 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiecewise Linear Units Improve Deep Neural Networks
Aug 22, 2021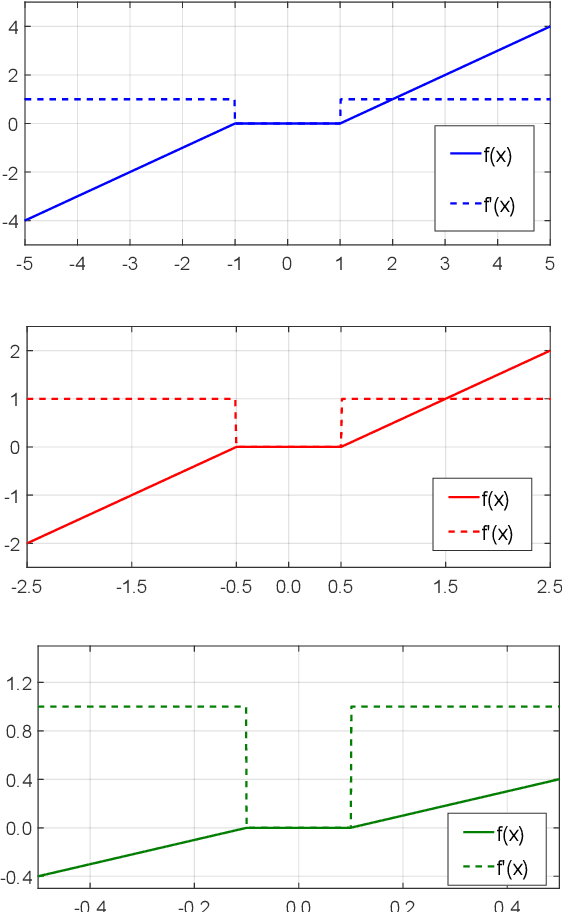

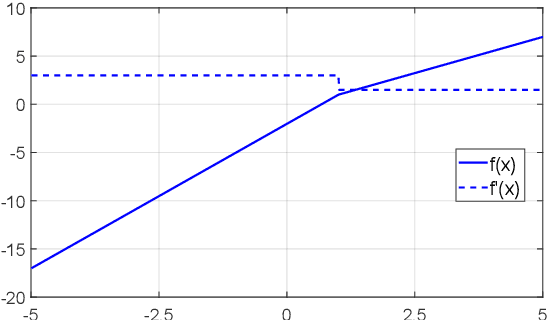

The activation function is at the heart of a deep neural networks nonlinearity; the choice of the function has great impact on the success of training. Currently, many practitioners prefer the Rectified Linear Unit (ReLU) due to its simplicity and reliability, despite its few drawbacks. While most previous functions proposed to supplant ReLU have been hand-designed, recent work on learning the function during training has shown promising results. In this paper we propose an adaptive piecewise linear activation function, the Piecewise Linear Unit (PiLU), which can be learned independently for each dimension of the neural network. We demonstrate how PiLU is a generalised rectifier unit and note its similarities with the Adaptive Piecewise Linear Units, namely adaptive and piecewise linear. Across a distribution of 30 experiments, we show that for the same model architecture, hyperparameters, and pre-processing, PiLU significantly outperforms ReLU: reducing classification error by 18.53% on CIFAR-10 and 13.13% on CIFAR-100, for a minor increase in the number of neurons. Further work should be dedicated to exploring generalised piecewise linear units, as well as verifying these results across other challenging domains and larger problems.