 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB+ANN: A Fast Billion-Scale Disk-based Nearest-Neighbor Index
Nov 19, 2025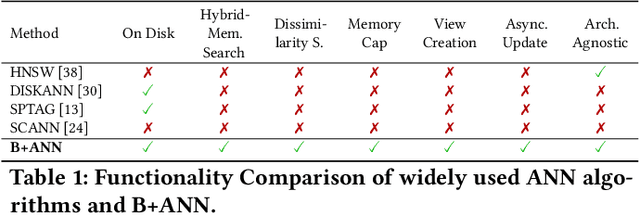



Storing and processing of embedding vectors by specialized Vector databases (VDBs) has become the linchpin in building modern AI pipelines. Most current VDBs employ variants of a graph-based ap- proximate nearest-neighbor (ANN) index algorithm, HNSW, to an- swer semantic queries over stored vectors. Inspite of its wide-spread use, the HNSW algorithm suffers from several issues: in-memory design and implementation, random memory accesses leading to degradation in cache behavior, limited acceleration scope due to fine-grained pairwise computations, and support of only semantic similarity queries. In this paper, we present a novel disk-based ANN index, B+ANN, to address these issues: it first partitions input data into blocks containing semantically similar items, then builds an B+ tree variant to store blocks both in-memory and on disks, and finally, enables hybrid edge- and block-based in-memory traversals. As demonstrated by our experimantal evaluation, the proposed B+ANN disk-based index improves both quality (Recall value), and execution performance (Queries per second/QPS) over HNSW, by improving spatial and temporal locality for semantic operations, reducing cache misses (19.23% relative gain), and decreasing the memory consumption and disk-based build time by 24x over the DiskANN algorithm. Finally, it enables dissimilarity queries, which are not supported by similarity-oriented ANN indices.
