 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
World Reasoning Arena
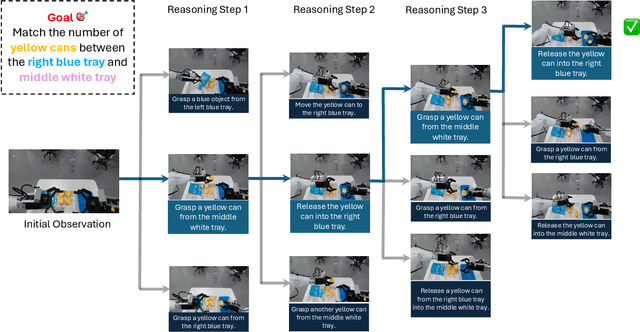
Mar 26, 2026World models (WMs) are intended to serve as internal simulators of the real world that enable agents to understand, anticipate, and act upon complex environments. Existing WM benchmarks remain narrowly focused on next-state prediction and visual fidelity, overlooking the richer simulation capabilities required for intelligent behavior. To address this gap, we introduce WR-Arena, a comprehensive benchmark for evaluating WMs along three fundamental dimensions of next world simulation: (i) Action Simulation Fidelity, the ability to interpret and follow semantically meaningful, multi-step instructions and generate diverse counterfactual rollouts; (ii) Long-horizon Forecast, the ability to sustain accurate, coherent, and physically plausible simulations across extended interactions; and (iii) Simulative Reasoning and Planning, the ability to support goal-directed reasoning by simulating, comparing, and selecting among alternative futures in both structured and open-ended environments. We build a task taxonomy and curate diverse datasets designed to probe these capabilities, moving beyond single-turn and perceptual evaluations. Through extensive experiments with state-of-the-art WMs, our results expose a substantial gap between current models and human-level hypothetical reasoning, and establish WR-Arena as both a diagnostic tool and a guideline for advancing next-generation world models capable of robust understanding, forecasting, and purposeful action. The code is available at https://github.com/MBZUAI-IFM/WR-Arena.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025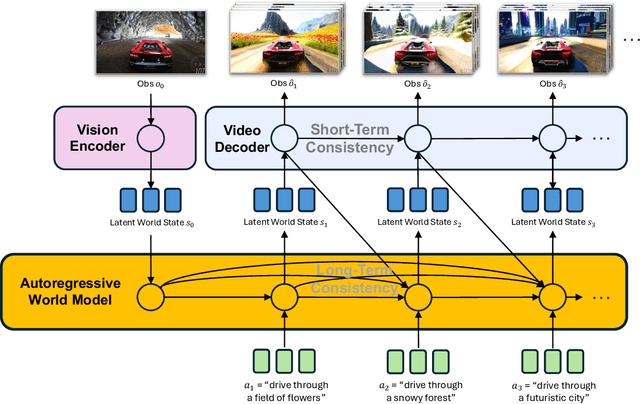
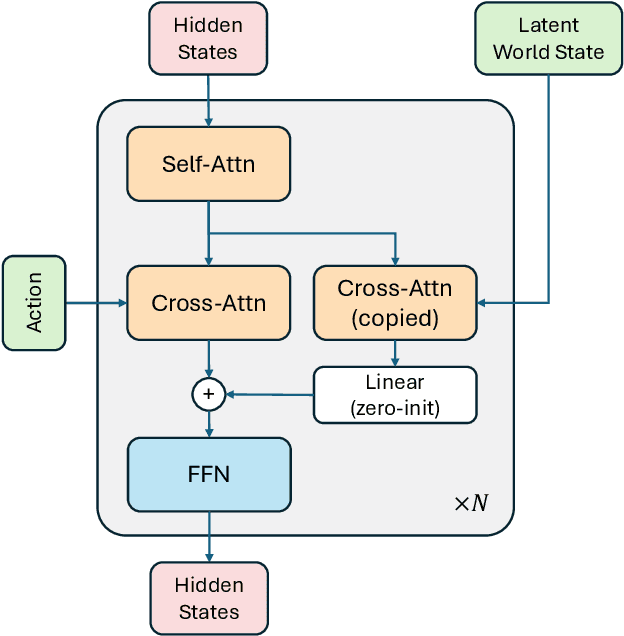
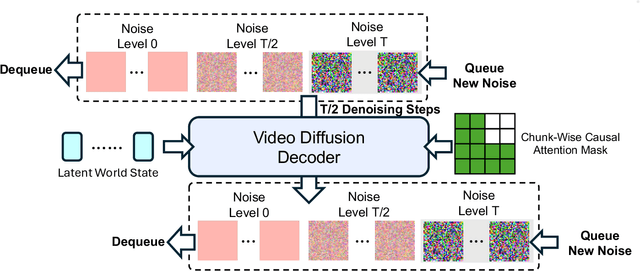
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Apr 08, 2024Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
Extracting Mathematical Concepts with Large Language Models
Aug 29, 2023



We extract mathematical concepts from mathematical text using generative large language models (LLMs) like ChatGPT, contributing to the field of automatic term extraction (ATE) and mathematical text processing, and also to the study of LLMs themselves. Our work builds on that of others in that we aim for automatic extraction of terms (keywords) in one mathematical field, category theory, using as a corpus the 755 abstracts from a snapshot of the online journal "Theory and Applications of Categories", circa 2020. Where our study diverges from previous work is in (1) providing a more thorough analysis of what makes mathematical term extraction a difficult problem to begin with; (2) paying close attention to inter-annotator disagreements; (3) providing a set of guidelines which both human and machine annotators could use to standardize the extraction process; (4) introducing a new annotation tool to help humans with ATE, applicable to any mathematical field and even beyond mathematics; (5) using prompts to ChatGPT as part of the extraction process, and proposing best practices for such prompts; and (6) raising the question of whether ChatGPT could be used as an annotator on the same level as human experts. Our overall findings are that the matter of mathematical ATE is an interesting field which can benefit from participation by LLMs, but LLMs themselves cannot at this time surpass human performance on it.
DISCO: Distilling Phrasal Counterfactuals with Large Language Models
Dec 20, 2022



Recent methods demonstrate that data augmentation using counterfactual knowledge can teach models the causal structure of a task, leading to robust and generalizable models. However, such counterfactual data often has a limited scale and diversity if crowdsourced and is computationally expensive to extend to new perturbation types if generated using supervised methods. To address this, we introduce a new framework called DISCO for automatically generating high-quality counterfactual data at scale. DISCO engineers prompts to generate phrasal perturbations with a large general language model. Then, a task-specific teacher model filters the generation to distill high-quality counterfactual data. We show that learning with this counterfactual data yields a comparatively small student model that is 6% (absolute) more robust and generalizes 5% better across distributions than baselines on various challenging evaluations. This model is also 15% more sensitive in differentiating original and counterfactual examples, on three evaluation sets written by human workers and via human-AI collaboration.
Curriculum: A Broad-Coverage Benchmark for Linguistic Phenomena in Natural Language Understanding
Apr 13, 2022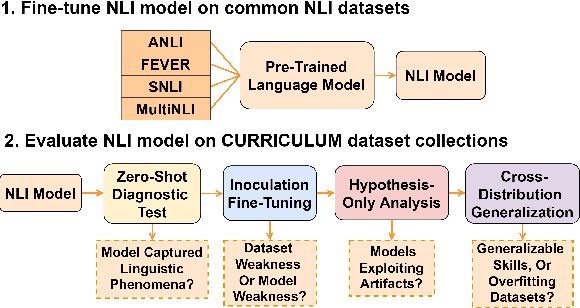
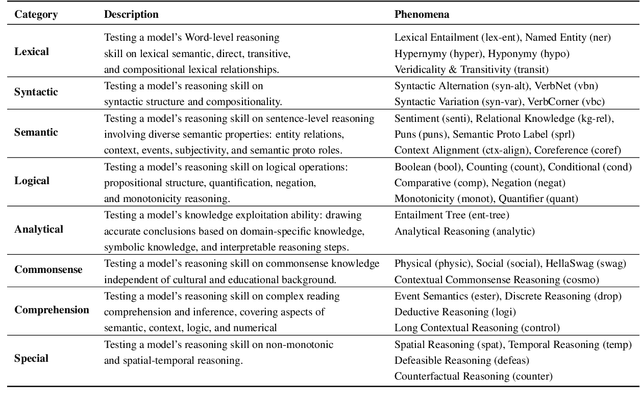
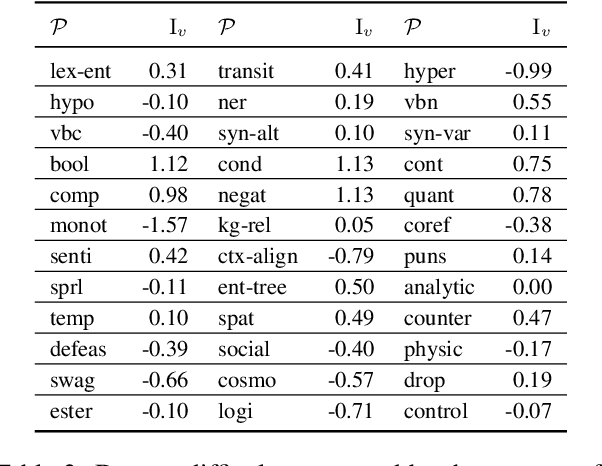
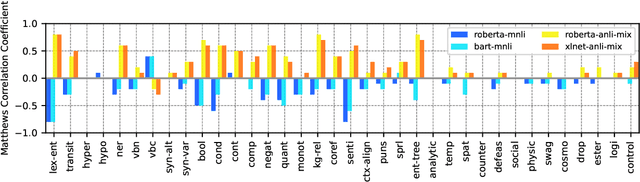
