 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI weather models predict out-of-distribution gray swan tropical cyclones?
Oct 19, 2024



Predicting gray swan weather extremes, which are possible but so rare that they are absent from the training dataset, is a major concern for AI weather/climate models. An important open question is whether AI models can extrapolate from weaker weather events present in the training set to stronger, unseen weather extremes. To test this, we train independent versions of the AI model FourCastNet on the 1979-2015 ERA5 dataset with all data, or with Category 3-5 tropical cyclones (TCs) removed, either globally or only over the North Atlantic or Western Pacific basin. We then test these versions of FourCastNet on 2018-2023 Category 5 TCs (gray swans). All versions yield similar accuracy for global weather, but the one trained without Category 3-5 TCs cannot accurately forecast Category 5 TCs, indicating that these models cannot extrapolate from weaker storms. The versions trained without Category 3-5 TCs in one basin show some skill forecasting Category 5 TCs in that basin, suggesting that FourCastNet can generalize across tropical basins. This is encouraging and surprising because regional information is implicitly encoded in inputs. No version satisfies gradient-wind balance, implying that enforcing such physical constraints may not improve generalizability to gray swans. Given that current state-of-the-art AI weather/climate models have similar learning strategies, we expect our findings to apply to other models and extreme events. Our work demonstrates that novel learning strategies are needed for AI weather/climate models to provide early warning or estimated statistics for the rarest, most impactful weather extremes.
Diffusion Models with Deterministic Normalizing Flow Priors
Sep 03, 2023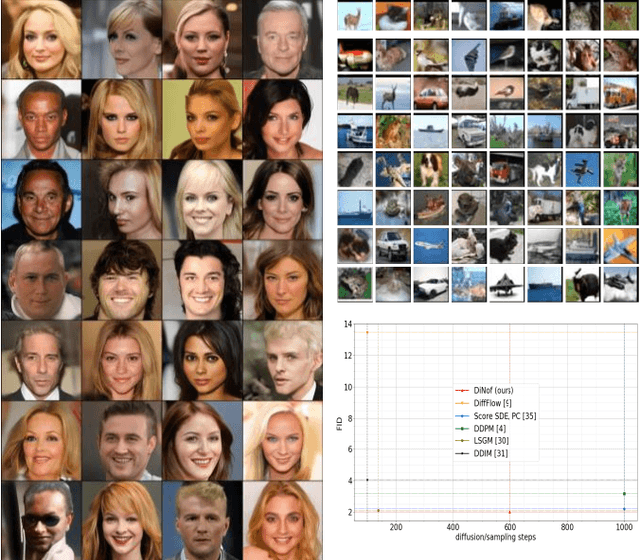
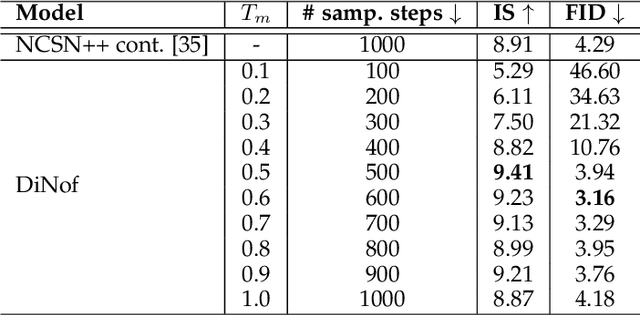
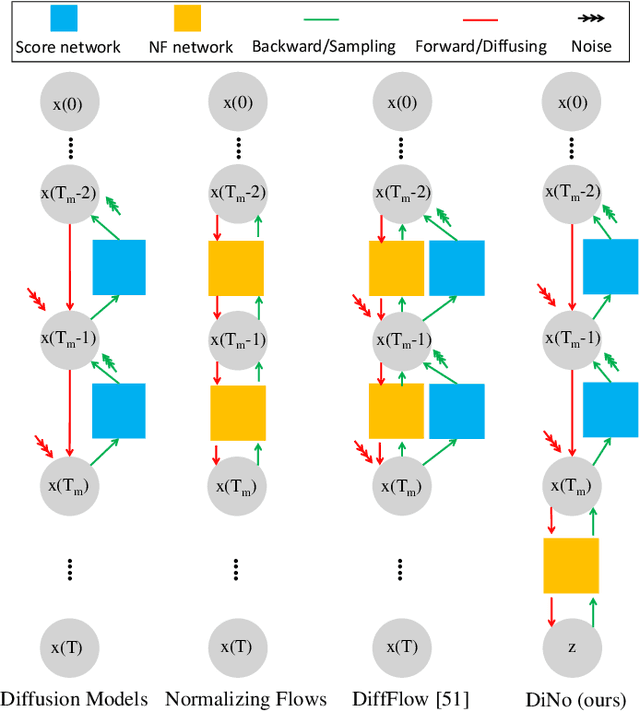
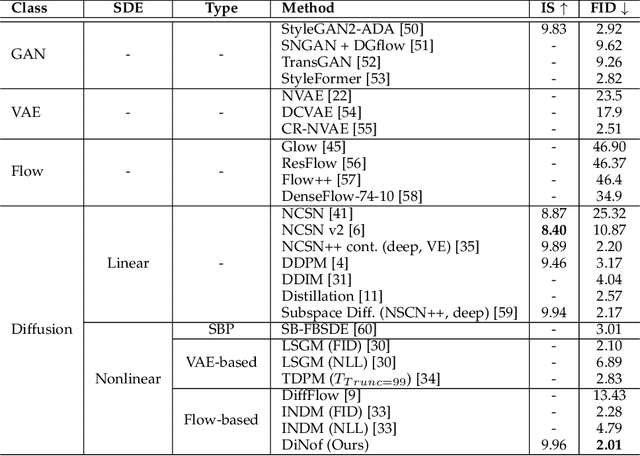
