 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Federated Unsupervised Domain Adaptation with Scaled Entropy Attention and Multi-Source Smoothed Pseudo Labeling
Mar 13, 2025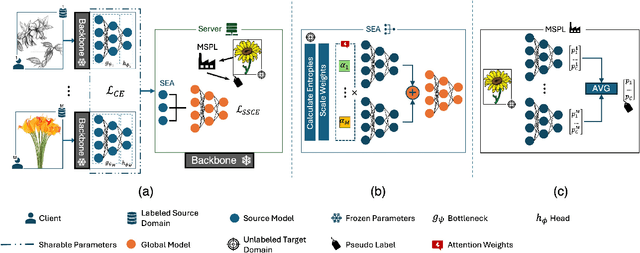
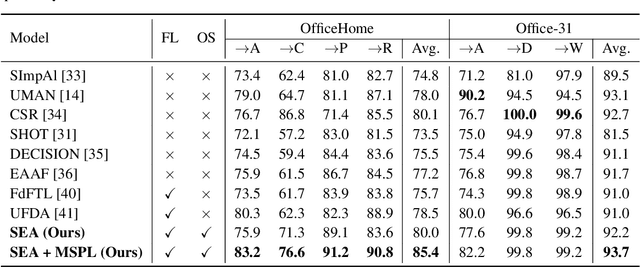

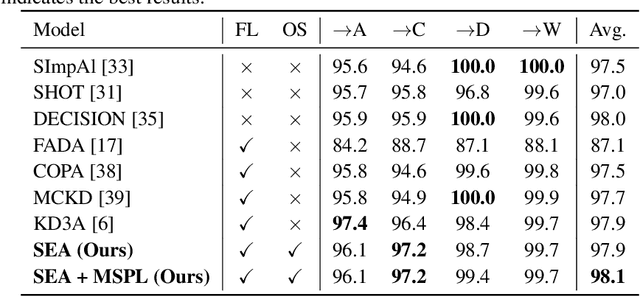
Federated Learning (FL) is a promising approach for privacy-preserving collaborative learning. However, it faces significant challenges when dealing with domain shifts, especially when each client has access only to its source data and cannot share it during target domain adaptation. Moreover, FL methods often require high communication overhead due to multiple rounds of model updates between clients and the server. We propose a one-shot Federated Unsupervised Domain Adaptation (FUDA) method to address these limitations. Specifically, we introduce Scaled Entropy Attention (SEA) for model aggregation and Multi-Source Pseudo Labeling (MSPL) for target domain adaptation. SEA uses scaled prediction entropy on target domain to assign higher attention to reliable models. This improves the global model quality and ensures balanced weighting of contributions. MSPL distills knowledge from multiple source models to generate pseudo labels and manage noisy labels using smoothed soft-label cross-entropy (SSCE). Our approach outperforms state-of-the-art methods across four standard benchmarks while reducing communication and computation costs, making it highly suitable for real-world applications. The implementation code will be made publicly available upon publication.
Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training
Dec 16, 2024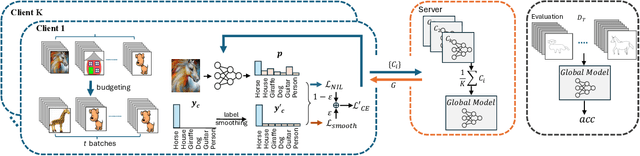

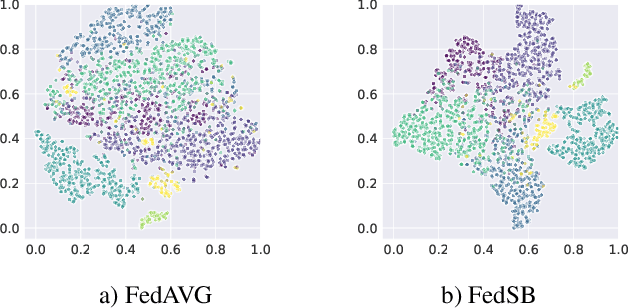
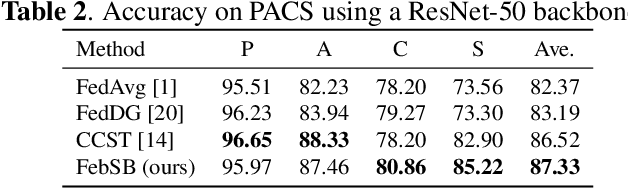
In this paper, we propose a novel approach, Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training (FedSB), to address the challenges of data heterogeneity within a federated learning framework. FedSB utilizes label smoothing at the client level to prevent overfitting to domain-specific features, thereby enhancing generalization capabilities across diverse domains when aggregating local models into a global model. Additionally, FedSB incorporates a decentralized budgeting mechanism which balances training among clients, which is shown to improve the performance of the aggregated global model. Extensive experiments on four commonly used multi-domain datasets, PACS, VLCS, OfficeHome, and TerraInc, demonstrate that FedSB outperforms competing methods, achieving state-of-the-art results on three out of four datasets, indicating the effectiveness of FedSB in addressing data heterogeneity.
