 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive Aware AI Regulations: A Credal Characterisation
Mar 05, 2026While high-stakes ML applications demand strict regulations, strategic ML providers often evade them to lower development costs. To address this challenge, we cast AI regulation as a mechanism design problem under uncertainty and introduce regulation mechanisms: a framework that maps empirical evidence from models to a license for some market share. The providers can select from a set of licenses, effectively forcing them to bet on their model's ability to fulfil regulation. We aim at regulation mechanisms that achieve perfect market outcome, i.e. (a) drive non-compliant providers to self-exclude, and (b) ensure participation from compliant providers. We prove that a mechanism has perfect market outcome if and only if the set of non-compliant distributions forms a credal set, i.e., a closed, convex set of probability measures. This result connects mechanism design and imprecise probability by establishing a duality between regulation mechanisms and the set of non-compliant distributions. We also demonstrate these mechanisms in practice via experiments on regulating use of spurious features for prediction and fairness. Our framework provides new insights at the intersection of mechanism design and imprecise probability, offering a foundation for development of enforceable AI regulations.
Modified TSception for Analyzing Driver Drowsiness and Mental Workload from EEG
Dec 25, 2025Driver drowsiness remains a primary cause of traffic accidents, necessitating the development of real-time, reliable detection systems to ensure road safety. This study presents a Modified TSception architecture designed for the robust assessment of driver fatigue using Electroencephalography (EEG). The model introduces a novel hierarchical architecture that surpasses the original TSception by implementing a five-layer temporal refinement strategy to capture multi-scale brain dynamics. A key innovation is the use of Adaptive Average Pooling, which provides the structural flexibility to handle varying EEG input dimensions, and a two - stage fusion mechanism that optimizes the integration of spatiotemporal features for improved stability. When evaluated on the SEED-VIG dataset and compared against established methods - including SVM, Transformer, EEGNet, ConvNeXt, LMDA-Net, and the original TSception - the Modified TSception achieves a comparable accuracy of 83.46% (vs. 83.15% for the original). Critically, the proposed model exhibits a substantially reduced confidence interval (0.24 vs. 0.36), signifying a marked improvement in performance stability. Furthermore, the architecture's generalizability is validated on the STEW mental workload dataset, where it achieves state-of-the-art results with 95.93% and 95.35% accuracy for 2-class and 3-class classification, respectively. These improvements in consistency and cross-task generalizability underscore the effectiveness of the proposed modifications for reliable EEG-based monitoring of drowsiness and mental workload.
Truthful Elicitation of Imprecise Forecasts
Mar 20, 2025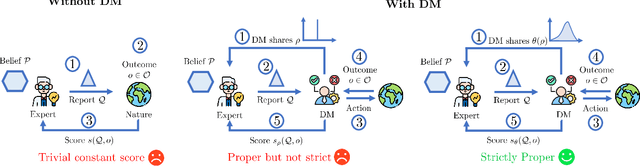
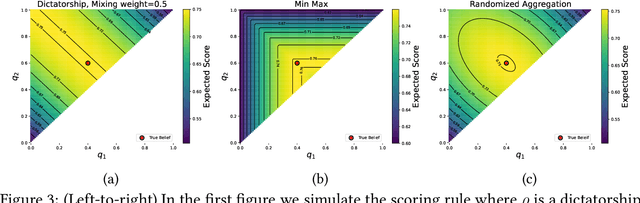
The quality of probabilistic forecasts is crucial for decision-making under uncertainty. While proper scoring rules incentivize truthful reporting of precise forecasts, they fall short when forecasters face epistemic uncertainty about their beliefs, limiting their use in safety-critical domains where decision-makers (DMs) prioritize proper uncertainty management. To address this, we propose a framework for scoring imprecise forecasts -- forecasts given as a set of beliefs. Despite existing impossibility results for deterministic scoring rules, we enable truthful elicitation by drawing connection to social choice theory and introducing a two-way communication framework where DMs first share their aggregation rules (e.g., averaging or min-max) used in downstream decisions for resolving forecast ambiguity. This, in turn, helps forecasters resolve indecision during elicitation. We further show that truthful elicitation of imprecise forecasts is achievable using proper scoring rules randomized over the aggregation procedure. Our approach allows DM to elicit and integrate the forecaster's epistemic uncertainty into their decision-making process, thus improving credibility.