For faster sampling and higher sample quality, we propose DiNof ($\textbf{Di}$ffusion with $\textbf{No}$rmalizing $\textbf{f}$low priors), a technique that makes use of normalizing flows and diffusion models. We use normalizing flows to parameterize the noisy data at any arbitrary step of the diffusion process and utilize it as the prior in the reverse diffusion process. More specifically, the forward noising process turns a data distribution into partially noisy data, which are subsequently transformed into a Gaussian distribution by a nonlinear process. The backward denoising procedure begins with a prior created by sampling from the Gaussian distribution and applying the invertible normalizing flow transformations deterministically. To generate the data distribution, the prior then undergoes the remaining diffusion stochastic denoising procedure. Through the reduction of the number of total diffusion steps, we are able to speed up both the forward and backward processes. More importantly, we improve the expressive power of diffusion models by employing both deterministic and stochastic mappings. Experiments on standard image generation datasets demonstrate the advantage of the proposed method over existing approaches. On the unconditional CIFAR10 dataset, for example, we achieve an FID of 2.01 and an Inception score of 9.96. Our method also demonstrates competitive performance on CelebA-HQ-256 dataset as it obtains an FID score of 7.11. Code is available at https://github.com/MohsenZand/DiNof.
Multiscale Residual Learning of Graph Convolutional Sequence Chunks for Human Motion Prediction
Aug 31, 2023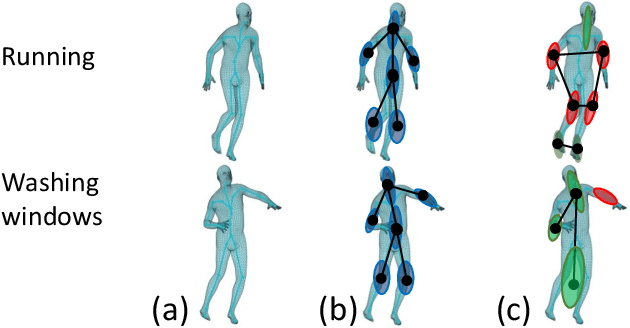
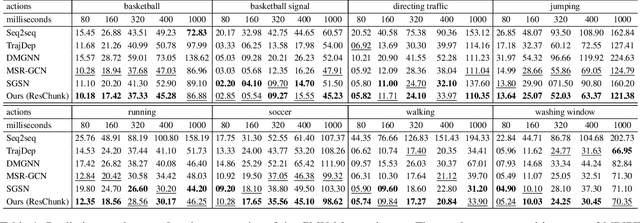
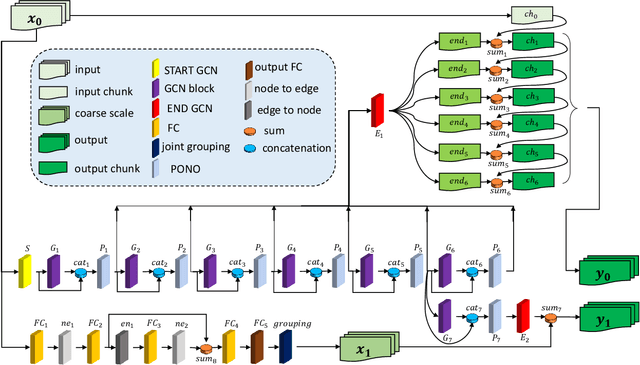

A new method is proposed for human motion prediction by learning temporal and spatial dependencies. Recently, multiscale graphs have been developed to model the human body at higher abstraction levels, resulting in more stable motion prediction. Current methods however predetermine scale levels and combine spatially proximal joints to generate coarser scales based on human priors, even though movement patterns in different motion sequences vary and do not fully comply with a fixed graph of spatially connected joints. Another problem with graph convolutional methods is mode collapse, in which predicted poses