EUDA: An Efficient Unsupervised Domain Adaptation via Self-Supervised Vision Transformer
Jul 31, 2024Unsupervised domain adaptation (UDA) aims to mitigate the domain shift issue, where the distribution of training (source) data differs from that of testing (target) data. Many models have been developed to tackle this problem, and recently vision transformers (ViTs) have shown promising results. However, the complexity and large number of trainable parameters of ViTs restrict their deployment in practical applications. This underscores the need for an efficient model that not only reduces trainable parameters but also allows for adjustable complexity based on specific needs while delivering comparable performance. To achieve this, in this paper we introduce an Efficient Unsupervised Domain Adaptation (EUDA) framework. EUDA employs the DINOv2, which is a self-supervised ViT, as a feature extractor followed by a simplified bottleneck of fully connected layers to refine features for enhanced domain adaptation. Additionally, EUDA employs the synergistic domain alignment loss (SDAL), which integrates cross-entropy (CE) and maximum mean discrepancy (MMD) losses, to balance adaptation by minimizing classification errors in the source domain while aligning the source and target domain distributions. The experimental results indicate the effectiveness of EUDA in producing comparable results as compared with other state-of-the-art methods in domain adaptation with significantly fewer trainable parameters, between 42% to 99.7% fewer. This showcases the ability to train the model in a resource-limited environment. The code of the model is available at: https://github.com/A-Abedi/EUDA.
Methods for Class-Imbalanced Learning with Support Vector Machines: A Review and an Empirical Evaluation
Jun 05, 2024This paper presents a review on methods for class-imbalanced learning with the Support Vector Machine (SVM) and its variants. We first explain the structure of SVM and its variants and discuss their inefficiency in learning with class-imbalanced data sets. We introduce a hierarchical categorization of SVM-based models with respect to class-imbalanced learning. Specifically, we categorize SVM-based models into re-sampling, algorithmic, and fusion methods, and discuss the principles of the representative models in each category. In addition, we conduct a series of empirical evaluations to compare the performances of various representative SVM-based models in each category using benchmark imbalanced data sets, ranging from low to high imbalanced ratios. Our findings reveal that while algorithmic methods are less time-consuming owing to no data pre-processing requirements, fusion methods, which combine both re-sampling and algorithmic approaches, generally perform the best, but with a higher computational load. A discussion on research gaps and future research directions is provided.
Federated Unsupervised Domain Generalization using Global and Local Alignment of Gradients
May 25, 2024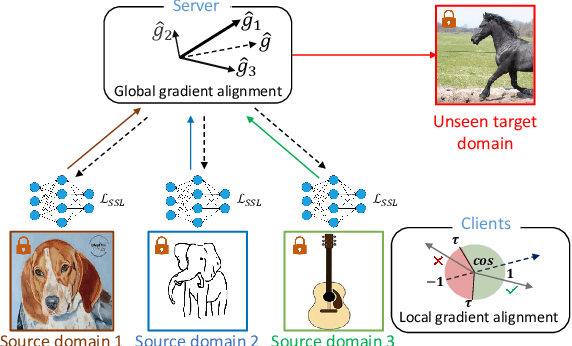
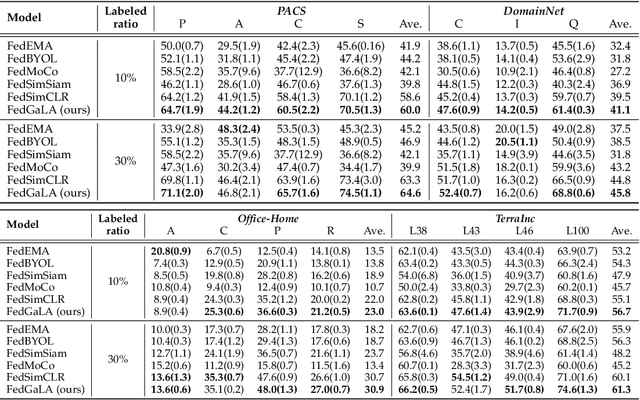
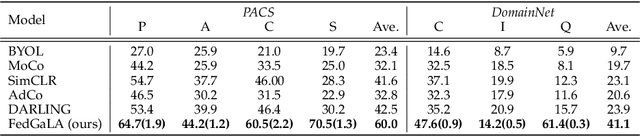
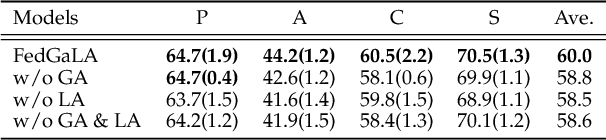
We address the problem of federated domain generalization in an unsupervised setting for the first time. We first theoretically establish a connection between domain shift and alignment of gradients in unsupervised federated learning and show that aligning the gradients at both client and server levels can facilitate the generalization of the model to new (target) domains. Building on this insight, we propose a novel method named FedGaLA, which performs gradient alignment at the client level to encourage clients to learn domain-invariant features, as well as global gradient alignment at the server to obtain a more generalized aggregated model. To empirically evaluate our method, we perform various experiments on four commonly used multi-domain datasets, PACS, OfficeHome, DomainNet, and TerraInc. The results demonstrate the effectiveness of our method which outperforms comparable baselines. Ablation and sensitivity studies demonstrate the impact of different components and parameters in our approach. The source code will be available online upon publication.
