 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Advance of Making Language Models Better Reasoners
Paper and Code

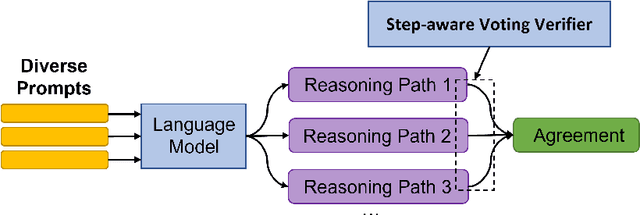
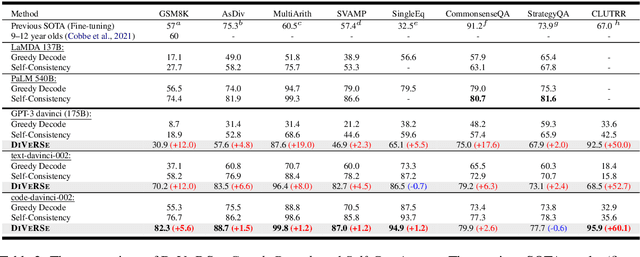

Large language models such as GPT-3 and PaLM have shown remarkable performance in few-shot learning. However, they still struggle with reasoning tasks such as the arithmetic benchmark GSM8K. Recent advances deliberately guide the language model to generate a chain of reasoning steps before producing the final answer, successfully boosting the GSM8K benchmark from 17.9% to 58.1% in terms of problem solving rate. In this paper, we propose a new approach, DiVeRSe (Diverse Verifier on Reasoning Step), to further advance their reasoning capability. DiVeRSe first explores different prompts to enhance the diversity in reasoning paths. Second, DiVeRSe introduces a verifier to distinguish good answers from bad answers for a better weighted voting. Finally, DiVeRSe verifies the correctness of each single step rather than all the steps in a whole. We conduct extensive experiments using the latest language model code-davinci-002 and demonstrate that DiVeRSe can achieve new state-of-the-art performance on six out of eight reasoning benchmarks (e.g., GSM8K 74.4% to 83.2%), outperforming the PaLM model with 540B parameters.