In the age of large transformer language models, linguistic evaluation play an important role in diagnosing models' abilities and limitations on natural language understanding. However, current evaluation methods show some significant shortcomings. In particular, they do not provide insight into how well a language model captures distinct linguistic skills essential for language understanding and reasoning. Thus they fail to effectively map out the aspects of language understanding that remain challenging to existing models, which makes it hard to discover potential limitations in models and datasets. In this paper, we introduce Curriculum as a new format of NLI benchmark for evaluation of broad-coverage linguistic phenomena. Curriculum contains a collection of datasets that covers 36 types of major linguistic phenomena and an evaluation procedure for diagnosing how well a language model captures reasoning skills for distinct types of linguistic phenomena. We show that this linguistic-phenomena-driven benchmark can serve as an effective tool for diagnosing model behavior and verifying model learning quality. In addition, Our experiments provide insight into the limitation of existing benchmark datasets and state-of-the-art models that may encourage future research on re-designing datasets, model architectures, and learning objectives.
Probing Linguistic Information For Logical Inference In Pre-trained Language Models
Dec 03, 2021



Progress in pre-trained language models has led to a surge of impressive results on downstream tasks for natural language understanding. Recent work on probing pre-trained language models uncovered a wide range of linguistic properties encoded in their contextualized representations. However, it is unclear whether they encode semantic knowledge that is crucial to symbolic inference methods. We propose a methodology for probing linguistic information for logical inference in pre-trained language model representations. Our probing datasets cover a list of linguistic phenomena required by major symbolic inference systems. We find that (i) pre-trained language models do encode several types of linguistic information for inference, but there are also some types of information that are weakly encoded, (ii) language models can effectively learn missing linguistic information through fine-tuning. Overall, our findings provide insights into which aspects of linguistic information for logical inference do language models and their pre-training procedures capture. Moreover, we have demonstrated language models' potential as semantic and background knowledge bases for supporting symbolic inference methods.
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
Jun 10, 2021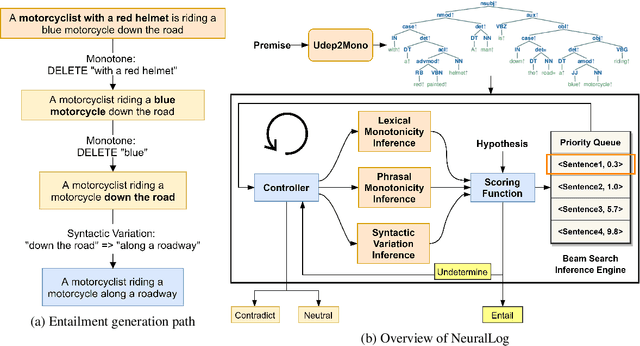
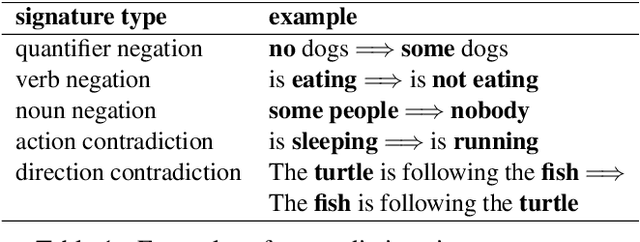
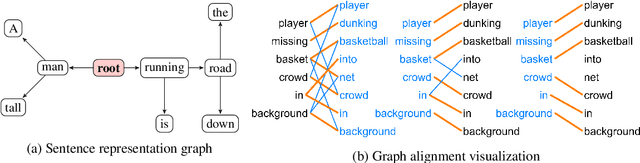

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.