FedHFT: Efficient Federated Finetuning with Heterogeneous Edge Clients
Oct 15, 2025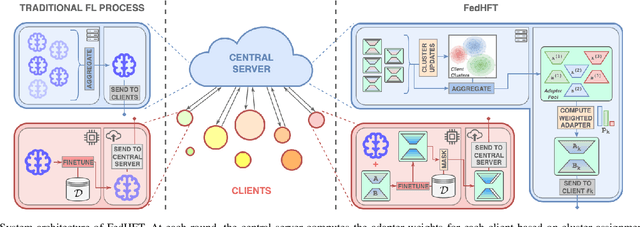
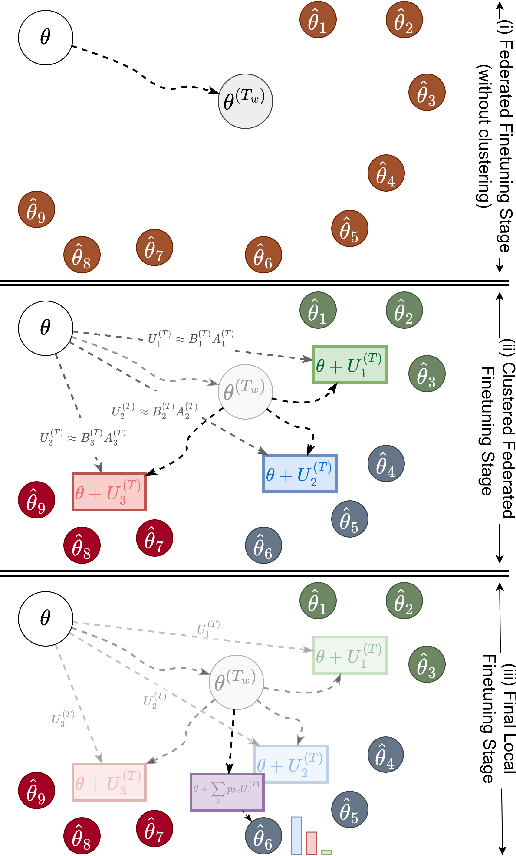
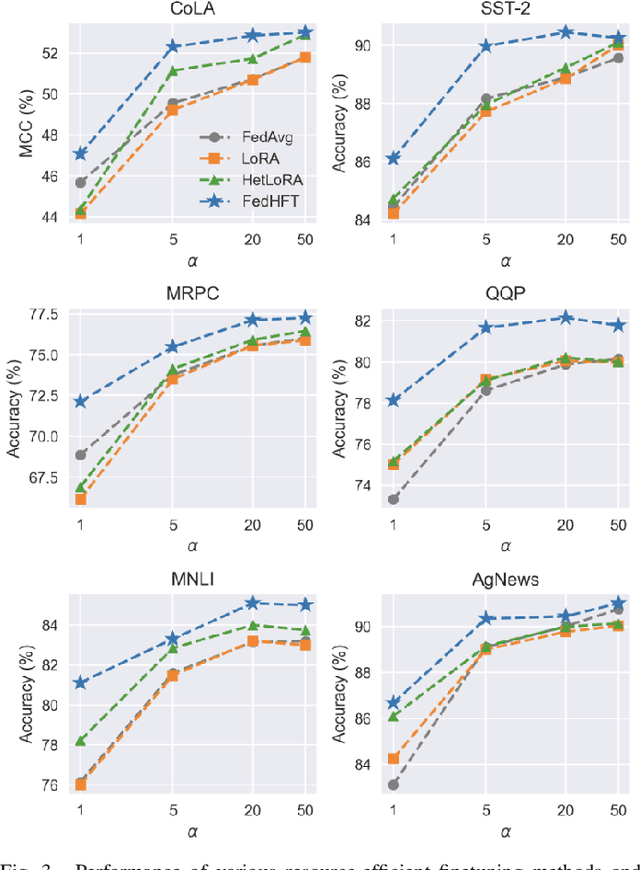
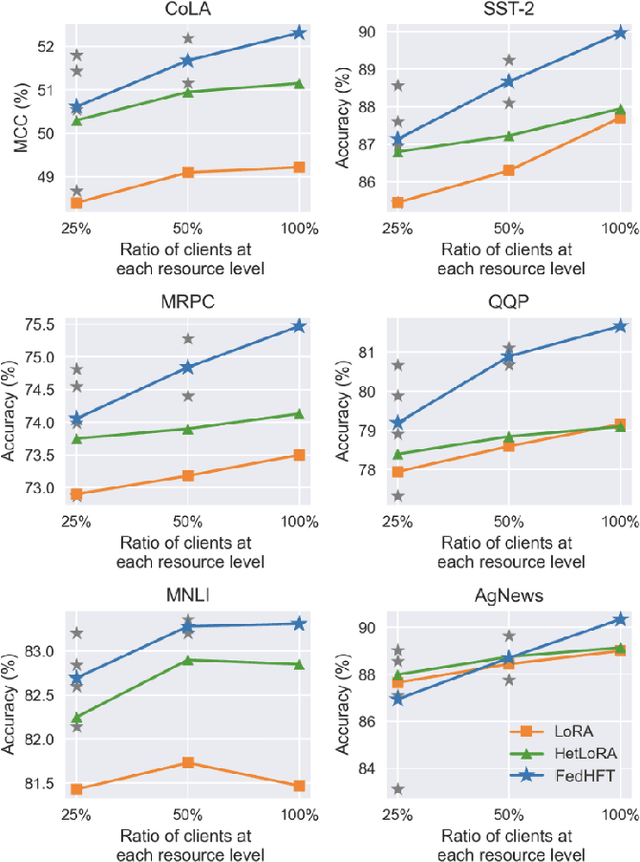
Fine-tuning pre-trained large language models (LLMs) has become a common practice for personalized natural language understanding (NLU) applications on downstream tasks and domain-specific datasets. However, there are two main challenges: (i) limited and/or heterogeneous data for fine-tuning due to proprietary data confidentiality or privacy requirements, and (ii) varying computation resources available across participating clients such as edge devices. This paper presents FedHFT - an efficient and personalized federated fine-tuning framework to address both challenges. First, we introduce a mixture of masked adapters to handle resource heterogeneity across participating clients, enabling high-performance collaborative fine-tuning of pre-trained language model(s) across multiple clients in a distributed setting, while keeping proprietary data local. Second, we introduce a bi-level optimization approach to handle non-iid data distribution based on masked personalization and client clustering. Extensive experiments demonstrate significant performance and efficiency improvements over various natural language understanding tasks under data and resource heterogeneity compared to representative heterogeneous federated learning methods.
