 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graph for Video Captioning with Knowledge Distillation
Mar 31, 2020
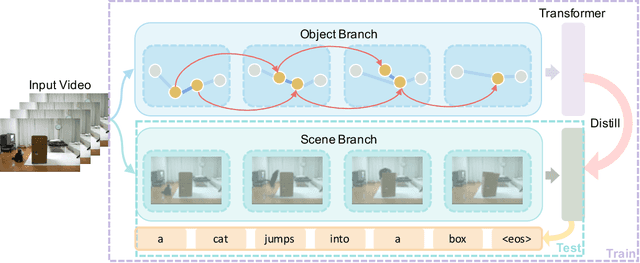
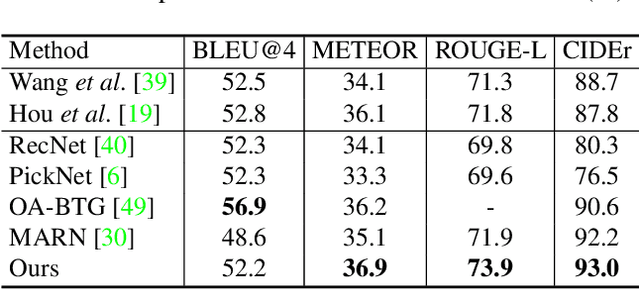

Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.
Deep Video Generation, Prediction and Completion of Human Action Sequences
Dec 08, 2017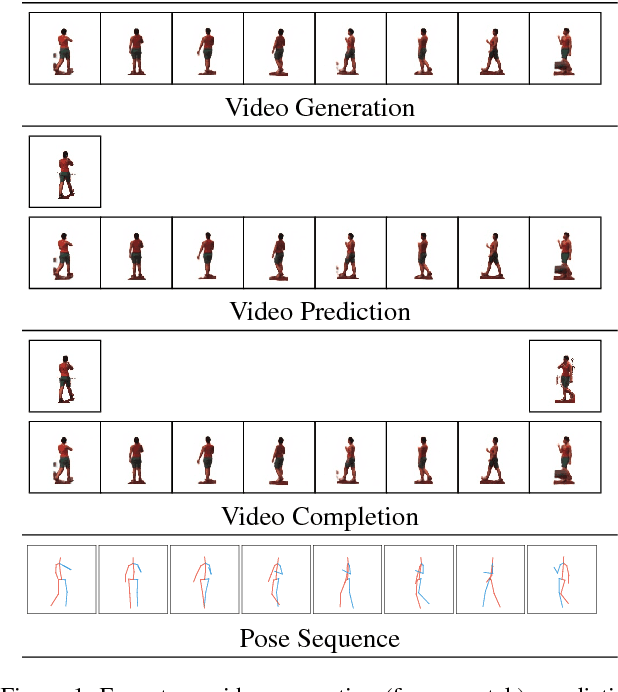

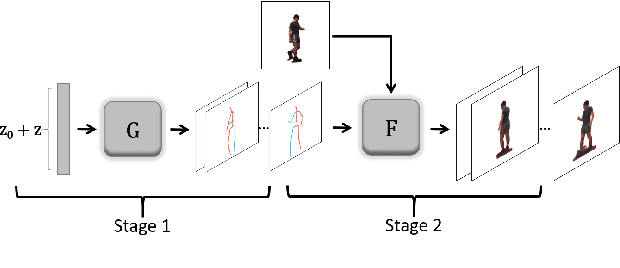
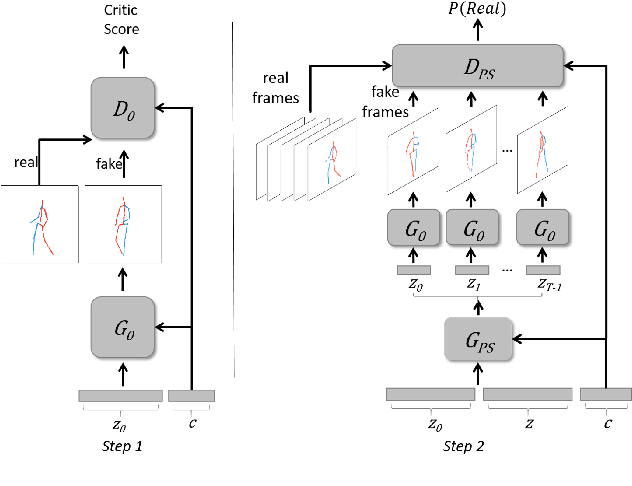
Current deep learning results on video generation are limited while there are only a few first results on video prediction and no relevant significant results on video completion. This is due to the severe ill-posedness inherent in these three problems. In this paper, we focus on human action videos, and propose a general, two-stage deep framework to generate human action videos with no constraints or arbitrary number of constraints, which uniformly address the three problems: video generation given no input frames, video prediction given the first few frames, and video completion given the first and last frames. To make the problem tractable, in the first stage we train a deep generative model that generates a human pose sequence from random noise. In the second stage, a skeleton-to-image network is trained, which is used to generate a human action video given the complete human pose sequence generated in the first stage. By introducing the two-stage strategy, we sidestep the original ill-posed problems while producing for the first time high-quality video generation/prediction/completion results of much longer duration. We present quantitative and qualitative evaluation to show that our two-stage approach outperforms state-of-the-art methods in video generation, prediction and video completion. Our video result demonstration can be viewed at https://iamacewhite.github.io/supp/index.html