An Attentive-based Generative Model for Medical Image Synthesis
Jun 02, 2023Magnetic resonance (MR) and computer tomography (CT) imaging are valuable tools for diagnosing diseases and planning treatment. However, limitations such as radiation exposure and cost can restrict access to certain imaging modalities. To address this issue, medical image synthesis can generate one modality from another, but many existing models struggle with high-quality image synthesis when multiple slices are present in the dataset. This study proposes an attention-based dual contrast generative model, called ADC-cycleGAN, which can synthesize medical images from unpaired data with multiple slices. The model integrates a dual contrast loss term with the CycleGAN loss to ensure that the synthesized images are distinguishable from the source domain. Additionally, an attention mechanism is incorporated into the generators to extract informative features from both channel and spatial domains. To improve performance when dealing with multiple slices, the $K$-means algorithm is used to cluster the dataset into $K$ groups, and each group is used to train a separate ADC-cycleGAN. Experimental results demonstrate that the proposed ADC-cycleGAN model produces comparable samples to other state-of-the-art generative models, achieving the highest PSNR and SSIM values of 19.04385 and 0.68551, respectively. We publish the code at https://github.com/JiayuanWang-JW/ADC-cycleGAN.
An Ensemble Semi-Supervised Adaptive Resonance Theory Model with Explanation Capability for Pattern Classification
May 19, 2023Most semi-supervised learning (SSL) models entail complex structures and iterative training processes as well as face difficulties in interpreting their predictions to users. To address these issues, this paper proposes a new interpretable SSL model using the supervised and unsupervised Adaptive Resonance Theory (ART) family of networks, which is denoted as SSL-ART. Firstly, SSL-ART adopts an unsupervised fuzzy ART network to create a number of prototype nodes using unlabeled samples. Then, it leverages a supervised fuzzy ARTMAP structure to map the established prototype nodes to the target classes using labeled samples. Specifically, a one-to-many (OtM) mapping scheme is devised to associate a prototype node with more than one class label. The main advantages of SSL-ART include the capability of: (i) performing online learning, (ii) reducing the number of redundant prototype nodes through the OtM mapping scheme and minimizing the effects of noisy samples, and (iii) providing an explanation facility for users to interpret the predicted outcomes. In addition, a weighted voting strategy is introduced to form an ensemble SSL-ART model, which is denoted as WESSL-ART. Every ensemble member, i.e., SSL-ART, assigns {\color{black}a different weight} to each class based on its performance pertaining to the corresponding class. The aim is to mitigate the effects of training data sequences on all SSL-ART members and improve the overall performance of WESSL-ART. The experimental results on eighteen benchmark data sets, three artificially generated data sets, and a real-world case study indicate the benefits of the proposed SSL-ART and WESSL-ART models for tackling pattern classification problems.
