 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-TOPLA: Efficient LLM Ensemble by Maximising Diversity
Paper and Code

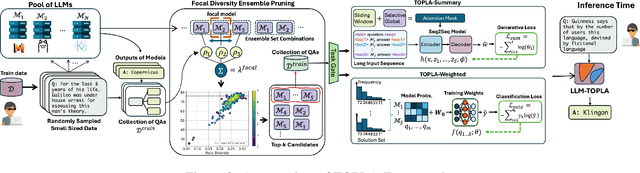
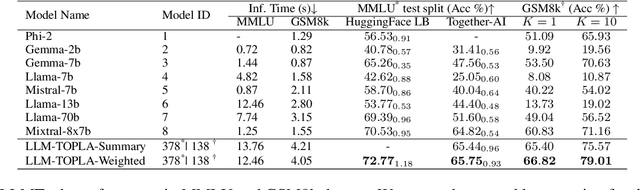
Combining large language models during training or at inference time has shown substantial performance gain over component LLMs. This paper presents LLM-TOPLA, a diversity-optimized LLM ensemble method with three unique properties: (i) We introduce the focal diversity metric to capture the diversity-performance correlation among component LLMs of an ensemble. (ii) We develop a diversity-optimized ensemble pruning algorithm to select the top-k sub-ensembles from a pool of $N$ base LLMs. Our pruning method recommends top-performing LLM subensembles of size $S$, often much smaller than $N$. (iii) We generate new output for each prompt query by utilizing a learn-to-ensemble approach, which learns to detect and resolve the output inconsistency among all component LLMs of an ensemble. Extensive evaluation on four different benchmarks shows good performance gain over the best LLM ensemble methods: (i) In constrained solution set problems, LLM-TOPLA outperforms the best-performing ensemble (Mixtral) by 2.2\% in accuracy on MMLU and the best-performing LLM ensemble (MoreAgent) on GSM8k by 2.1\%. (ii) In generative tasks, LLM-TOPLA outperforms the top-2 performers (Llama70b/Mixtral) on SearchQA by $3.9\mathrm{x}$ in F1, and on XSum by more than $38$ in ROUGE-1. Our code and dataset, which contains outputs of 8 modern LLMs on 4 benchmarks is available at https://github.com/git-disl/llm-topla