphPrompt, a prompt-based learning approach that creates prompt templates according to the graphs. GraphPrompt obtained 41.0% and 29.9% improvement on zero-shot and few-shot settings respectively, indicating the effectiveness of these graph-based prompt templates. We envision that our method GraphPrompt and OBO-syn dataset can be broadly applied to graph-based NLP tasks, and serve as the basis for analyzing diverse and accumulating biomedical data.