 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Domain Generalization with Label Smoothing and Balanced Decentralized Training
Dec 16, 2024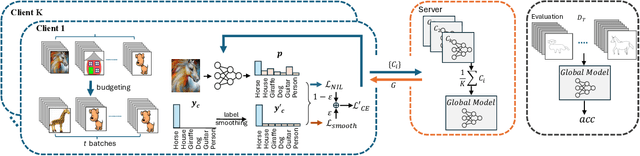

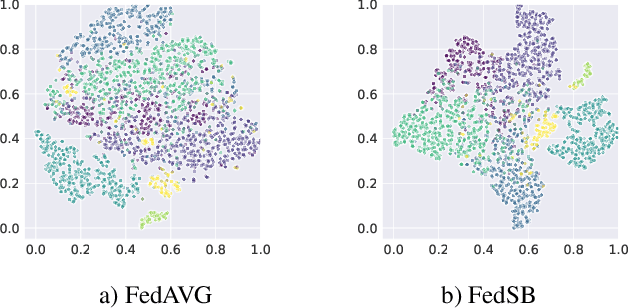
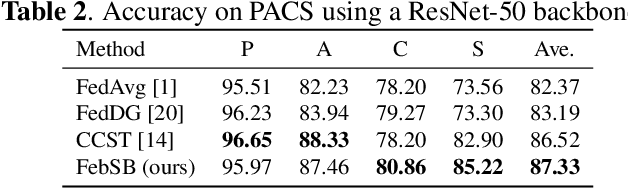
In this paper, we propose a novel approach, Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training (FedSB), to address the challenges of data heterogeneity within a federated learning framework. FedSB utilizes label smoothing at the client level to prevent overfitting to domain-specific features, thereby enhancing generalization capabilities across diverse domains when aggregating local models into a global model. Additionally, FedSB incorporates a decentralized budgeting mechanism which balances training among clients, which is shown to improve the performance of the aggregated global model. Extensive experiments on four commonly used multi-domain datasets, PACS, VLCS, OfficeHome, and TerraInc, demonstrate that FedSB outperforms competing methods, achieving state-of-the-art results on three out of four datasets, indicating the effectiveness of FedSB in addressing data heterogeneity.
Federated Unsupervised Domain Generalization using Global and Local Alignment of Gradients
May 25, 2024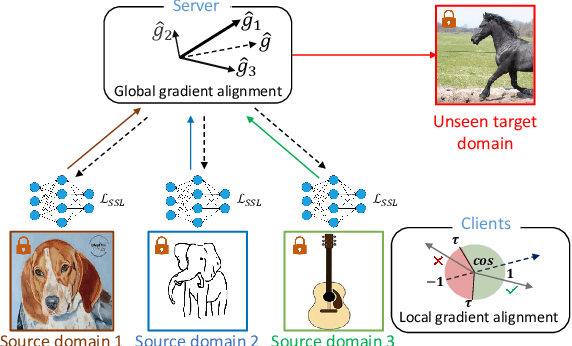
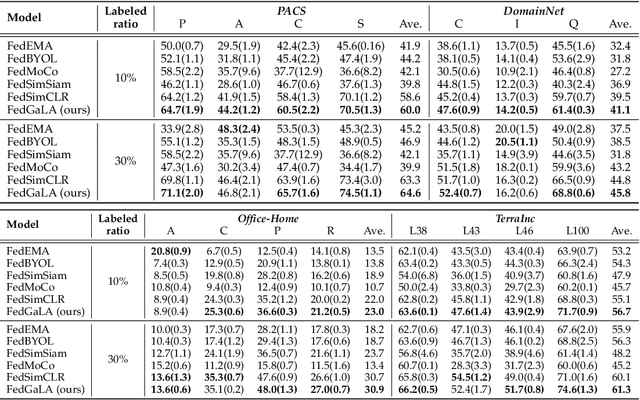
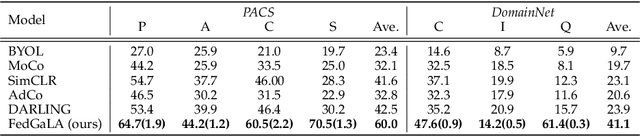
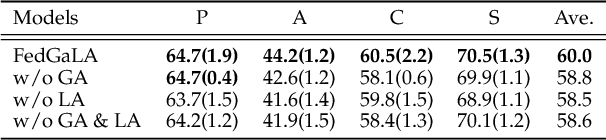
We address the problem of federated domain generalization in an unsupervised setting for the first time. We first theoretically establish a connection between domain shift and alignment of gradients in unsupervised federated learning and show that aligning the gradients at both client and server levels can facilitate the generalization of the model to new (target) domains. Building on this insight, we propose a novel method named FedGaLA, which performs gradient alignment at the client level to encourage clients to learn domain-invariant features, as well as global gradient alignment at the server to obtain a more generalized aggregated model. To empirically evaluate our method, we perform various experiments on four commonly used multi-domain datasets, PACS, OfficeHome, DomainNet, and TerraInc. The results demonstrate the effectiveness of our method which outperforms comparable baselines. Ablation and sensitivity studies demonstrate the impact of different components and parameters in our approach. The source code will be available online upon publication.
Continual Learning for Out-of-Distribution Pedestrian Detection
Jun 26, 2023