converge around a mean pose with no discernible movements, particularly in long-term predictions. To tackle these issues, we propose ResChunk, an end-to-end network which explores dynamically correlated body components based on the pairwise relationships between all joints in individual sequences. ResChunk is trained to learn the residuals between target sequence chunks in an autoregressive manner to enforce the temporal connectivities between consecutive chunks. It is hence a sequence-to-sequence prediction network which considers dynamic spatio-temporal features of sequences at multiple levels. Our experiments on two challenging benchmark datasets, CMU Mocap and Human3.6M, demonstrate that our proposed method is able to effectively model the sequence information for motion prediction and outperform other techniques to set a new state-of-the-art. Our code is available at https://github.com/MohsenZand/ResChunk.
Diffusion Dataset Generation: Towards Closing the Sim2Real Gap for Pedestrian Detection
May 16, 2023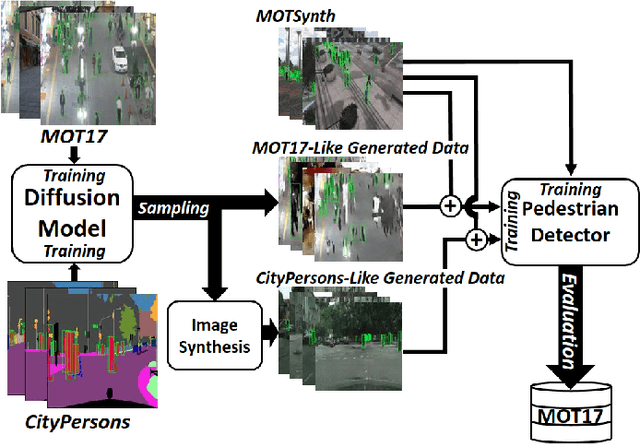
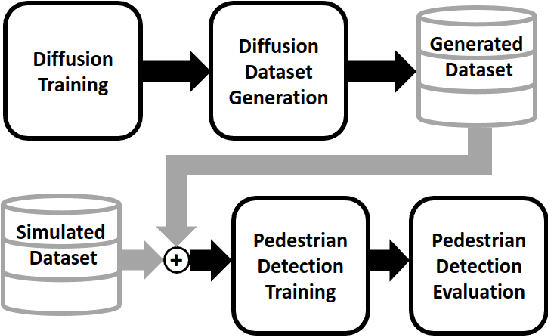
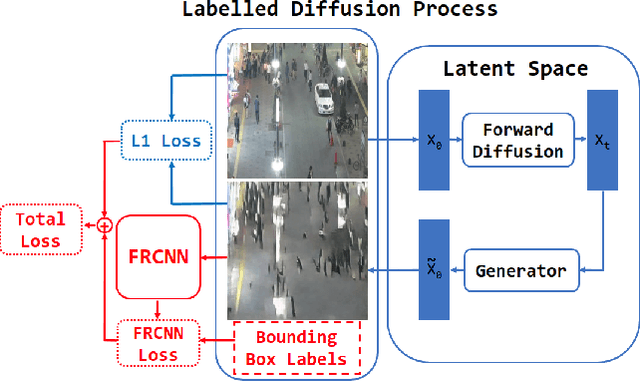

We propose a method that augments a simulated dataset using diffusion models to improve the performance of pedestrian detection in real-world data. The high cost of collecting and annotating data in the real-world has motivated the use of simulation platforms to create training datasets. While simulated data is inexpensive to collect and annotate, it unfortunately does not always closely match the distribution of real-world data, which is known as the sim2real gap. In this paper we propose a novel method of synthetic data creation meant to close the sim2real gap for the challenging pedestrian detection task. Our method uses a diffusion-based architecture to learn a real-world distribution which, once trained, is used to generate datasets. We mix this generated data with simulated data as a form of augmentation and show that training on a combination of generated and simulated data increases average precision by as much as 27.3% for pedestrian detection models in real-world data, compared against training on purely simulated data.
