 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Language-Vision Planner and Executor for Text-to-Visual Reasoning
Jun 09, 2025The advancement in large language models (LLMs) and large vision models has fueled the rapid progress in multi-modal visual-text reasoning capabilities. However, existing vision-language models (VLMs) to date suffer from generalization performance. Inspired by recent development in LLMs for visual reasoning, this paper presents VLAgent, an AI system that can create a step-by-step visual reasoning plan with an easy-to-understand script and execute each step of the plan in real time by integrating planning script with execution verifications via an automated process supported by VLAgent. In the task planning phase, VLAgent fine-tunes an LLM through in-context learning to generate a step-by-step planner for each user-submitted text-visual reasoning task. During the plan execution phase, VLAgent progressively refines the composition of neuro-symbolic executable modules to generate high-confidence reasoning results. VLAgent has three unique design characteristics: First, we improve the quality of plan generation through in-context learning, improving logic reasoning by reducing erroneous logic steps, incorrect programs, and LLM hallucinations. Second, we design a syntax-semantics parser to identify and correct additional logic errors of the LLM-generated planning script prior to launching the plan executor. Finally, we employ the ensemble method to improve the generalization performance of our step-executor. Extensive experiments with four visual reasoning benchmarks (GQA, MME, NLVR2, VQAv2) show that VLAgent achieves significant performance enhancement for multimodal text-visual reasoning applications, compared to the exiting representative VLMs and LLM based visual composition approaches like ViperGPT and VisProg, thanks to the novel optimization modules of VLAgent back-engine (SS-Parser, Plan Repairer, Output Verifiers). Code and data will be made available upon paper acceptance.
Robust Federated Learning Mitigates Client-side Training Data Distribution Inference Attacks
Mar 05, 2024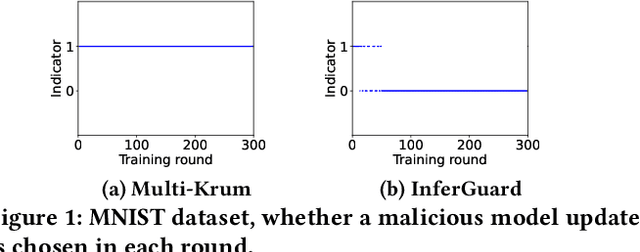



Recent studies have revealed that federated learning (FL), once considered secure due to clients not sharing their private data with the server, is vulnerable to attacks such as client-side training data distribution inference, where a malicious client can recreate the victim's data. While various countermeasures exist, they are not practical, often assuming server access to some training data or knowledge of label distribution before the attack. In this work, we bridge the gap by proposing InferGuard, a novel Byzantine-robust aggregation rule aimed at defending against client-side training data distribution inference attacks. In our proposed InferGuard, the server first calculates the coordinate-wise median of all the model updates it receives. A client's model update is considered malicious if it significantly deviates from the computed median update. We conduct a thorough evaluation of our proposed InferGuard on five benchmark datasets and perform a comparison with ten baseline methods. The results of our experiments indicate that our defense mechanism is highly effective in protecting against client-side training data distribution inference attacks, even against strong adaptive attacks. Furthermore, our method substantially outperforms the baseline methods in various practical FL scenarios.
Poisoning Federated Recommender Systems with Fake Users
Feb 18, 2024Federated recommendation is a prominent use case within federated learning, yet it remains susceptible to various attacks, from user to server-side vulnerabilities. Poisoning attacks are particularly notable among user-side attacks, as participants upload malicious model updates to deceive the global model, often intending to promote or demote specific targeted items. This study investigates strategies for executing promotion attacks in federated recommender systems. Current poisoning attacks on federated recommender systems often rely on additional information, such as the local training data of genuine users or item popularity. However, such information is challenging for the potential attacker to obtain. Thus, there is a need to develop an attack that requires no extra information apart from item embeddings obtained from the server. In this paper, we introduce a novel fake user based poisoning attack named PoisonFRS to promote the attacker-chosen targeted item in federated recommender systems without requiring knowledge about user-item rating data, user attributes, or the aggregation rule used by the server. Extensive experiments on multiple real-world datasets demonstrate that PoisonFRS can effectively promote the attacker-chosen targeted item to a large portion of genuine users and outperform current benchmarks that rely on additional information about the system. We further observe that the model updates from both genuine and fake users are indistinguishable within the latent space.
Toward Robust Recommendation via Real-time Vicinal Defense
Sep 29, 2023Recommender systems have been shown to be vulnerable to poisoning attacks, where malicious data is injected into the dataset to cause the recommender system to provide biased recommendations. To defend against such attacks, various robust learning methods have been proposed. However, most methods are model-specific or attack-specific, making them lack generality, while other methods, such as adversarial training, are oriented towards evasion attacks and thus have a weak defense strength in poisoning attacks. In this paper, we propose a general method, Real-time Vicinal Defense (RVD), which leverages neighboring training data to fine-tune the model before making a recommendation for each user. RVD works in the inference phase to ensure the robustness of the specific sample in real-time, so there is no need to change the model structure and training process, making it more practical. Extensive experimental results demonstrate that RVD effectively mitigates targeted poisoning attacks across various models without sacrificing accuracy. Moreover, the defensive effect can be further amplified when our method is combined with other strategies.