A continual learning solution is proposed to address the out-of-distribution generalization problem for pedestrian detection. While recent pedestrian detection models have achieved impressive performance on various datasets, they remain sensitive to shifts in the distribution of the inference data. Our method adopts and modifies Elastic Weight Consolidation to a backbone object detection network, in order to penalize the changes in the model weights based on their importance towards the initially learned task. We show that when trained with one dataset and fine-tuned on another, our solution learns the new distribution and maintains its performance on the previous one, avoiding catastrophic forgetting. We use two popular datasets, CrowdHuman and CityPersons for our cross-dataset experiments, and show considerable improvements over standard fine-tuning, with a 9% and 18% miss rate percent reduction improvement in the CrowdHuman and CityPersons datasets, respectively.
Can Continual Learning Improve Long-Tailed Recognition? Toward a Unified Framework
Jun 23, 2023



The Long-Tailed Recognition (LTR) problem emerges in the context of learning from highly imbalanced datasets, in which the number of samples among different classes is heavily skewed. LTR methods aim to accurately learn a dataset comprising both a larger Head set and a smaller Tail set. We propose a theorem where under the assumption of strong convexity of the loss function, the weights of a learner trained on the full dataset are within an upper bound of the weights of the same learner trained strictly on the Head. Next, we assert that by treating the learning of the Head and Tail as two separate and sequential steps, Continual Learning (CL) methods can effectively update the weights of the learner to learn the Tail without forgetting the Head. First, we validate our theoretical findings with various experiments on the toy MNIST-LT dataset. We then evaluate the efficacy of several CL strategies on multiple imbalanced variations of two standard LTR benchmarks (CIFAR100-LT and CIFAR10-LT), and show that standard CL methods achieve strong performance gains in comparison to baselines and approach solutions that have been tailor-made for LTR. We also assess the applicability of CL techniques on real-world data by exploring CL on the naturally imbalanced Caltech256 dataset and demonstrate its superiority over state-of-the-art classifiers. Our work not only unifies LTR and CL but also paves the way for leveraging advances in CL methods to tackle the LTR challenge more effectively.
Multiscale Crowd Counting and Localization By Multitask Point Supervision
Feb 21, 2022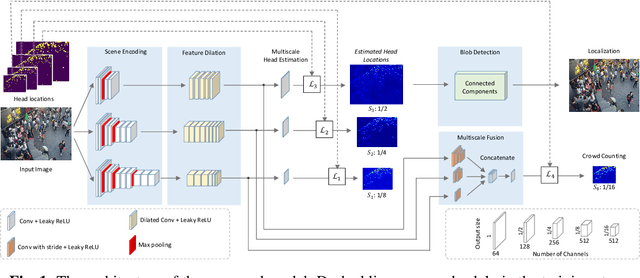
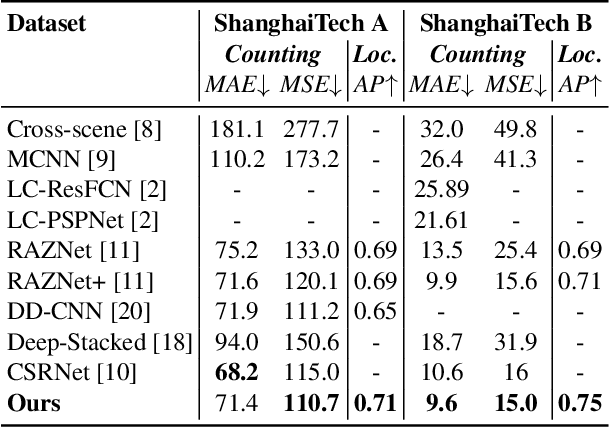

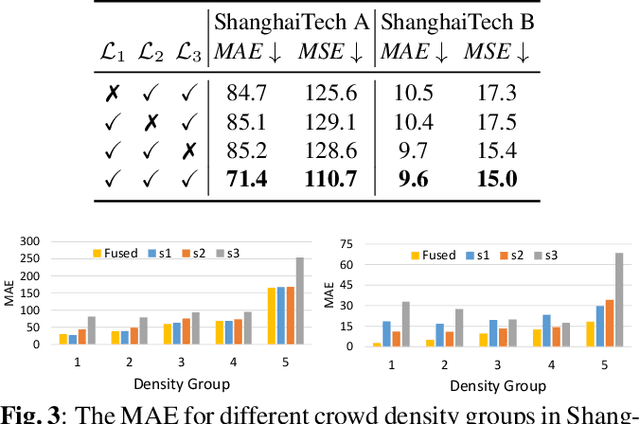
We propose a multitask approach for crowd counting and person localization in a unified framework. As the detection and localization tasks are well-correlated and can be jointly tackled, our model benefits from a multitask solution by learning multiscale representations of encoded crowd images, and subsequently fusing them. In contrast to the relatively more popular density-based methods, our model uses point supervision to allow for crowd locations to be accurately identified. We test our model on two popular crowd counting datasets, ShanghaiTech A and B, and demonstrate that our method achieves strong results on both counting and localization tasks, with MSE measures of 110.7 and 15.0 for crowd counting and AP measures of 0.71 and 0.75 for localization, on ShanghaiTech A and B respectively. Our detailed ablation experiments show the impact of our multiscale approach as well as the effectiveness of the fusion module embedded in our network. Our code is available at: https://github.com/RCVLab-AiimLab/crowd_counting.