Bayesian Optimization for Building Social-Influence-Free Consensus
Feb 11, 2025We introduce Social Bayesian Optimization (SBO), a vote-efficient algorithm for consensus-building in collective decision-making. In contrast to single-agent scenarios, collective decision-making encompasses group dynamics that may distort agents' preference feedback, thereby impeding their capacity to achieve a social-influence-free consensus -- the most preferable decision based on the aggregated agent utilities. We demonstrate that under mild rationality axioms, reaching social-influence-free consensus using noisy feedback alone is impossible. To address this, SBO employs a dual voting system: cheap but noisy public votes (e.g., show of hands in a meeting), and more accurate, though expensive, private votes (e.g., one-to-one interview). We model social influence using an unknown social graph and leverage the dual voting system to efficiently learn this graph. Our theoretical findigns show that social graph estimation converges faster than the black-box estimation of agents' utilities, allowing us to reduce reliance on costly private votes early in the process. This enables efficient consensus-building primarily through noisy public votes, which are debiased based on the estimated social graph to infer social-influence-free feedback. We validate the efficacy of SBO across multiple real-world applications, including thermal comfort, team building, travel negotiation, and energy trading collaboration.
Malaria Cell Detection Using Deep Neural Networks
Jun 28, 2024Malaria remains one of the most pressing public health concerns globally, causing significant morbidity and mortality, especially in sub-Saharan Africa. Rapid and accurate diagnosis is crucial for effective treatment and disease management. Traditional diagnostic methods, such as microscopic examination of blood smears, are labor-intensive and require significant expertise, which may not be readily available in resource-limited settings. This project aims to automate the detection of malaria-infected cells using a deep learning approach. We employed a convolutional neural network (CNN) based on the ResNet50 architecture, leveraging transfer learning to enhance performance. The Malaria Cell Images Dataset from Kaggle, containing 27,558 images categorized into infected and uninfected cells, was used for training and evaluation. Our model demonstrated high accuracy, precision, and recall, indicating its potential as a reliable tool for assisting in malaria diagnosis. Additionally, a web application was developed using Streamlit to allow users to upload cell images and receive predictions about malaria infection, making the technology accessible and user-friendly. This paper provides a comprehensive overview of the methodology, experiments, and results, highlighting the effectiveness of deep learning in medical image analysis.
Domain Generalisation via Imprecise Learning
Apr 06, 2024
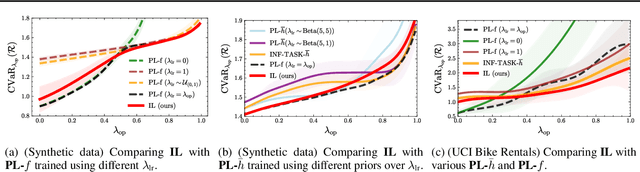
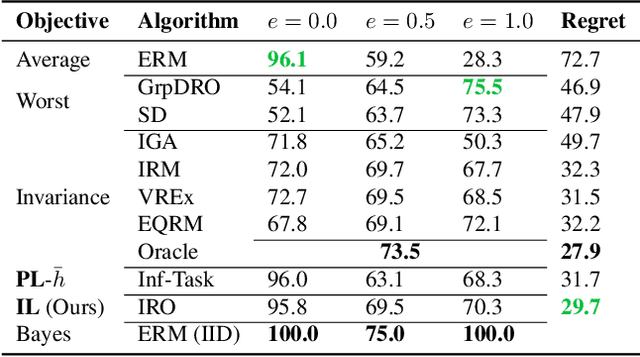
Out-of-distribution (OOD) generalisation is challenging because it involves not only learning from empirical data, but also deciding among various notions of generalisation, e.g., optimising the average-case risk, worst-case risk, or interpolations thereof. While this choice should in principle be made by the model operator like medical doctors, this information might not always be available at training time. The institutional separation between machine learners and model operators leads to arbitrary commitments to specific generalisation strategies by machine learners due to these deployment uncertainties. We introduce the Imprecise Domain Generalisation framework to mitigate this, featuring an imprecise risk optimisation that allows learners to stay imprecise by optimising against a continuous spectrum of generalisation strategies during training, and a model framework that allows operators to specify their generalisation preference at deployment. Supported by both theoretical and empirical evidence, our work showcases the benefits of integrating imprecision into domain generalisation.
