 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Still Face Challenges in Multi-Hop Reasoning with External Knowledge
Dec 11, 2024



We carry out a series of experiments to test large language models' multi-hop reasoning ability from three aspects: selecting and combining external knowledge, dealing with non-sequential reasoning tasks and generalising to data samples with larger numbers of hops. We test the GPT-3.5 model on four reasoning benchmarks with Chain-of-Thought prompting (and its variations). Our results reveal that despite the amazing performance achieved by large language models on various reasoning tasks, models still suffer from severe drawbacks which shows a large gap with humans.
Img2CAD: Reverse Engineering 3D CAD Models from Images through VLM-Assisted Conditional Factorization
Jul 19, 2024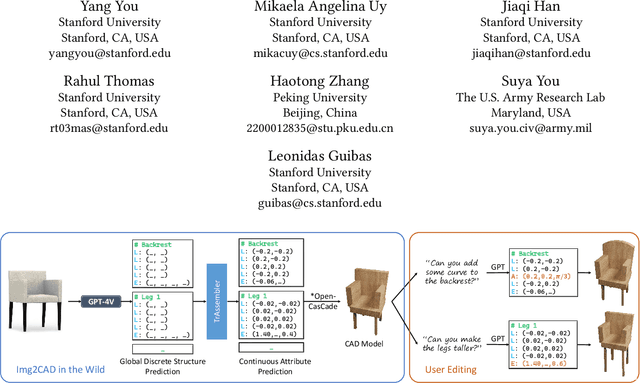
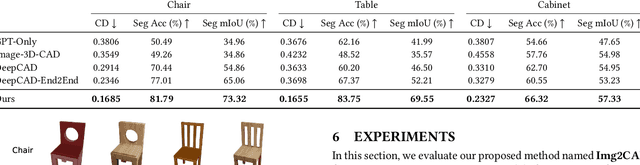
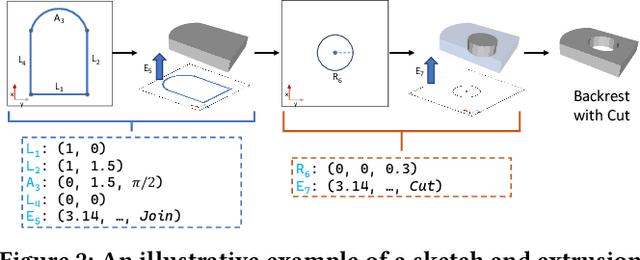

Reverse engineering 3D computer-aided design (CAD) models from images is an important task for many downstream applications including interactive editing, manufacturing, architecture, robotics, etc. The difficulty of the task lies in vast representational disparities between the CAD output and the image input. CAD models are precise, programmatic constructs that involves sequential operations combining discrete command structure with continuous attributes -- making it challenging to learn and optimize in an end-to-end fashion. Concurrently, input images introduce inherent challenges such as photo-metric variability and sensor noise, complicating the reverse engineering process. In this work, we introduce a novel approach that conditionally factorizes the task into two sub-problems. First, we leverage large foundation models, particularly GPT-4V, to predict the global discrete base structure with semantic information. Second, we propose TrAssembler that conditioned on the discrete structure with semantics predicts the continuous attribute values. To support the training of our TrAssembler, we further constructed an annotated CAD dataset of common objects from ShapeNet. Putting all together, our approach and data demonstrate significant first steps towards CAD-ifying images in the wild. Our project page: https://anonymous123342.github.io/
SparseDFF: Sparse-View Feature Distillation for One-Shot Dexterous Manipulation
Oct 25, 2023



