 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenZ: Foundational models as latent variable generators within traditional statistical models
Dec 31, 2025We present GenZ, a hybrid model that bridges foundational models and statistical modeling through interpretable semantic features. While large language models possess broad domain knowledge, they often fail to capture dataset-specific patterns critical for prediction tasks. Our approach addresses this by discovering semantic feature descriptions through an iterative process that contrasts groups of items identified via statistical modeling errors, rather than relying solely on the foundational model's domain understanding. We formulate this as a generalized EM algorithm that jointly optimizes semantic feature descriptors and statistical model parameters. The method prompts a frozen foundational model to classify items based on discovered features, treating these judgments as noisy observations of latent binary features that predict real-valued targets through learned statistical relationships. We demonstrate the approach on two domains: house price prediction (hedonic regression) and cold-start collaborative filtering for movie recommendations. On house prices, our model achieves 12\% median relative error using discovered semantic features from multimodal listing data, substantially outperforming a GPT-5 baseline (38\% error) that relies on the LLM's general domain knowledge. For Netflix movie embeddings, our model predicts collaborative filtering representations with 0.59 cosine similarity purely from semantic descriptions -- matching the performance that would require approximately 4000 user ratings through traditional collaborative filtering. The discovered features reveal dataset-specific patterns (e.g., architectural details predicting local housing markets, franchise membership predicting user preferences) that diverge from the model's domain knowledge alone.
City Navigation in the Wild: Exploring Emergent Navigation from Web-Scale Knowledge in MLLMs
Dec 17, 2025Leveraging multimodal large language models (MLLMs) to develop embodied agents offers significant promise for addressing complex real-world tasks. However, current evaluation benchmarks remain predominantly language-centric or heavily reliant on simulated environments, rarely probing the nuanced, knowledge-intensive reasoning essential for practical, real-world scenarios. To bridge this critical gap, we introduce the task of Sparsely Grounded Visual Navigation, explicitly designed to evaluate the sequential decision-making abilities of MLLMs in challenging, knowledge-intensive real-world environments. We operationalize this task with CityNav, a comprehensive benchmark encompassing four diverse global cities, specifically constructed to assess raw MLLM-driven agents in city navigation. Agents are required to rely solely on visual inputs and internal multimodal reasoning to sequentially navigate 50+ decision points without additional environmental annotations or specialized architectural modifications. Crucially, agents must autonomously achieve localization through interpreting city-specific cues and recognizing landmarks, perform spatial reasoning, and strategically plan and execute routes to their destinations. Through extensive evaluations, we demonstrate that current state-of-the-art MLLMs and standard reasoning techniques (e.g., Chain-of-Thought, Reflection) significantly underperform in this challenging setting. To address this, we propose Verbalization of Path (VoP), which explicitly grounds the agent's internal reasoning by probing an explicit cognitive map (key landmarks and directions toward the destination) from the MLLMs, substantially enhancing navigation success. Project Webpage: https://dwipddalal.github.io/AgentNav/
Differentiable Channel Selection in Self-Attention For Person Re-Identification
May 13, 2025



In this paper, we propose a novel attention module termed the Differentiable Channel Selection Attention module, or the DCS-Attention module. In contrast with conventional self-attention, the DCS-Attention module features selection of informative channels in the computation of the attention weights. The selection of the feature channels is performed in a differentiable manner, enabling seamless integration with DNN training. Our DCS-Attention is compatible with either fixed neural network backbones or learnable backbones with Differentiable Neural Architecture Search (DNAS), leading to DCS with Fixed Backbone (DCS-FB) and DCS-DNAS, respectively. Importantly, our DCS-Attention is motivated by the principle of Information Bottleneck (IB), and a novel variational upper bound for the IB loss, which can be optimized by SGD, is derived and incorporated into the training loss of the networks with the DCS-Attention modules. In this manner, a neural network with DCS-Attention modules is capable of selecting the most informative channels for feature extraction so that it enjoys state-of-the-art performance for the Re-ID task. Extensive experiments on multiple person Re-ID benchmarks using both DCS-FB and DCS-DNAS show that DCS-Attention significantly enhances the prediction accuracy of DNNs for person Re-ID, which demonstrates the effectiveness of DCS-Attention in learning discriminative features critical to identifying person identities. The code of our work is available at https://github.com/Statistical-Deep-Learning/DCS-Attention.