Fast Adaptive Test-Time Defense with Robust Features
Jul 21, 2023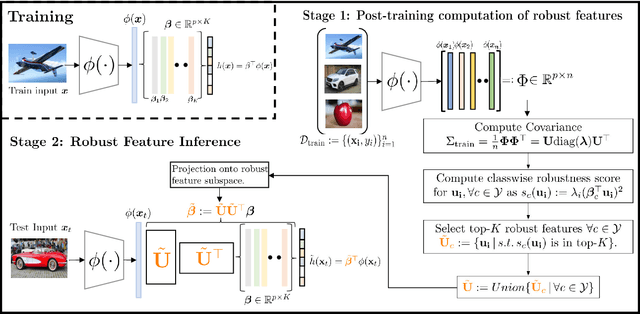

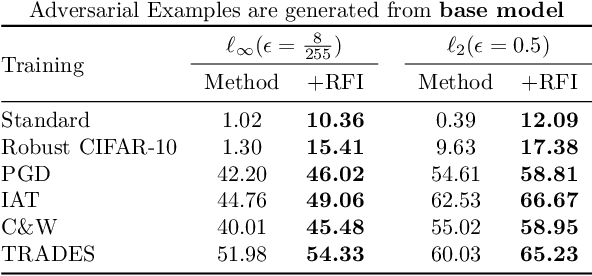
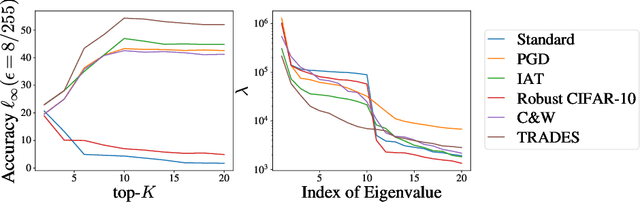
Adaptive test-time defenses are used to improve the robustness of deep neural networks to adversarial examples. However, existing methods significantly increase the inference time due to additional optimization on the model parameters or the input at test time. In this work, we propose a novel adaptive test-time defense strategy that is easy to integrate with any existing (robust) training procedure without additional test-time computation. Based on the notion of robustness of features that we present, the key idea is to project the trained models to the most robust feature space, thereby reducing the vulnerability to adversarial attacks in non-robust directions. We theoretically show that the top eigenspace of the feature matrix are more robust for a generalized additive model and support our argument for a large width neural network with the Neural Tangent Kernel (NTK) equivalence. We conduct extensive experiments on CIFAR-10 and CIFAR-100 datasets for several robustness benchmarks, including the state-of-the-art methods in RobustBench, and observe that the proposed method outperforms existing adaptive test-time defenses at much lower computation costs.
