 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Convex Decomposition via Feature Fields
Mar 10, 2026This work proposes a new formulation to the long-standing problem of convex decomposition through learning feature fields, enabling the first feed-forward model for open-world convex decomposition. Our method produces high-quality decompositions of 3D shapes into a union of convex bodies, which are essential to accelerate collision detection in physical simulation, amongst many other applications. The key insight is to adopt a feature learning approach and learn a continuous feature field that can later be clustered to yield a good convex decomposition via our self-supervised, purely-geometric objective derived from the classical definition of convexity. Our formulation can be used for single shape optimization, but more importantly, feature prediction unlocks scalable, self-supervised learning on large datasets resulting in the first learned open-world model for convex decomposition. Experiments show that our decompositions are higher-quality than alternatives and generalize across open-world objects as well as across representations to meshes, CAD models, and even Gaussian splats. https://research.nvidia.com/labs/sil/projects/learning-convex-decomp/
Perspective-Aware Reasoning in Vision-Language Models via Mental Imagery Simulation
Apr 24, 2025We present a framework for perspective-aware reasoning in vision-language models (VLMs) through mental imagery simulation. Perspective-taking, the ability to perceive an environment or situation from an alternative viewpoint, is a key benchmark for human-level visual understanding, essential for environmental interaction and collaboration with autonomous agents. Despite advancements in spatial reasoning within VLMs, recent research has shown that modern VLMs significantly lack perspective-aware reasoning capabilities and exhibit a strong bias toward egocentric interpretations. To bridge the gap between VLMs and human perception, we focus on the role of mental imagery, where humans perceive the world through abstracted representations that facilitate perspective shifts. Motivated by this, we propose a framework for perspective-aware reasoning, named Abstract Perspective Change (APC), that effectively leverages vision foundation models, such as object detection, segmentation, and orientation estimation, to construct scene abstractions and enable perspective transformations. Our experiments on synthetic and real-image benchmarks, compared with various VLMs, demonstrate significant improvements in perspective-aware reasoning with our framework, further outperforming fine-tuned spatial reasoning models and novel-view-synthesis-based approaches.
PARTFIELD: Learning 3D Feature Fields for Part Segmentation and Beyond
Apr 15, 2025We propose PartField, a feedforward approach for learning part-based 3D features, which captures the general concept of parts and their hierarchy without relying on predefined templates or text-based names, and can be applied to open-world 3D shapes across various modalities. PartField requires only a 3D feedforward pass at inference time, significantly improving runtime and robustness compared to prior approaches. Our model is trained by distilling 2D and 3D part proposals from a mix of labeled datasets and image segmentations on large unsupervised datasets, via a contrastive learning formulation. It produces a continuous feature field which can be clustered to yield a hierarchical part decomposition. Comparisons show that PartField is up to 20% more accurate and often orders of magnitude faster than other recent class-agnostic part-segmentation methods. Beyond single-shape part decomposition, consistency in the learned field emerges across shapes, enabling tasks such as co-segmentation and correspondence, which we demonstrate in several applications of these general-purpose, hierarchical, and consistent 3D feature fields. Check our Webpage! https://research.nvidia.com/labs/toronto-ai/partfield-release/
Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Dec 05, 2024
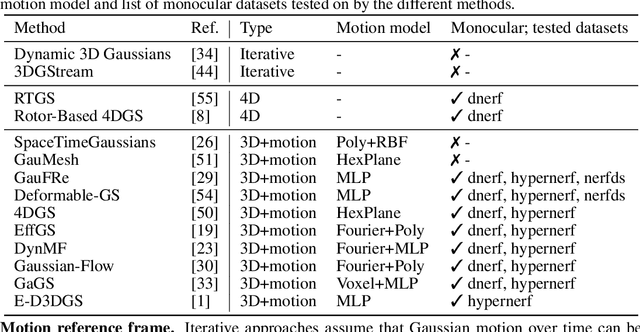

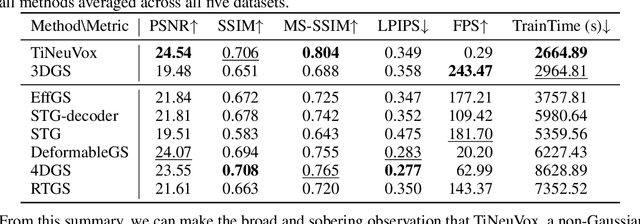
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data -- an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
Img2CAD: Reverse Engineering 3D CAD Models from Images through VLM-Assisted Conditional Factorization
Jul 19, 2024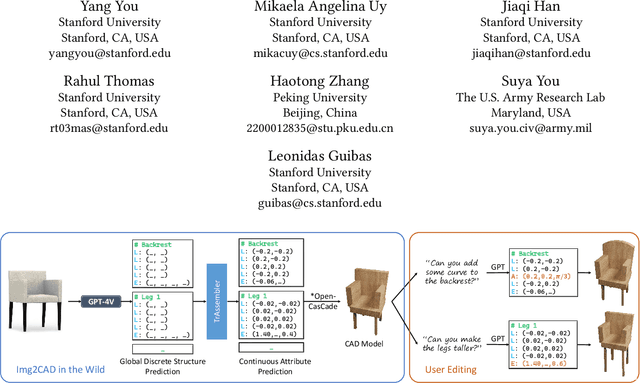
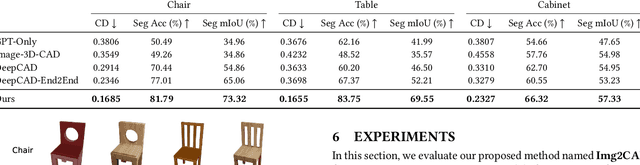