Keypoint Cascade Voting for Point Cloud Based 6DoF Pose Estimation
Oct 14, 2022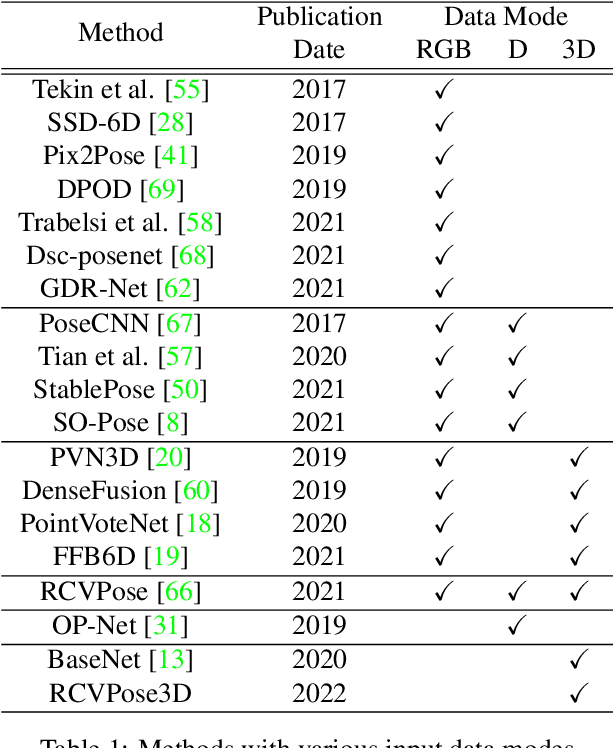
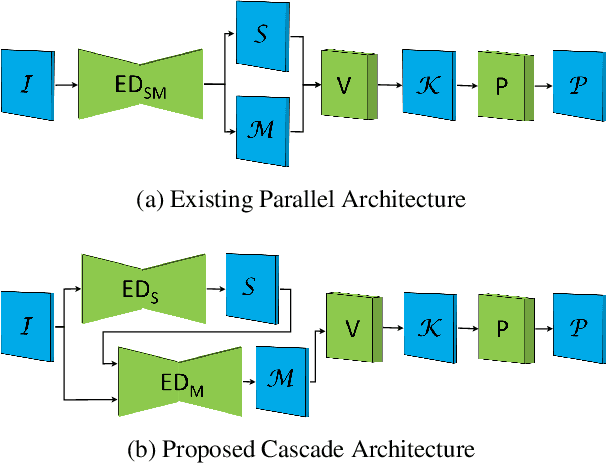
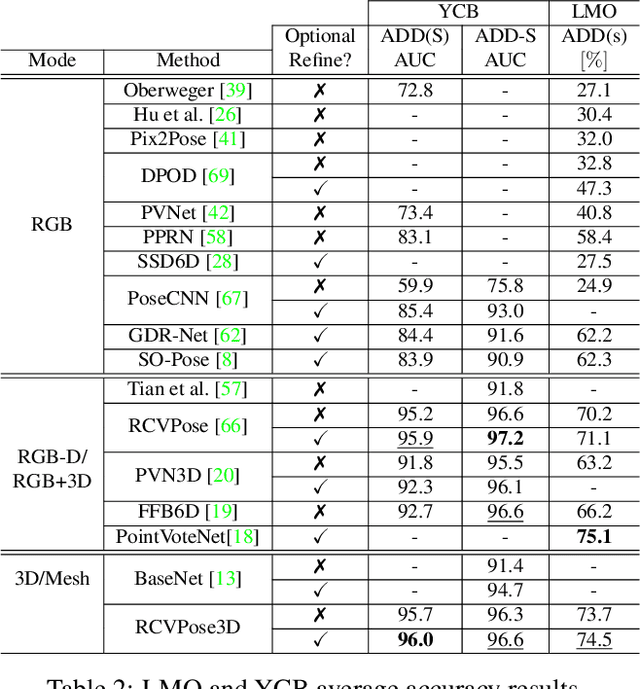
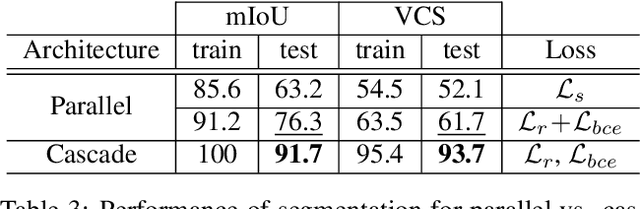
We propose a novel keypoint voting 6DoF object pose estimation method, which takes pure unordered point cloud geometry as input without RGB information. The proposed cascaded keypoint voting method, called RCVPose3D, is based upon a novel architecture which separates the task of semantic segmentation from that of keypoint regression, thereby increasing the effectiveness of both and improving the ultimate performance. The method also introduces a pairwise constraint in between different keypoints to the loss function when regressing the quantity for keypoint estimation, which is shown to be effective, as well as a novel Voter Confident Score which enhances both the learning and inference stages. Our proposed RCVPose3D achieves state-of-the-art performance on the Occlusion LINEMOD (74.5%) and YCB-Video (96.9%) datasets, outperforming existing pure RGB and RGB-D based methods, as well as being competitive with RGB plus point cloud methods.
ObjectBox: From Centers to Boxes for Anchor-Free Object Detection
Jul 14, 2022