Pred&Guide: Labeled Target Class Prediction for Guiding Semi-Supervised Domain Adaptation
Nov 22, 2022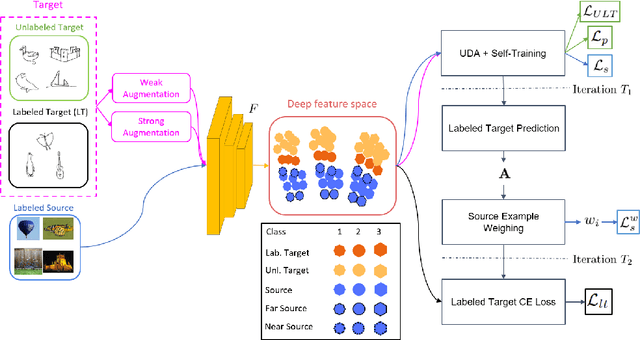
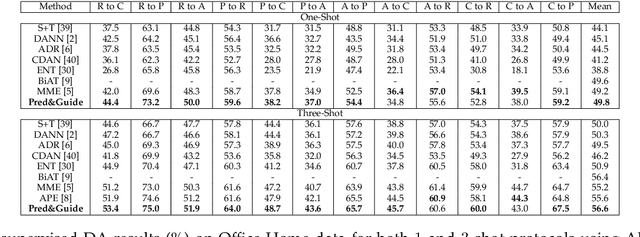

Semi-supervised domain adaptation aims to classify data belonging to a target domain by utilizing a related label-rich source domain and very few labeled examples of the target domain. Here, we propose a novel framework, Pred&Guide, which leverages the inconsistency between the predicted and the actual class labels of the few labeled target examples to effectively guide the domain adaptation in a semi-supervised setting. Pred&Guide consists of three stages, as follows (1) First, in order to treat all the target samples equally, we perform unsupervised domain adaptation coupled with self-training; (2) Second is the label prediction stage, where the current model is used to predict the labels of the few labeled target examples, and (3) Finally, the correctness of the label predictions are used to effectively weigh source examples class-wise to better guide the domain adaptation process. Extensive experiments show that the proposed Pred&Guide framework achieves state-of-the-art results for two large-scale benchmark datasets, namely Office-Home and DomainNet.
Optimal Reservoir Operations using Long Short-Term Memory Network
Sep 07, 2021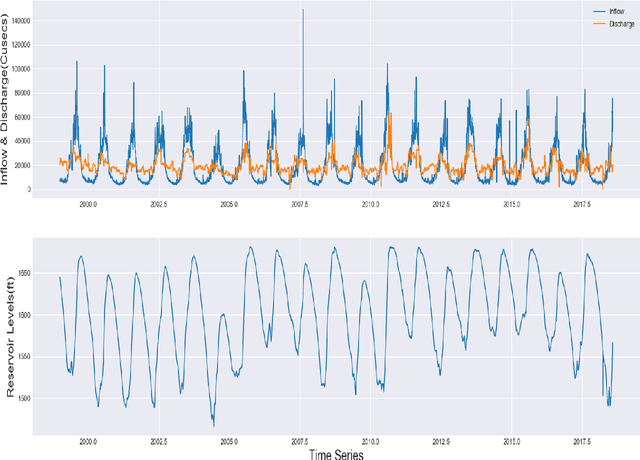
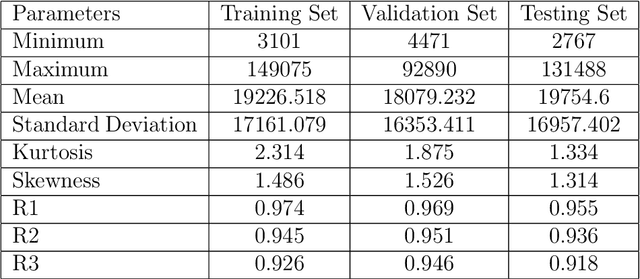
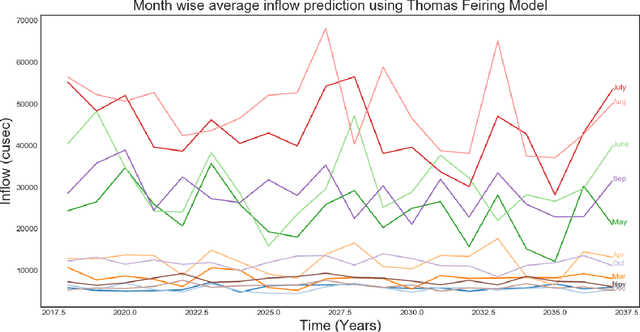
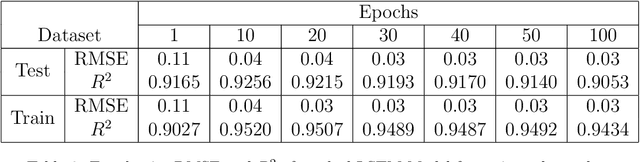