Language-Vision Planner and Executor for Text-to-Visual Reasoning
Jun 09, 2025The advancement in large language models (LLMs) and large vision models has fueled the rapid progress in multi-modal visual-text reasoning capabilities. However, existing vision-language models (VLMs) to date suffer from generalization performance. Inspired by recent development in LLMs for visual reasoning, this paper presents VLAgent, an AI system that can create a step-by-step visual reasoning plan with an easy-to-understand script and execute each step of the plan in real time by integrating planning script with execution verifications via an automated process supported by VLAgent. In the task planning phase, VLAgent fine-tunes an LLM through in-context learning to generate a step-by-step planner for each user-submitted text-visual reasoning task. During the plan execution phase, VLAgent progressively refines the composition of neuro-symbolic executable modules to generate high-confidence reasoning results. VLAgent has three unique design characteristics: First, we improve the quality of plan generation through in-context learning, improving logic reasoning by reducing erroneous logic steps, incorrect programs, and LLM hallucinations. Second, we design a syntax-semantics parser to identify and correct additional logic errors of the LLM-generated planning script prior to launching the plan executor. Finally, we employ the ensemble method to improve the generalization performance of our step-executor. Extensive experiments with four visual reasoning benchmarks (GQA, MME, NLVR2, VQAv2) show that VLAgent achieves significant performance enhancement for multimodal text-visual reasoning applications, compared to the exiting representative VLMs and LLM based visual composition approaches like ViperGPT and VisProg, thanks to the novel optimization modules of VLAgent back-engine (SS-Parser, Plan Repairer, Output Verifiers). Code and data will be made available upon paper acceptance.
Multi-Agent Reinforcement Learning with Focal Diversity Optimization
Feb 06, 2025



The advancement of Large Language Models (LLMs) and their finetuning strategies has triggered the renewed interests in multi-agent reinforcement learning. In this paper, we introduce a focal diversity-optimized multi-agent reinforcement learning approach, coined as MARL-Focal, with three unique characteristics. First, we develop an agent-fusion framework for encouraging multiple LLM based agents to collaborate in producing the final inference output for each LLM query. Second, we develop a focal-diversity optimized agent selection algorithm that can choose a small subset of the available agents based on how well they can complement one another to generate the query output. Finally, we design a conflict-resolution method to detect output inconsistency among multiple agents and produce our MARL-Focal output through reward-aware and policy-adaptive inference fusion. Extensive evaluations on five benchmarks show that MARL-Focal is cost-efficient and adversarial-robust. Our multi-agent fusion model achieves performance improvement of 5.51\% compared to the best individual LLM-agent and offers stronger robustness over the TruthfulQA benchmark. Code is available at https://github.com/sftekin/rl-focal
Virus: Harmful Fine-tuning Attack for Large Language Models Bypassing Guardrail Moderation
Jan 29, 2025



Recent research shows that Large Language Models (LLMs) are vulnerable to harmful fine-tuning attacks -- models lose their safety alignment ability after fine-tuning on a few harmful samples. For risk mitigation, a guardrail is typically used to filter out harmful samples before fine-tuning. By designing a new red-teaming method, we in this paper show that purely relying on the moderation guardrail for data filtration is not reliable. Our proposed attack method, dubbed Virus, easily bypasses the guardrail moderation by slightly modifying the harmful data. Experimental results show that the harmful data optimized by Virus is not detectable by the guardrail with up to 100\% leakage ratio, and can simultaneously achieve superior attack performance. Finally, the key message we want to convey through this paper is that: \textbf{it is reckless to consider guardrail moderation as a clutch at straws towards harmful fine-tuning attack}, as it cannot solve the inherent safety issue of the pre-trained LLMs. Our code is available at https://github.com/git-disl/Virus
