 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Advance of Making Language Models Better Reasoners
Jun 07, 2022
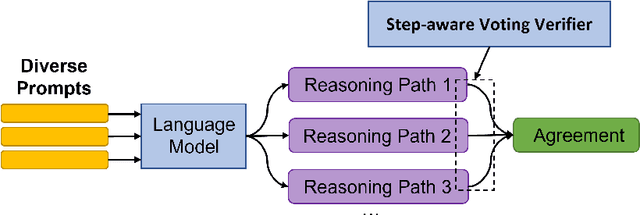
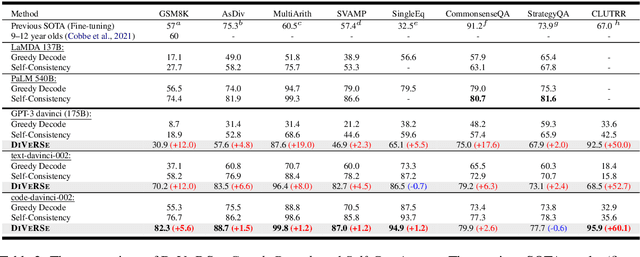

Large language models such as GPT-3 and PaLM have shown remarkable performance in few-shot learning. However, they still struggle with reasoning tasks such as the arithmetic benchmark GSM8K. Recent advances deliberately guide the language model to generate a chain of reasoning steps before producing the final answer, successfully boosting the GSM8K benchmark from 17.9% to 58.1% in terms of problem solving rate. In this paper, we propose a new approach, DiVeRSe (Diverse Verifier on Reasoning Step), to further advance their reasoning capability. DiVeRSe first explores different prompts to enhance the diversity in reasoning paths. Second, DiVeRSe introduces a verifier to distinguish good answers from bad answers for a better weighted voting. Finally, DiVeRSe verifies the correctness of each single step rather than all the steps in a whole. We conduct extensive experiments using the latest language model code-davinci-002 and demonstrate that DiVeRSe can achieve new state-of-the-art performance on six out of eight reasoning benchmarks (e.g., GSM8K 74.4% to 83.2%), outperforming the PaLM model with 540B parameters.
GraphPrompt: Biomedical Entity Normalization Using Graph-based Prompt Templates
Nov 13, 2021



Biomedical entity normalization unifies the language across biomedical experiments and studies, and further enables us to obtain a holistic view of life sciences. Current approaches mainly study the normalization of more standardized entities such as diseases and drugs, while disregarding the more ambiguous but crucial entities such as pathways, functions and cell types, hindering their real-world applications. To achieve biomedical entity normalization on these under-explored entities, we first introduce an expert-curated dataset OBO-syn encompassing 70 different types of entities and 2 million curated entity-synonym pairs. To utilize the unique graph structure in this dataset, we propose GraphPrompt, a prompt-based learning approach that creates prompt templates according to the graphs. GraphPrompt obtained 41.0% and 29.9% improvement on zero-shot and few-shot settings respectively, indicating the effectiveness of these graph-based prompt templates. We envision that our method GraphPrompt and OBO-syn dataset can be broadly applied to graph-based NLP tasks, and serve as the basis for analyzing diverse and accumulating biomedical data.
Pre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021
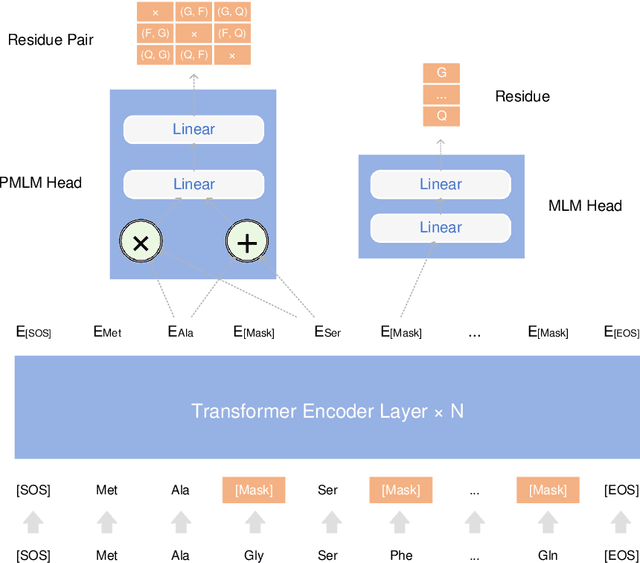
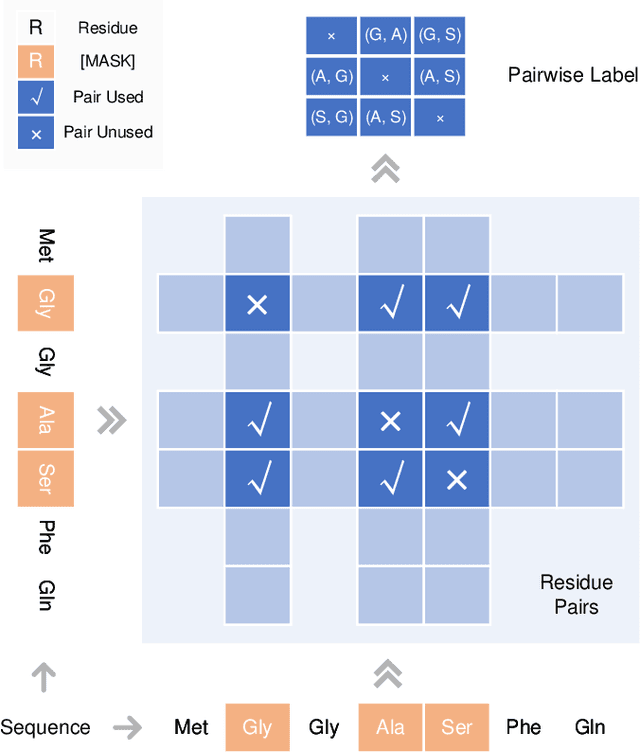

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.