A reliable forecast of inflows to the reservoir is a key factor in the optimal operation of reservoirs. Real-time operation of the reservoir based on forecasts of inflows can lead to substantial economic gains. However, the forecast of inflow is an intricate task as it has to incorporate the impacts of climate and hydrological changes. Therefore, the major objective of the present work is to develop a novel approach based on long short-term memory (LSTM) for the forecast of inflows. Real-time inflow forecast, in other words, daily inflow at the reservoir helps in efficient operation of water resources. Also, daily variations in the release can be monitored efficiently and the reliability of operation is improved. This work proposes a naive anomaly detection algorithm baseline based on LSTM. In other words, a strong baseline to forecast flood and drought for any deep learning-based prediction model. The practicality of the approach has been demonstrated using the observed daily data of the past 20 years from Bhakra Dam in India. The results of the simulations conducted herein clearly indicate the supremacy of the LSTM approach over the traditional methods of forecasting. Although, experiments are run on data from Bhakra Dam Reservoir in India, LSTM model, and anomaly detection algorithm are general purpose and can be applied to any basin with minimal changes. A distinct practical advantage of the LSTM method presented herein is that it can adequately simulate non-stationarity and non-linearity in the historical data.
Self-Supervision based Task-Specific Image Collection Summarization
Jan 01, 2021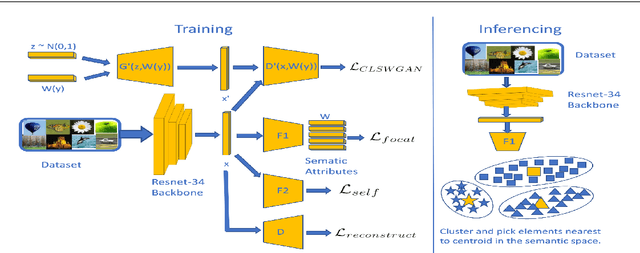
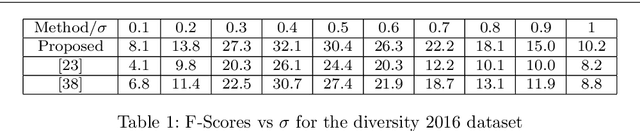
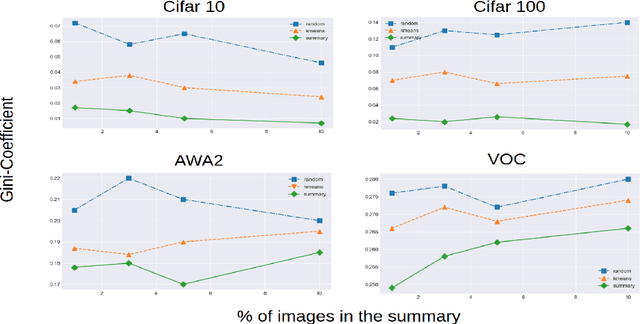
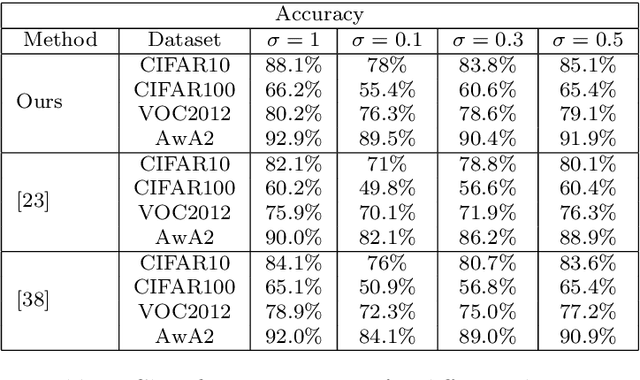
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.