Reverse engineering 3D computer-aided design (CAD) models from images is an important task for many downstream applications including interactive editing, manufacturing, architecture, robotics, etc. The difficulty of the task lies in vast representational disparities between the CAD output and the image input. CAD models are precise, programmatic constructs that involves sequential operations combining discrete command structure with continuous attributes -- making it challenging to learn and optimize in an end-to-end fashion. Concurrently, input images introduce inherent challenges such as photo-metric variability and sensor noise, complicating the reverse engineering process. In this work, we introduce a novel approach that conditionally factorizes the task into two sub-problems. First, we leverage large foundation models, particularly GPT-4V, to predict the global discrete base structure with semantic information. Second, we propose TrAssembler that conditioned on the discrete structure with semantics predicts the continuous attribute values. To support the training of our TrAssembler, we further constructed an annotated CAD dataset of common objects from ShapeNet. Putting all together, our approach and data demonstrate significant first steps towards CAD-ifying images in the wild. Our project page: https://anonymous123342.github.io/
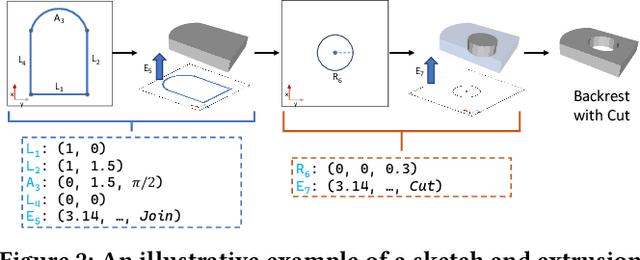
MV2Cyl: Reconstructing 3D Extrusion Cylinders from Multi-View Images
Jun 16, 2024We present MV2Cyl, a novel method for reconstructing 3D from 2D multi-view images, not merely as a field or raw geometry but as a sketch-extrude CAD model. Extracting extrusion cylinders from raw 3D geometry has been extensively researched in computer vision, while the processing of 3D data through neural networks has remained a bottleneck. Since 3D scans are generally accompanied by multi-view images, leveraging 2D convolutional neural networks allows these images to be exploited as a rich source for extracting extrusion cylinder information. However, we observe that extracting only the surface information of the extrudes and utilizing it results in suboptimal outcomes due to the challenges in the occlusion and surface segmentation. By synergizing with the extracted base curve information, we achieve the optimal reconstruction result with the best accuracy in 2D sketch and extrude parameter estimation. Our experiments, comparing our method with previous work that takes a raw 3D point cloud as input, demonstrate the effectiveness of our approach by taking advantage of multi-view images.
ProvNeRF: Modeling per Point Provenance in NeRFs as a Stochastic Process
Jan 18, 2024Neural radiance fields (NeRFs) have gained popularity across various applications. However, they face challenges in the sparse view setting, lacking sufficient constraints from volume rendering. Reconstructing and understanding a 3D scene from sparse and unconstrained cameras is a long-standing problem in classical computer vision with diverse applications. While recent works have explored NeRFs in sparse, unconstrained view scenarios, their focus has been primarily on enhancing reconstruction and novel view synthesis. Our approach takes a broader perspective by posing the question: "from where has each point been seen?" -- which gates how well we can understand and reconstruct it. In other words, we aim to determine the origin or provenance of each 3D point and its associated information under sparse, unconstrained views. We introduce ProvNeRF, a model that enriches a traditional NeRF representation by incorporating per-point provenance, modeling likely source locations for each point. We achieve this by extending implicit maximum likelihood estimation (IMLE) for stochastic processes. Notably, our method is compatible with any pre-trained NeRF model and the associated training camera poses. We demonstrate that modeling per-point provenance offers several advantages, including uncertainty estimation, criteria-based view selection, and improved novel view synthesis, compared to state-of-the-art methods. Please visit our project page at https://provnerf.github.io
NeRF Revisited: Fixing Quadrature Instability in Volume Rendering
Oct 31, 2023



Neural radiance fields (NeRF) rely on volume rendering to synthesize novel views. Volume rendering requires evaluating an integral along each ray, which is numerically approximated with a finite sum that corresponds to the exact integral along the ray under piecewise constant volume density. As a consequence, the rendered result is unstable w.r.t. the choice of samples along the ray, a phenomenon that we dub quadrature instability. We propose a mathematically principled solution by reformulating the sample-based rendering equation so that it corresponds to the exact integral under piecewise linear volume density. This simultaneously resolves multiple issues: conflicts between samples along different rays, imprecise hierarchical sampling, and non-differentiability of quantiles of ray termination distances w.r.t. model parameters. We demonstrate several benefits over the classical sample-based rendering equation, such as sharper textures, better geometric reconstruction, and stronger depth supervision. Our proposed formulation can be also be used as a drop-in replacement to the volume rendering equation of existing NeRF-based methods. Our project page can be found at pl-nerf.github.io.