A Review of Deep Learning for Video Captioning
Apr 22, 2023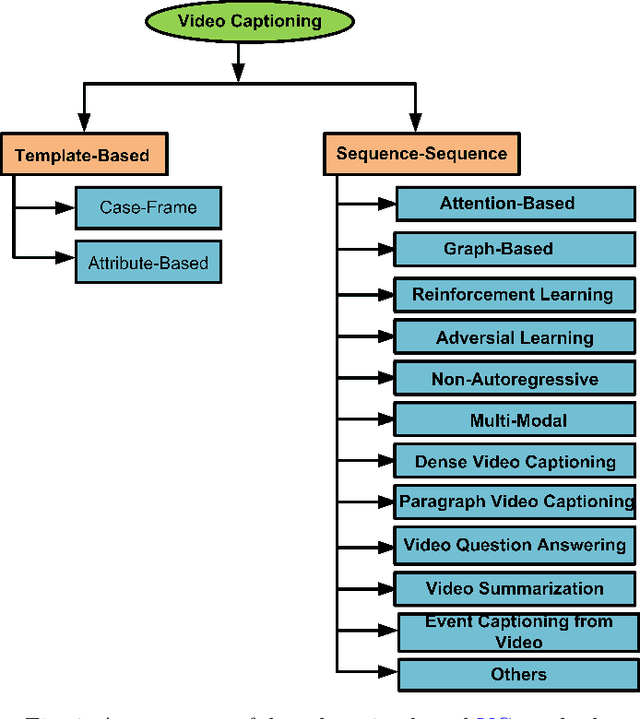
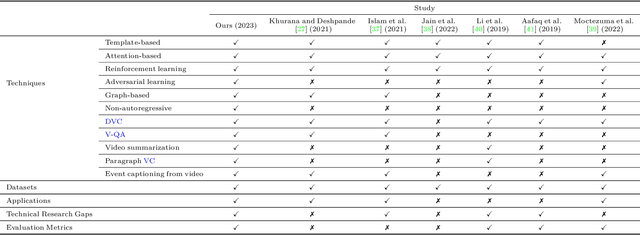
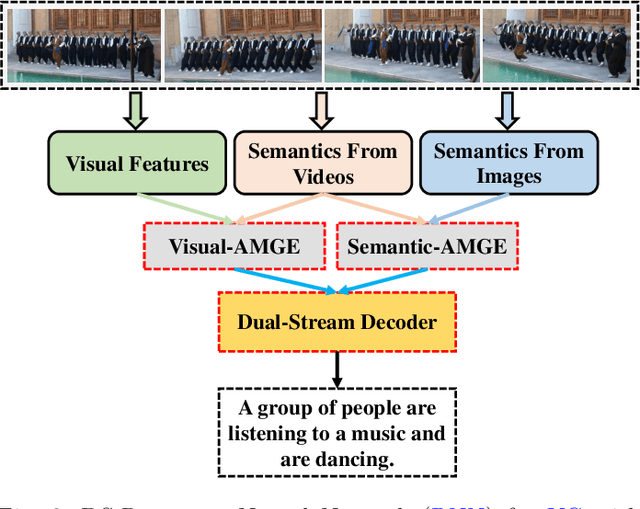
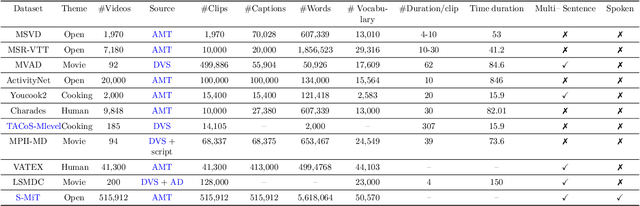
Video captioning (VC) is a fast-moving, cross-disciplinary area of research that bridges work in the fields of computer vision, natural language processing (NLP), linguistics, and human-computer interaction. In essence, VC involves understanding a video and describing it with language. Captioning is used in a host of applications from creating more accessible interfaces (e.g., low-vision navigation) to video question answering (V-QA), video retrieval and content generation. This survey covers deep learning-based VC, including but, not limited to, attention-based architectures, graph networks, reinforcement learning, adversarial networks, dense video captioning (DVC), and more. We discuss the datasets and evaluation metrics used in the field, and limitations, applications, challenges, and future directions for VC.
DC-cycleGAN: Bidirectional CT-to-MR Synthesis from Unpaired Data
Nov 02, 2022Magnetic resonance (MR) and computer tomography (CT) images are two typical types of medical images that provide mutually-complementary information for accurate clinical diagnosis and treatment. However, obtaining both images may be limited due to some considerations such as cost, radiation dose and modality missing. Recently, medical image synthesis has aroused gaining research interest to cope with this limitation. In this paper, we propose a bidirectional learning model, denoted as dual contrast cycleGAN (DC-cycleGAN), to synthesis medical images from unpaired data. Specifically, a dual contrast loss is introduced into the discriminators to indirectly build constraints between MR and CT images by taking the advantage of samples from the source domain as negative sample and enforce the synthetic images fall far away from the source domain. In addition, cross entropy and structural similarity index (SSIM) are integrated into the cycleGAN in order to consider both luminance and structure of samples when synthesizing images. The experimental results indicates that DC-cycleGAN is able to produce promising results as compared with other cycleGAN-based medical image synthesis methods such as cycleGAN, RegGAN, DualGAN and NiceGAN. The code will be available at https://github.com/JiayuanWang-JW/DC-cycleGAN.