Make Some Noise: Towards LLM audio reasoning and generation using sound tokens
Mar 28, 2025
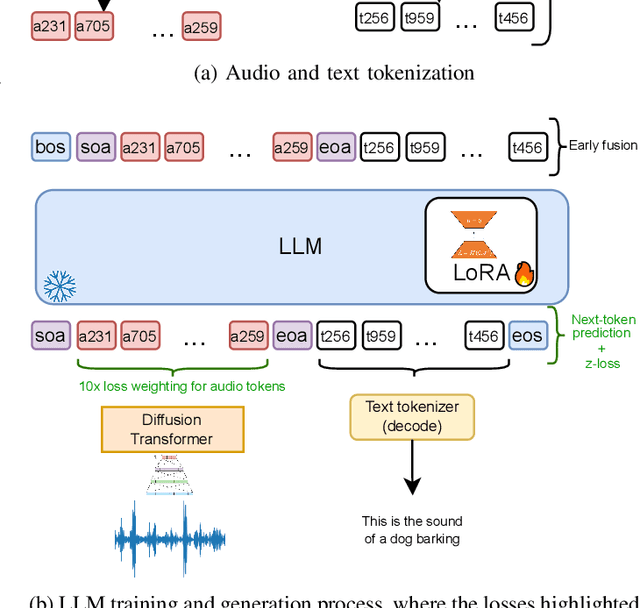


Integrating audio comprehension and generation into large language models (LLMs) remains challenging due to the continuous nature of audio and the resulting high sampling rates. Here, we introduce a novel approach that combines Variational Quantization with Conditional Flow Matching to convert audio into ultra-low bitrate discrete tokens of 0.23kpbs, allowing for seamless integration with text tokens in LLMs. We fine-tuned a pretrained text-based LLM using Low-Rank Adaptation (LoRA) to assess its effectiveness in achieving true multimodal capabilities, i.e., audio comprehension and generation. Our tokenizer outperforms a traditional VQ-VAE across various datasets with diverse acoustic events. Despite the substantial loss of fine-grained details through audio tokenization, our multimodal LLM trained with discrete tokens achieves competitive results in audio comprehension with state-of-the-art methods, though audio generation is poor. Our results highlight the need for larger, more diverse datasets and improved evaluation metrics to advance multimodal LLM performance.
Echoes in AI: Quantifying Lack of Plot Diversity in LLM Outputs
Dec 31, 2024With rapid advances in large language models (LLMs), there has been an increasing application of LLMs in creative content ideation and generation. A critical question emerges: can current LLMs provide ideas that are diverse enough to truly bolster the collective creativity? We examine two state-of-the-art LLMs, GPT-4 and LLaMA-3, on story generation and discover that LLM-generated stories often consist of plot elements that are echoed across a number of generations. To quantify this phenomenon, we introduce the Sui Generis score, which estimates how unlikely a plot element is to appear in alternative storylines generated by the same LLM. Evaluating on 100 short stories, we find that LLM-generated stories often contain combinations of idiosyncratic plot elements echoed frequently across generations, while the original human-written stories are rarely recreated or even echoed in pieces. Moreover, our human evaluation shows that the ranking of Sui Generis scores among story segments correlates moderately with human judgment of surprise level, even though score computation is completely automatic without relying on human judgment.
