Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gaussian Process Upsampling Model for Improvements in Optical Character Recognition
Paper and Code
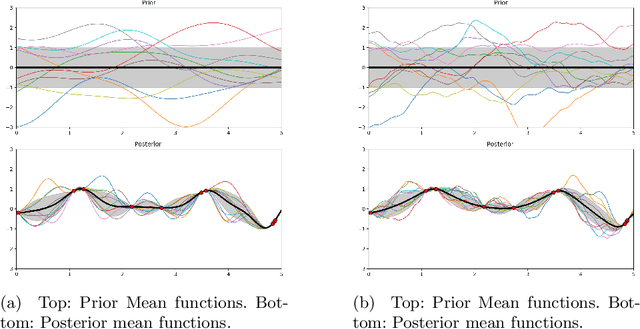

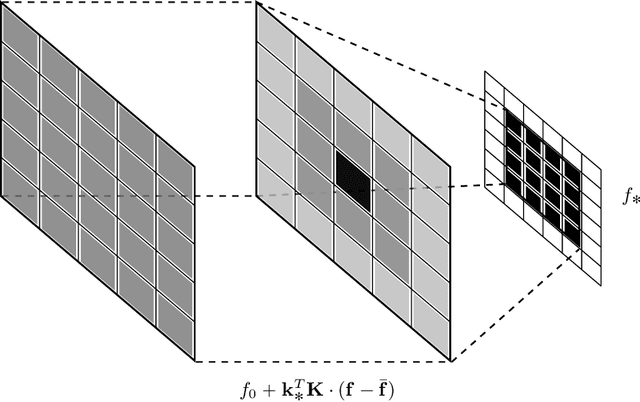

Optical Character Recognition and extraction is a key tool in the automatic evaluation of documents in a financial context. However, the image data provided to automated systems can have unreliable quality, and can be inherently low-resolution or downsampled and compressed by a transmitting program. In this paper, we illustrate the efficacy of a Gaussian Process upsampling model for the purposes of improving OCR and extraction through upsampling low resolution documents.
* 12 pages, 7 figures, 1 table
View paper on