$H^3$Fusion: Helpful, Harmless, Honest Fusion of Aligned LLMs
Nov 26, 2024



Alignment of pretrained LLMs using instruction-based datasets is critical for creating fine-tuned models that reflect human preference. A growing number of alignment-based fine-tuning algorithms and benchmarks emerged recently, fueling the efforts on effective alignments of pre-trained LLMs to ensure helpful, harmless, and honest answers from both open-source and closed-source LLMs. This paper tackles this problem by developing an alignment fusion approach, coined as $H^3$Fusion, with three unique characteristics. First, $H^3$Fusion ensembles multiple individually aligned LLMs to create a final fine-tuned alignment model with enhanced capabilities beyond those of individual models, delivering robust alignment through promoting helpful, harmless, honest fusion. Second, $H^3$Fusion leverages the mixture-of-experts (MoE) methodology in two steps. We first freeze the multi-head attention weights of each individual model while tuning the FFN layer during alignment fusion. Then we merge the aligned model weights with an expert router according to the type of input instruction and dynamically select a subset of experts that are best suited for producing the output response. Finally, we boost the performance of the resulting $H^3$3Fusion model by introducing gating loss and regularization terms. The former penalizes the selection errors of the expert-router, and the latter mediates the expert weights drifting during fine-tuning and dynamically adjusts the fusion behavior of the resulting model by canalizing the activations on the experts. Extensive evaluations on three benchmark datasets show that $H^3$3Fusion is more helpful, less harmful, and more honest from two aspects: it outperforms each individually aligned model by $11.37\%$, and it provides stronger robustness compared to the state-of-the-art LLM ensemble approaches by $13.77\%$. Code is available at github.com/sftekin/h3fusion.
LLM-TOPLA: Efficient LLM Ensemble by Maximising Diversity
Oct 04, 2024
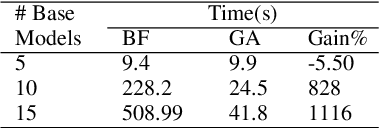
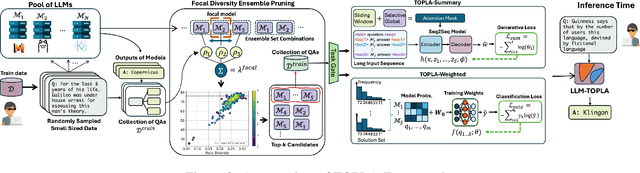
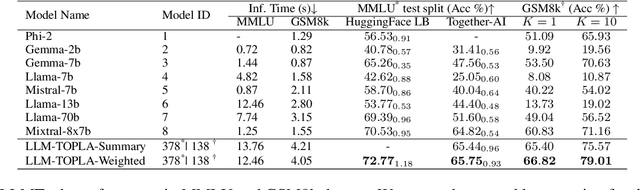
Combining large language models during training or at inference time has shown substantial performance gain over component LLMs. This paper presents LLM-TOPLA, a diversity-optimized LLM ensemble method with three unique properties: (i) We introduce the focal diversity metric to capture the diversity-performance correlation among component LLMs of an ensemble. (ii) We develop a diversity-optimized ensemble pruning algorithm to select the top-k sub-ensembles from a pool of $N$ base LLMs. Our pruning method recommends top-performing LLM subensembles of size $S$, often much smaller than $N$. (iii) We generate new output for each prompt query by utilizing a learn-to-ensemble approach, which learns to detect and resolve the output inconsistency among all component LLMs of an ensemble. Extensive evaluation on four different benchmarks shows good performance gain over the best LLM ensemble methods: (i) In constrained solution set problems, LLM-TOPLA outperforms the best-performing ensemble (Mixtral) by 2.2\% in accuracy on MMLU and the best-performing LLM ensemble (MoreAgent) on GSM8k by 2.1\%. (ii) In generative tasks, LLM-TOPLA outperforms the top-2 performers (Llama70b/Mixtral) on SearchQA by $3.9\mathrm{x}$ in F1, and on XSum by more than $38$ in ROUGE-1. Our code and dataset, which contains outputs of 8 modern LLMs on 4 benchmarks is available at https://github.com/git-disl/llm-topla
Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey
Sep 26, 2024Recent research demonstrates that the nascent fine-tuning-as-a-service business model exposes serious safety concerns -- fine-tuning over a few harmful data uploaded by the users can compromise the safety alignment of the model. The attack, known as harmful fine-tuning, has raised a broad research interest among the community. However, as the attack is still new, \textbf{we observe from our miserable submission experience that there are general misunderstandings within the research community.} We in this paper aim to clear some common concerns for the attack setting, and formally establish the research problem. Specifically, we first present the threat model of the problem, and introduce the harmful fine-tuning attack and its variants. Then we systematically survey the existing literature on attacks/defenses/mechanical analysis of the problem. Finally, we outline future research directions that might contribute to the development of the field. Additionally, we present a list of questions of interest, which might be useful to refer to when reviewers in the peer review process question the realism of the experiment/attack/defense setting. A curated list of relevant papers is maintained and made accessible at: \url{https://github.com/git-disl/awesome_LLM-harmful-fine-tuning-papers.}
Booster: Tackling Harmful Fine-tuning for Large Language Models via Attenuating Harmful Perturbation
Sep 04, 2024Harmful fine-tuning issue \citep{qi2023fine} poses serious safety concerns for Large language models' fine-tuning-as-a-service. While existing defenses \citep{huang2024vaccine,rosati2024representation} have been proposed to mitigate the issue, their performances are still far away from satisfactory, and the root cause of the problem has not been fully recovered. For the first time in the literature, we in this paper show that \textit{harmful perturbation} over the model weights should be the root cause of alignment-broken of harmful fine-tuning. In order to attenuate the negative impact of harmful perturbation, we propose an alignment-stage solution, dubbed Booster. Technically, along with the original alignment loss, we append a loss regularizer in the alignment stage's optimization. The regularizer ensures that the model's harmful loss reduction before/after simulated harmful perturbation is attenuated, thereby mitigating the subsequent fine-tuning risk. Empirical results show that Booster can effectively reduce the harmful score of the fine-tuned models while maintaining the performance of downstream tasks. Our code is available at \url{https://github.com/git-disl/Booster}.
Booster: Tackling Harmful Fine-tuing for Large Language Models via Attenuating Harmful Perturbation
Sep 03, 2024Harmful fine-tuning issue \citep{qi2023fine} poses serious safety concerns for Large language models' fine-tuning-as-a-service. While existing defenses \citep{huang2024vaccine,rosati2024representation} have been proposed to mitigate the issue, their performances are still far away from satisfactory, and the root cause of the problem has not been fully recovered. For the first time in the literature, we in this paper show that \textit{harmful perturbation} over the model weights should be the root cause of alignment-broken of harmful fine-tuning. In order to attenuate the negative impact of harmful perturbation, we propose an alignment-stage solution, dubbed Booster. Technically, along with the original alignment loss, we append a loss regularizer in the alignment stage's optimization. The regularizer ensures that the model's harmful loss reduction before/after simulated harmful perturbation is attenuated, thereby mitigating the subsequent fine-tuning risk. Empirical results show that Booster can effectively reduce the harmful score of the fine-tuned models while maintaining the performance of downstream tasks. Our code is available at \url{https://github.com/git-disl/Booster}.