Game Plot Design with an LLM-powered Assistant: An Empirical Study with Game Designers
Nov 05, 2024We introduce GamePlot, an LLM-powered assistant that supports game designers in crafting immersive narratives for turn-based games, and allows them to test these games through a collaborative game play and refine the plot throughout the process. Our user study with 14 game designers shows high levels of both satisfaction with the generated game plots and sense of ownership over the narratives, but also reconfirms that LLM are limited in their ability to generate complex and truly innovative content. We also show that diverse user populations have different expectations from AI assistants, and encourage researchers to study how tailoring assistants to diverse user groups could potentially lead to increased job satisfaction and greater creativity and innovation over time.
Fast constrained sampling in pre-trained diffusion models
Oct 24, 2024



Diffusion models have dominated the field of large, generative image models, with the prime examples of Stable Diffusion and DALL-E 3 being widely adopted. These models have been trained to perform text-conditioned generation on vast numbers of image-caption pairs and as a byproduct, have acquired general knowledge about natural image statistics. However, when confronted with the task of constrained sampling, e.g. generating the right half of an image conditioned on the known left half, applying these models is a delicate and slow process, with previously proposed algorithms relying on expensive iterative operations that are usually orders of magnitude slower than text-based inference. This is counter-intuitive, as image-conditioned generation should rely less on the difficult-to-learn semantic knowledge that links captions and imagery, and should instead be achievable by lower-level correlations among image pixels. In practice, inverse models are trained or tuned separately for each inverse problem, e.g. by providing parts of images during training as an additional condition, to allow their application in realistic settings. However, we argue that this is not necessary and propose an algorithm for fast-constrained sampling in large pre-trained diffusion models (Stable Diffusion) that requires no expensive backpropagation operations through the model and produces results comparable even to the state-of-the-art \emph{tuned} models. Our method is based on a novel optimization perspective to sampling under constraints and employs a numerical approximation to the expensive gradients, previously computed using backpropagation, incurring significant speed-ups.
fPLSA: Learning Semantic Structures in Document Collections Using Foundation Models
Oct 07, 2024



Humans have the ability to learn new tasks by inferring high-level concepts from existing solution, then manipulating these concepts in lieu of the raw data. Can we automate this process by deriving latent semantic structures in a document collection using foundation models? We introduce fPLSA, a foundation-model-based Probabilistic Latent Semantic Analysis (PLSA) method that iteratively clusters and tags document segments based on document-level contexts. These tags can be used to model the structure of given documents and for hierarchical sampling of new texts. Our experiments on story writing, math, and multi-step reasoning datasets demonstrate that fPLSA tags help reconstruct the original texts better than existing tagging methods. Moreover, when used for hierarchical sampling, fPLSA produces more diverse outputs with a higher likelihood of hitting the correct answer than direct sampling and hierarchical sampling with existing tagging methods.