Humans excel at transferring manipulation skills across diverse object shapes, poses, and appearances due to their understanding of semantic correspondences between different instances. To endow robots with a similar high-level understanding, we develop a Distilled Feature Field (DFF) for 3D scenes, leveraging large 2D vision models to distill semantic features from multiview images. While current research demonstrates advanced performance in reconstructing DFFs from dense views, the development of learning a DFF from sparse views is relatively nascent, despite its prevalence in numerous manipulation tasks with fixed cameras. In this work, we introduce SparseDFF, a novel method for acquiring view-consistent 3D DFFs from sparse RGBD observations, enabling one-shot learning of dexterous manipulations that are transferable to novel scenes. Specifically, we map the image features to the 3D point cloud, allowing for propagation across the 3D space to establish a dense feature field. At the core of SparseDFF is a lightweight feature refinement network, optimized with a contrastive loss between pairwise views after back-projecting the image features onto the 3D point cloud. Additionally, we implement a point-pruning mechanism to augment feature continuity within each local neighborhood. By establishing coherent feature fields on both source and target scenes, we devise an energy function that facilitates the minimization of feature discrepancies w.r.t. the end-effector parameters between the demonstration and the target manipulation. We evaluate our approach using a dexterous hand, mastering real-world manipulations on both rigid and deformable objects, and showcase robust generalization in the face of object and scene-context variations.
SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting
Aug 22, 2023



RNN-based methods have faced challenges in the Long-term Time Series Forecasting (LTSF) domain when dealing with excessively long look-back windows and forecast horizons. Consequently, the dominance in this domain has shifted towards Transformer, MLP, and CNN approaches. The substantial number of recurrent iterations are the fundamental reasons behind the limitations of RNNs in LTSF. To address these issues, we propose two novel strategies to reduce the number of iterations in RNNs for LTSF tasks: Segment-wise Iterations and Parallel Multi-step Forecasting (PMF). RNNs that combine these strategies, namely SegRNN, significantly reduce the required recurrent iterations for LTSF, resulting in notable improvements in forecast accuracy and inference speed. Extensive experiments demonstrate that SegRNN not only outperforms SOTA Transformer-based models but also reduces runtime and memory usage by more than 78%. These achievements provide strong evidence that RNNs continue to excel in LTSF tasks and encourage further exploration of this domain with more RNN-based approaches. The source code is coming soon.
Weakly-Supervised Dense Action Anticipation
Nov 15, 2021

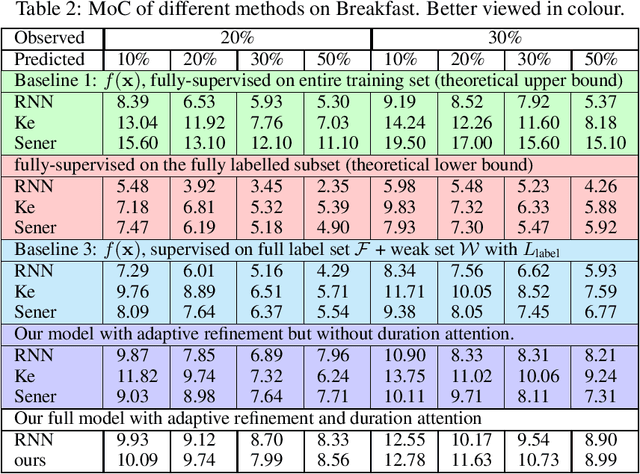
Dense anticipation aims to forecast future actions and their durations for long horizons. Existing approaches rely on fully-labelled data, i.e. sequences labelled with all future actions and their durations. We present a (semi-) weakly supervised method using only a small number of fully-labelled sequences and predominantly sequences in which only the (one) upcoming action is labelled. To this end, we propose a framework that generates pseudo-labels for future actions and their durations and adaptively refines them through a refinement module. Given only the upcoming action label as input, these pseudo-labels guide action/duration prediction for the future. We further design an attention mechanism to predict context-aware durations. Experiments on the Breakfast and 50Salads benchmarks verify our method's effectiveness; we are competitive even when compared to fully supervised state-of-the-art models. We will make our code available at: https://github.com/zhanghaotong1/WSLVideoDenseAnticipation.