 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Guaranteed Poisoning Attacks in Federated Learning: A Sliding Mode Approach
May 22, 2025Manipulation of local training data and local updates, i.e., the poisoning attack, is the main threat arising from the collaborative nature of the federated learning (FL) paradigm. Most existing poisoning attacks aim to manipulate local data/models in a way that causes denial-of-service (DoS) issues. In this paper, we introduce a novel attack method, named Federated Learning Sliding Attack (FedSA) scheme, aiming at precisely introducing the extent of poisoning in a subtle controlled manner. It operates with a predefined objective, such as reducing global model's prediction accuracy by 10\%. FedSA integrates robust nonlinear control-Sliding Mode Control (SMC) theory with model poisoning attacks. It can manipulate the updates from malicious clients to drive the global model towards a compromised state, achieving this at a controlled and inconspicuous rate. Additionally, leveraging the robust control properties of FedSA allows precise control over the convergence bounds, enabling the attacker to set the global accuracy of the poisoned model to any desired level. Experimental results demonstrate that FedSA can accurately achieve a predefined global accuracy with fewer malicious clients while maintaining a high level of stealth and adjustable learning rates.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
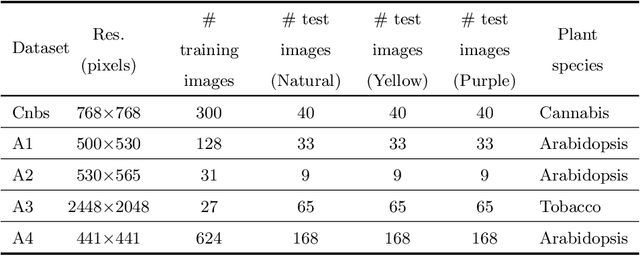
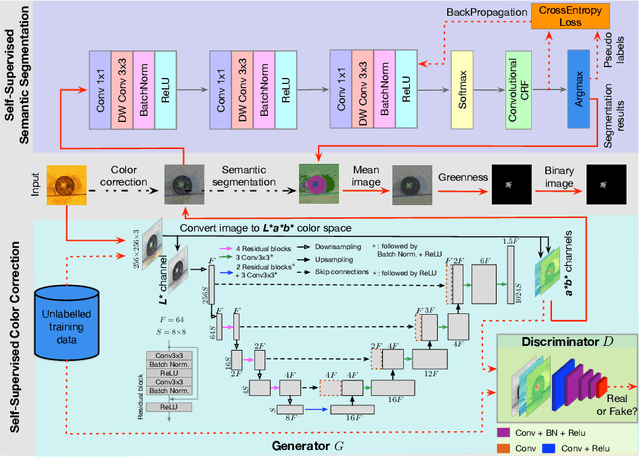

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
Piecewise Linear Units Improve Deep Neural Networks
Aug 22, 2021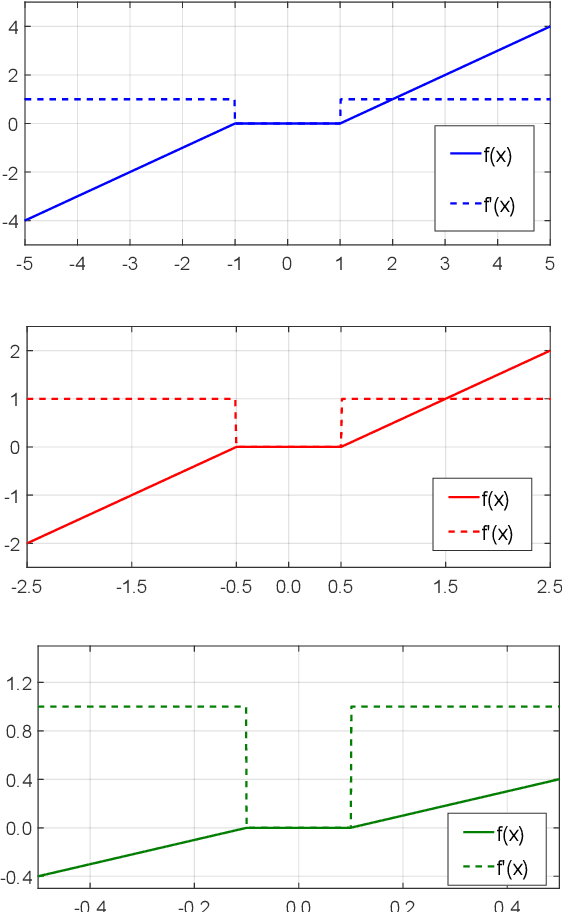

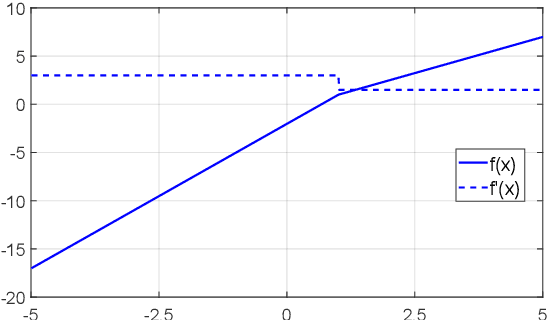

The activation function is at the heart of a deep neural networks nonlinearity; the choice of the function has great impact on the success of training. Currently, many practitioners prefer the Rectified Linear Unit (ReLU) due to its simplicity and reliability, despite its few drawbacks. While most previous functions proposed to supplant ReLU have been hand-designed, recent work on learning the function during training has shown promising results. In this paper we propose an adaptive piecewise linear activation function, the Piecewise Linear Unit (PiLU), which can be learned independently for each dimension of the neural network. We demonstrate how PiLU is a generalised rectifier unit and note its similarities with the Adaptive Piecewise Linear Units, namely adaptive and piecewise linear. Across a distribution of 30 experiments, we show that for the same model architecture, hyperparameters, and pre-processing, PiLU significantly outperforms ReLU: reducing classification error by 18.53% on CIFAR-10 and 13.13% on CIFAR-100, for a minor increase in the number of neurons. Further work should be dedicated to exploring generalised piecewise linear units, as well as verifying these results across other challenging domains and larger problems.