 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Bias in LLMs: A Survey
Mar 04, 2025Due to the implement of guardrails by developers, Large language models (LLMs) have demonstrated exceptional performance in explicit bias tests. However, bias in LLMs may occur not only explicitly, but also implicitly, much like humans who consciously strive for impartiality yet still harbor implicit bias. The unconscious and automatic nature of implicit bias makes it particularly challenging to study. This paper provides a comprehensive review of the existing literature on implicit bias in LLMs. We begin by introducing key concepts, theories and methods related to implicit bias in psychology, extending them from humans to LLMs. Drawing on the Implicit Association Test (IAT) and other psychological frameworks, we categorize detection methods into three primary approaches: word association, task-oriented text generation and decision-making. We divide our taxonomy of evaluation metrics for implicit bias into two categories: single-value-based metrics and comparison-value-based metrics. We classify datasets into two types: sentences with masked tokens and complete sentences, incorporating datasets from various domains to reflect the broad application of LLMs. Although research on mitigating implicit bias in LLMs is still limited, we summarize existing efforts and offer insights on future challenges. We aim for this work to serve as a clear guide for researchers and inspire innovative ideas to advance exploration in this task.
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 25, 2023
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), the Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that the Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of the Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. This suggests that it is feasible to use LLM-assisted annotation for local grammar analysis, together with human intervention on tags that are less accurately recognized by machine. We strongly advocate conducting future studies to evaluate the performance of LLMs in annotating other linguistic phenomena. These studies have the potential to offer valuable insights into the advancement of theories developed in corpus linguistics, as well into the linguistic capabilities of LLMs..
PSNet: Fast Data Structuring for Hierarchical Deep Learning on Point Cloud
May 31, 2022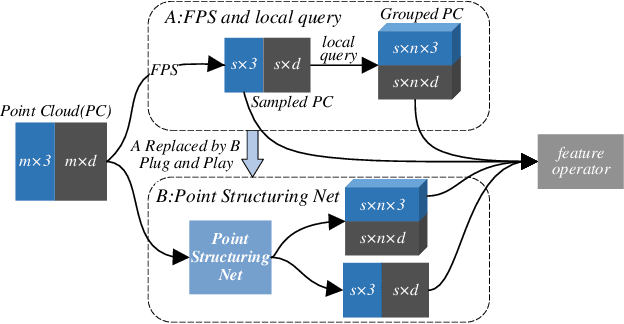
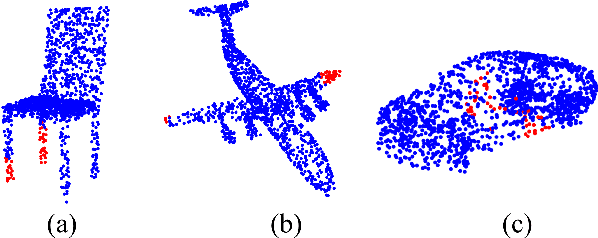
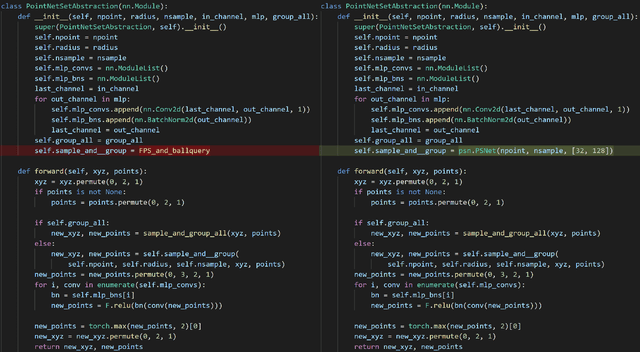
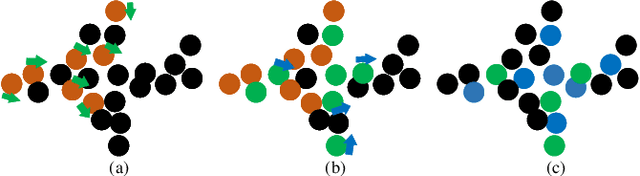
In order to retain more feature information of local areas on a point cloud, local grouping and subsampling are the necessary data structuring steps in most hierarchical deep learning models. Due to the disorder nature of the points in a point cloud, the significant time cost may be consumed when grouping and subsampling the points, which consequently results in poor scalability. This paper proposes a fast data structuring method called PSNet (Point Structuring Net). PSNet transforms the spatial features of the points and matches them to the features of local areas in a point cloud. PSNet achieves grouping and sampling at the same time while the existing methods process sampling and grouping in two separate steps (such as using FPS plus kNN). PSNet performs feature transformation pointwise while the existing methods uses the spatial relationship among the points as the reference for grouping. Thanks to these features, PSNet has two important advantages: 1) the grouping and sampling results obtained by PSNet is stable and permutation invariant; and 2) PSNet can be easily parallelized. PSNet can replace the data structuring methods in the mainstream point cloud deep learning models in a plug-and-play manner. We have conducted extensive experiments. The results show that PSNet can improve the training and inference speed significantly while maintaining the model accuracy.
Truth Discovery with Memory Network
Nov 07, 2016


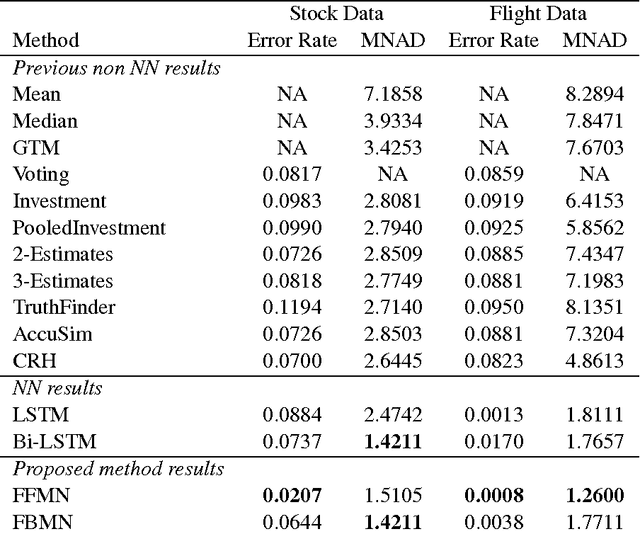
Truth discovery is to resolve conflicts and find the truth from multiple-source statements. Conventional methods mostly research based on the mutual effect between the reliability of sources and the credibility of statements, however, pay no attention to the mutual effect among the credibility of statements about the same object. We propose memory network based models to incorporate these two ideas to do the truth discovery. We use feedforward memory network and feedback memory network to learn the representation of the credibility of statements which are about the same object. Specially, we adopt memory mechanism to learn source reliability and use it through truth prediction. During learning models, we use multiple types of data (categorical data and continuous data) by assigning different weights automatically in the loss function based on their own effect on truth discovery prediction. The experiment results show that the memory network based models much outperform the state-of-the-art method and other baseline methods.