A Survey on Epistemic (Model) Uncertainty in Supervised Learning: Recent Advances and Applications
Nov 04, 2021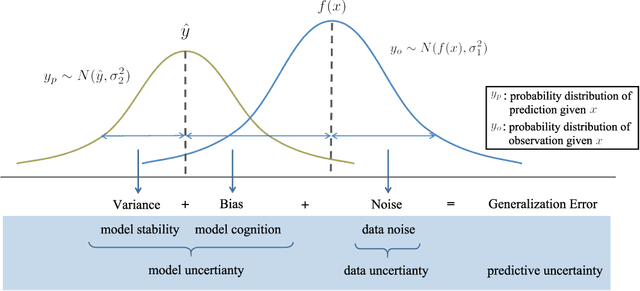
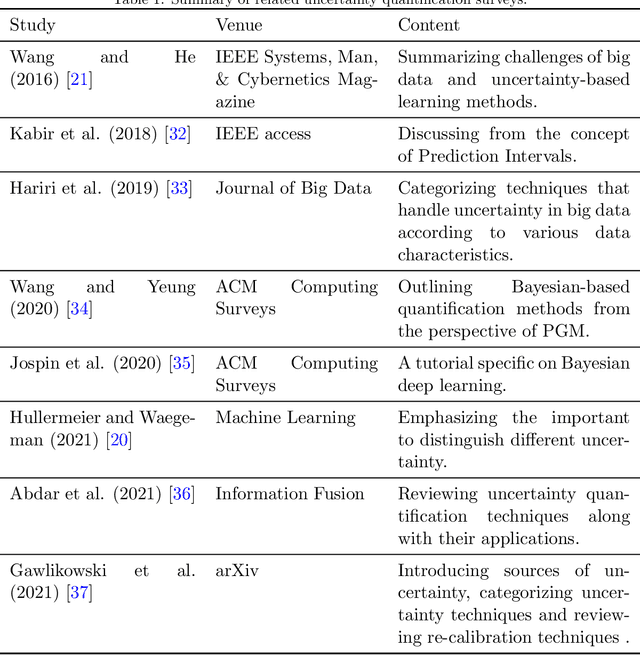
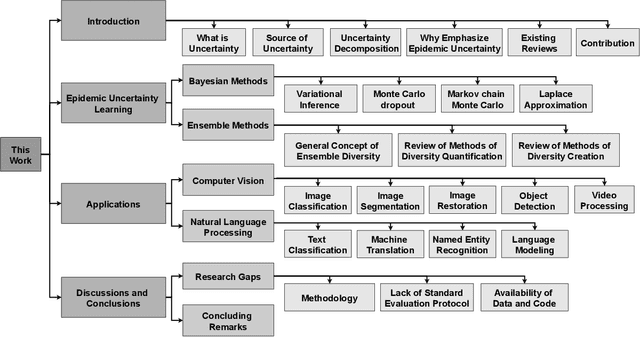
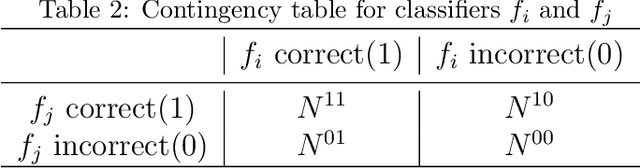
Quantifying the uncertainty of supervised learning models plays an important role in making more reliable predictions. Epistemic uncertainty, which usually is due to insufficient knowledge about the model, can be reduced by collecting more data or refining the learning models. Over the last few years, scholars have proposed many epistemic uncertainty handling techniques which can be roughly grouped into two categories, i.e., Bayesian and ensemble. This paper provides a comprehensive review of epistemic uncertainty learning techniques in supervised learning over the last five years. As such, we, first, decompose the epistemic uncertainty into bias and variance terms. Then, a hierarchical categorization of epistemic uncertainty learning techniques along with their representative models is introduced. In addition, several applications such as computer vision (CV) and natural language processing (NLP) are presented, followed by a discussion on research gaps and possible future research directions.