Player-Driven Emergence in LLM-Driven Game Narrative
Apr 25, 2024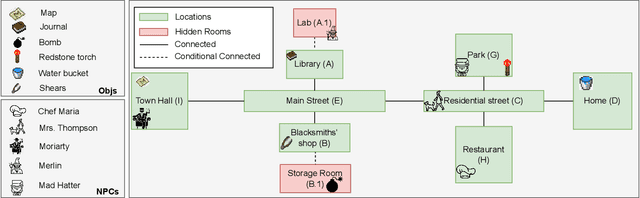
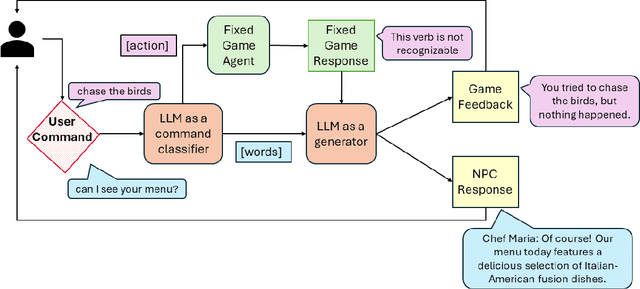
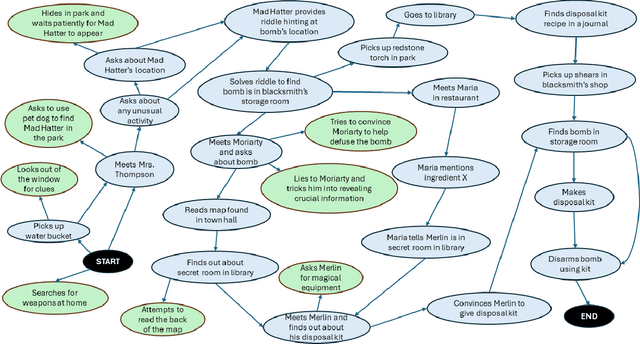

We explore how interaction with large language models (LLMs) can give rise to emergent behaviors, empowering players to participate in the evolution of game narratives. Our testbed is a text-adventure game in which players attempt to solve a mystery under a fixed narrative premise, but can freely interact with non-player characters generated by GPT-4, a large language model. We recruit 28 gamers to play the game and use GPT-4 to automatically convert the game logs into a node-graph representing the narrative in the player's gameplay. We find that through their interactions with the non-deterministic behavior of the LLM, players are able to discover interesting new emergent nodes that were not a part of the original narrative but have potential for being fun and engaging. Players that created the most emergent nodes tended to be those that often enjoy games that facilitate discovery, exploration and experimentation.
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
Oct 25, 2023
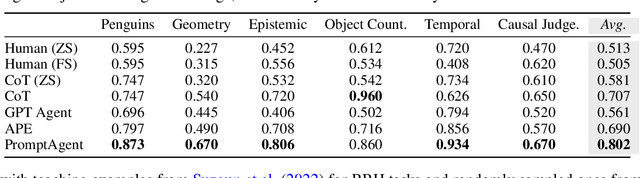
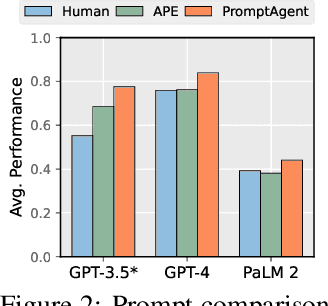
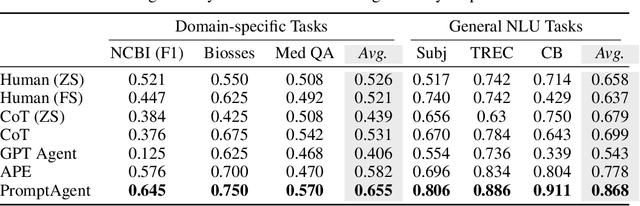
Highly effective, task-specific prompts are often heavily engineered by experts to integrate detailed instructions and domain insights based on a deep understanding of both instincts of large language models (LLMs) and the intricacies of the target task. However, automating the generation of such expert-level prompts remains elusive. Existing prompt optimization methods tend to overlook the depth of domain knowledge and struggle to efficiently explore the vast space of expert-level prompts. Addressing this, we present PromptAgent, an optimization method that autonomously crafts prompts equivalent in quality to those handcrafted by experts. At its core, PromptAgent views prompt optimization as a strategic planning problem and employs a principled planning algorithm, rooted in Monte Carlo tree search, to strategically navigate the expert-level prompt space. Inspired by human-like trial-and-error exploration, PromptAgent induces precise expert-level insights and in-depth instructions by reflecting on model errors and generating constructive error feedback. Such a novel framework allows the agent to iteratively examine intermediate prompts (states), refine them based on error feedbacks (actions), simulate future rewards, and search for high-reward paths leading to expert prompts. We apply PromptAgent to 12 tasks spanning three practical domains: BIG-Bench Hard (BBH), as well as domain-specific and general NLP tasks, showing it significantly outperforms strong Chain-of-Thought and recent prompt optimization baselines. Extensive analyses emphasize its capability to craft expert-level, detailed, and domain-insightful prompts with great efficiency and generalizability.