 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndieFake Dataset: A Benchmark Dataset for Audio Deepfake Detection
Jun 23, 2025



Advancements in audio deepfake technology offers benefits like AI assistants, better accessibility for speech impairments, and enhanced entertainment. However, it also poses significant risks to security, privacy, and trust in digital communications. Detecting and mitigating these threats requires comprehensive datasets. Existing datasets lack diverse ethnic accents, making them inadequate for many real-world scenarios. Consequently, models trained on these datasets struggle to detect audio deepfakes in diverse linguistic and cultural contexts such as in South-Asian countries. Ironically, there is a stark lack of South-Asian speaker samples in the existing datasets despite constituting a quarter of the worlds population. This work introduces the IndieFake Dataset (IFD), featuring 27.17 hours of bonafide and deepfake audio from 50 English speaking Indian speakers. IFD offers balanced data distribution and includes speaker-level characterization, absent in datasets like ASVspoof21 (DF). We evaluated various baselines on IFD against existing ASVspoof21 (DF) and In-The-Wild (ITW) datasets. IFD outperforms ASVspoof21 (DF) and proves to be more challenging compared to benchmark ITW dataset. The dataset will be publicly available upon acceptance.
A Gaussian Process Upsampling Model for Improvements in Optical Character Recognition
May 07, 2020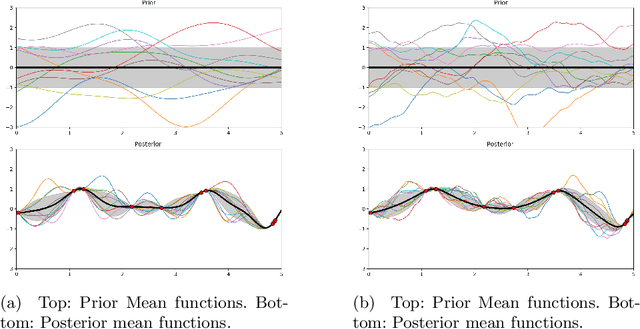

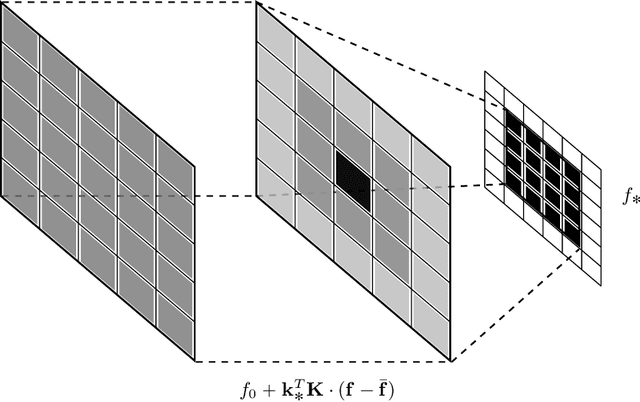

Optical Character Recognition and extraction is a key tool in the automatic evaluation of documents in a financial context. However, the image data provided to automated systems can have unreliable quality, and can be inherently low-resolution or downsampled and compressed by a transmitting program. In this paper, we illustrate the efficacy of a Gaussian Process upsampling model for the purposes of improving OCR and extraction through upsampling low resolution documents.
Mega-COV: A Billion-Scale Dataset of 65 Languages For COVID-19
May 02, 2020



We describe Mega-COV, a billion-scale dataset from Twitter for studying COVID-19. The dataset is diverse (covers 234 countries), longitudinal (goes as back as 2007), multilingual (comes in 65 languages), and has a significant number of location-tagged tweets (~32M tweets). We release tweet IDs from the dataset, hoping it will be useful for studying various phenomena related to the ongoing pandemic and accelerating viable solutions to associated problems.