 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneTeract: Agentic Functional Affordances and VLM Grounding in 3D Scenes
Mar 31, 2026Embodied AI depends on interactive 3D environments that support meaningful activities for diverse users, yet assessing their functional affordances remains a core challenge. We introduce SceneTeract, a framework that verifies 3D scene functionality under agent-specific constraints. Our core contribution is a grounded verification engine that couples high-level semantic reasoning with low-level geometric checks. SceneTeract decomposes complex activities into sequences of atomic actions and validates each step against accessibility requirements (e.g., reachability, clearance, and navigability) conditioned on an embodied agent profile, using explicit physical and geometric simulations. We deploy SceneTeract to perform an in-depth evaluation of (i) synthetic indoor environments, uncovering frequent functional failures that prevent basic interactions, and (ii) the ability of frontier Vision-Language Models (VLMs) to reason about and predict functional affordances, revealing systematic mismatches between semantic confidence and physical feasibility even for the strongest current models. Finally, we leverage SceneTeract as a reward engine for VLM post-training, enabling scalable distillation of geometric constraints into reasoning models. We release the SceneTeract verification suite and data to bridge perception and physical reality in embodied 3D scene understanding.
LookOut: Real-World Humanoid Egocentric Navigation
Aug 20, 2025The ability to predict collision-free future trajectories from egocentric observations is crucial in applications such as humanoid robotics, VR / AR, and assistive navigation. In this work, we introduce the challenging problem of predicting a sequence of future 6D head poses from an egocentric video. In particular, we predict both head translations and rotations to learn the active information-gathering behavior expressed through head-turning events. To solve this task, we propose a framework that reasons over temporally aggregated 3D latent features, which models the geometric and semantic constraints for both the static and dynamic parts of the environment. Motivated by the lack of training data in this space, we further contribute a data collection pipeline using the Project Aria glasses, and present a dataset collected through this approach. Our dataset, dubbed Aria Navigation Dataset (AND), consists of 4 hours of recording of users navigating in real-world scenarios. It includes diverse situations and navigation behaviors, providing a valuable resource for learning real-world egocentric navigation policies. Extensive experiments show that our model learns human-like navigation behaviors such as waiting / slowing down, rerouting, and looking around for traffic while generalizing to unseen environments. Check out our project webpage at https://sites.google.com/stanford.edu/lookout.
Animal Pose Labeling Using General-Purpose Point Trackers
Jun 04, 2025Automatically estimating animal poses from videos is important for studying animal behaviors. Existing methods do not perform reliably since they are trained on datasets that are not comprehensive enough to capture all necessary animal behaviors. However, it is very challenging to collect such datasets due to the large variations in animal morphology. In this paper, we propose an animal pose labeling pipeline that follows a different strategy, i.e. test time optimization. Given a video, we fine-tune a lightweight appearance embedding inside a pre-trained general-purpose point tracker on a sparse set of annotated frames. These annotations can be obtained from human labelers or off-the-shelf pose detectors. The fine-tuned model is then applied to the rest of the frames for automatic labeling. Our method achieves state-of-the-art performance at a reasonable annotation cost. We believe our pipeline offers a valuable tool for the automatic quantification of animal behavior. Visit our project webpage at https://zhuoyang-pan.github.io/animal-labeling.
MultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024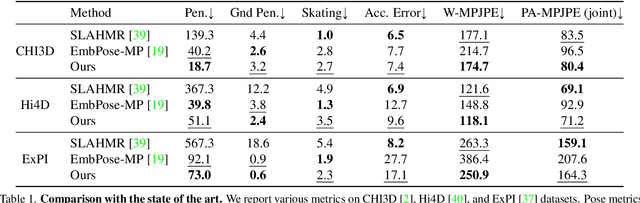

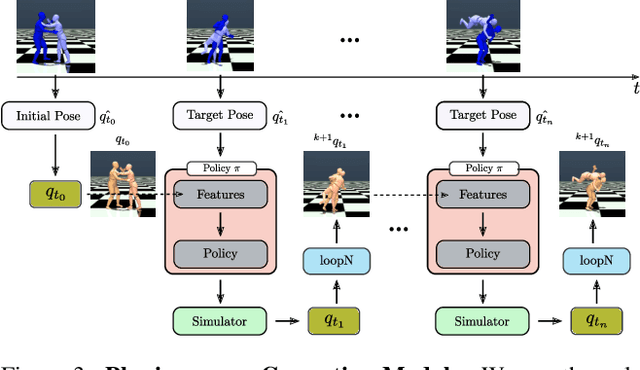
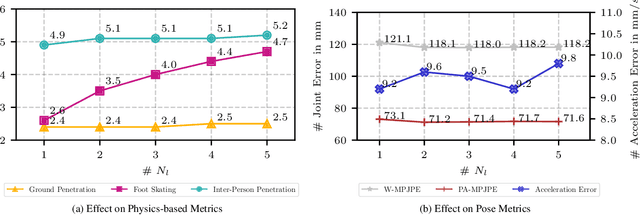
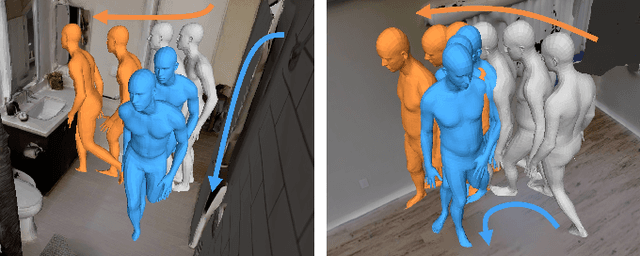
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
ActAnywhere: Subject-Aware Video Background Generation
Jan 19, 2024Generating video background that tailors to foreground subject motion is an important problem for the movie industry and visual effects community. This task involves synthesizing background that aligns with the motion and appearance of the foreground subject, while also complies with the artist's creative intention. We introduce ActAnywhere, a generative model that automates this process which traditionally requires tedious manual efforts. Our model leverages the power of large-scale video diffusion models, and is specifically tailored for this task. ActAnywhere takes a sequence of foreground subject segmentation as input and an image that describes the desired scene as condition, to produce a coherent video with realistic foreground-background interactions while adhering to the condition frame. We train our model on a large-scale dataset of human-scene interaction videos. Extensive evaluations demonstrate the superior performance of our model, significantly outperforming baselines. Moreover, we show that ActAnywhere generalizes to diverse out-of-distribution samples, including non-human subjects. Please visit our project webpage at https://actanywhere.github.io.
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Apr 01, 2023We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also semantic correlations between scene points, regions, or entities -- aiming to capture their mutual co-variation patterns. In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highly-correlated entities, which proves to maximize the mutual information between them under random scene perturbations. By paying attention to this second-order information, we can shape a NeRF to express semantically meaningful synergies when the network weights are changed by a delta along the gradient of a single entity, region, or even a point. To demonstrate the merit of this mutual information modeling, we leverage the coordinated behavior of scene entities that emerges from our shaping to perform label propagation for semantic and instance segmentation. Our experiments show that a JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes -- thus reducing annotation burden. The same machinery can further be used for entity selection or scene modifications.
PartNeRF: Generating Part-Aware Editable 3D Shapes without 3D Supervision
Mar 21, 2023Impressive progress in generative models and implicit representations gave rise to methods that can generate 3D shapes of high quality. However, being able to locally control and edit shapes is another essential property that can unlock several content creation applications. Local control can be achieved with part-aware models, but existing methods require 3D supervision and cannot produce textures. In this work, we devise PartNeRF, a novel part-aware generative model for editable 3D shape synthesis that does not require any explicit 3D supervision. Our model generates objects as a set of locally defined NeRFs, augmented with an affine transformation. This enables several editing operations such as applying transformations on parts, mixing parts from different objects etc. To ensure distinct, manipulable parts we enforce a hard assignment of rays to parts that makes sure that the color of each ray is only determined by a single NeRF. As a result, altering one part does not affect the appearance of the others. Evaluations on various ShapeNet categories demonstrate the ability of our model to generate editable 3D objects of improved fidelity, compared to previous part-based generative approaches that require 3D supervision or models relying on NeRFs.