DiffFacto: Controllable Part-Based 3D Point Cloud Generation with Cross Diffusion
May 04, 2023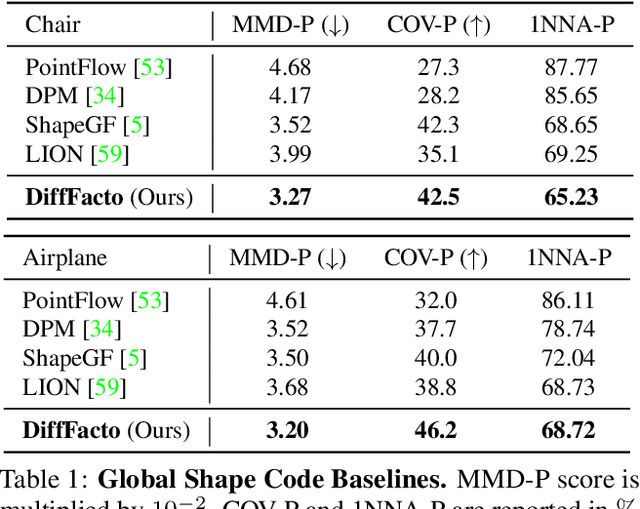
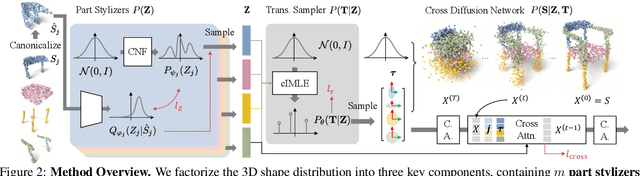

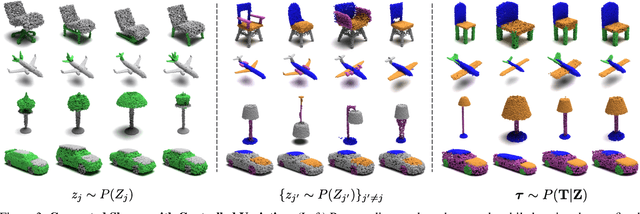
While the community of 3D point cloud generation has witnessed a big growth in recent years, there still lacks an effective way to enable intuitive user control in the generation process, hence limiting the general utility of such methods. Since an intuitive way of decomposing a shape is through its parts, we propose to tackle the task of controllable part-based point cloud generation. We introduce DiffFacto, a novel probabilistic generative model that learns the distribution of shapes with part-level control. We propose a factorization that models independent part style and part configuration distributions and presents a novel cross-diffusion network that enables us to generate coherent and plausible shapes under our proposed factorization. Experiments show that our method is able to generate novel shapes with multiple axes of control. It achieves state-of-the-art part-level generation quality and generates plausible and coherent shapes while enabling various downstream editing applications such as shape interpolation, mixing, and transformation editing. Project website: https://difffacto.github.io/
SCADE: NeRFs from Space Carving with Ambiguity-Aware Depth Estimates
Mar 23, 2023Neural radiance fields (NeRFs) have enabled high fidelity 3D reconstruction from multiple 2D input views. However, a well-known drawback of NeRFs is the less-than-ideal performance under a small number of views, due to insufficient constraints enforced by volumetric rendering. To address this issue, we introduce SCADE, a novel technique that improves NeRF reconstruction quality on sparse, unconstrained input views for in-the-wild indoor scenes. To constrain NeRF reconstruction, we leverage geometric priors in the form of per-view depth estimates produced with state-of-the-art monocular depth estimation models, which can generalize across scenes. A key challenge is that monocular depth estimation is an ill-posed problem, with inherent ambiguities. To handle this issue, we propose a new method that learns to predict, for each view, a continuous, multimodal distribution of depth estimates using conditional Implicit Maximum Likelihood Estimation (cIMLE). In order to disambiguate exploiting multiple views, we introduce an original space carving loss that guides the NeRF representation to fuse multiple hypothesized depth maps from each view and distill from them a common geometry that is consistent with all views. Experiments show that our approach enables higher fidelity novel view synthesis from sparse views. Our project page can be found at https://scade-spacecarving-nerfs.github.io .