COPILOT: Human Collision Prediction and Localization from Multi-view Egocentric Videos
Oct 04, 2022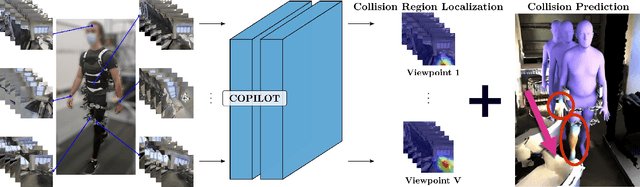
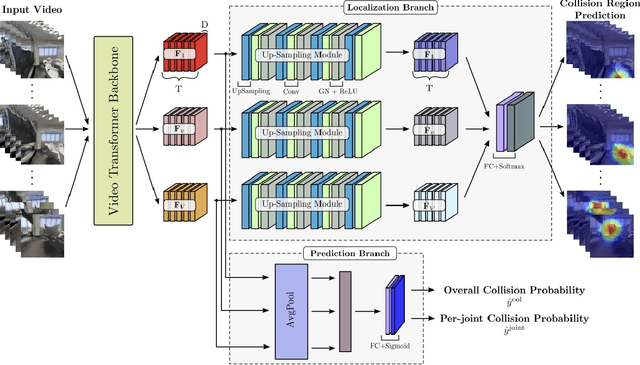
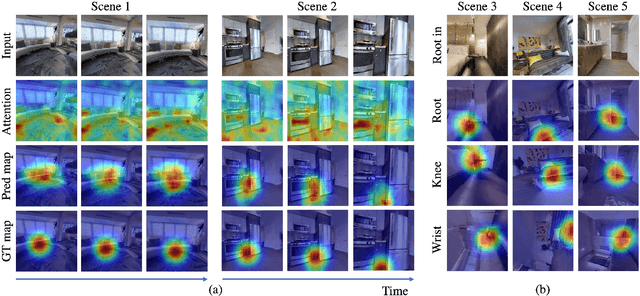
To produce safe human motions, assistive wearable exoskeletons must be equipped with a perception system that enables anticipating potential collisions from egocentric observations. However, previous approaches to exoskeleton perception greatly simplify the problem to specific types of environments, limiting their scalability. In this paper, we propose the challenging and novel problem of predicting human-scene collisions for diverse environments from multi-view egocentric RGB videos captured from an exoskeleton. By classifying which body joints will collide with the environment and predicting a collision region heatmap that localizes potential collisions in the environment, we aim to develop an exoskeleton perception system that generalizes to complex real-world scenes and provides actionable outputs for downstream control. We propose COPILOT, a video transformer-based model that performs both collision prediction and localization simultaneously, leveraging multi-view video inputs via a proposed joint space-time-viewpoint attention operation. To train and evaluate the model, we build a synthetic data generation framework to simulate virtual humans moving in photo-realistic 3D environments. This framework is then used to establish a dataset consisting of 8.6M egocentric RGBD frames to enable future work on the problem. Extensive experiments suggest that our model achieves promising performance and generalizes to unseen scenes as well as real world. We apply COPILOT to a downstream collision avoidance task, and successfully reduce collision cases by 29% on unseen scenes using a simple closed-loop control algorithm.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
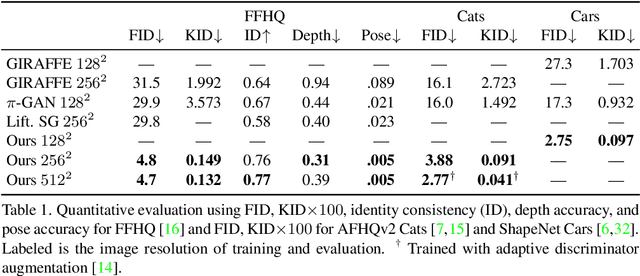
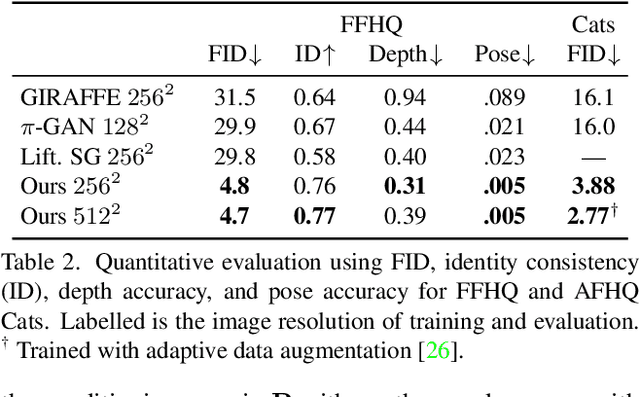
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
Mar 31, 2020
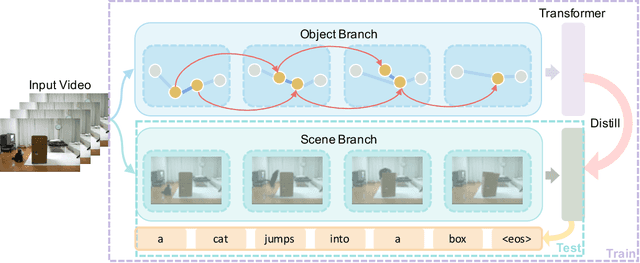
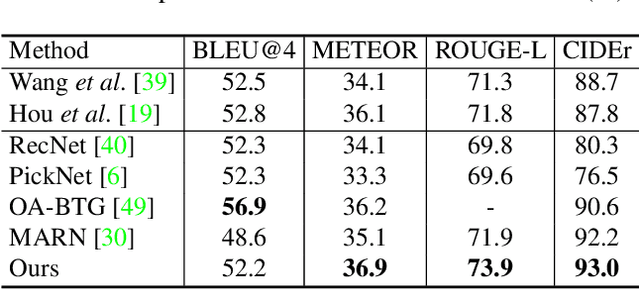

Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.