We present ObjectBox, a novel single-stage anchor-free and highly generalizable object detection approach. As opposed to both existing anchor-based and anchor-free detectors, which are more biased toward specific object scales in their label assignments, we use only object center locations as positive samples and treat all objects equally in different feature levels regardless of the objects' sizes or shapes. Specifically, our label assignment strategy considers the object center locations as shape- and size-agnostic anchors in an anchor-free fashion, and allows learning to occur at all scales for every object. To support this, we define new regression targets as the distances from two corners of the center cell location to the four sides of the bounding box. Moreover, to handle scale-variant objects, we propose a tailored IoU loss to deal with boxes with different sizes. As a result, our proposed object detector does not need any dataset-dependent hyperparameters to be tuned across datasets. We evaluate our method on MS-COCO 2017 and PASCAL VOC 2012 datasets, and compare our results to state-of-the-art methods. We observe that ObjectBox performs favorably in comparison to prior works. Furthermore, we perform rigorous ablation experiments to evaluate different components of our method. Our code is available at: https://github.com/MohsenZand/ObjectBox.
Multiscale Crowd Counting and Localization By Multitask Point Supervision
Feb 21, 2022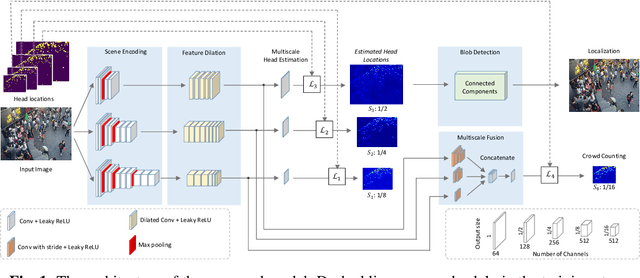
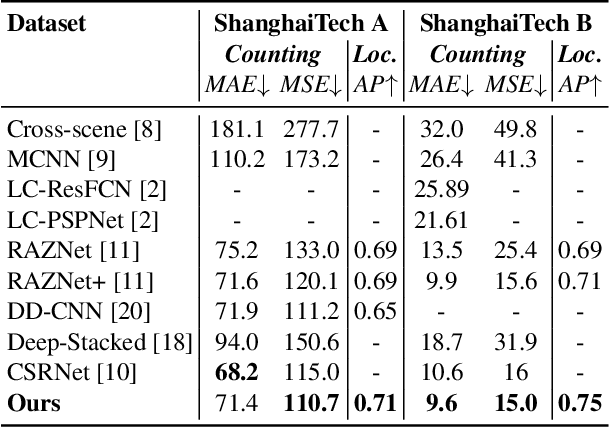

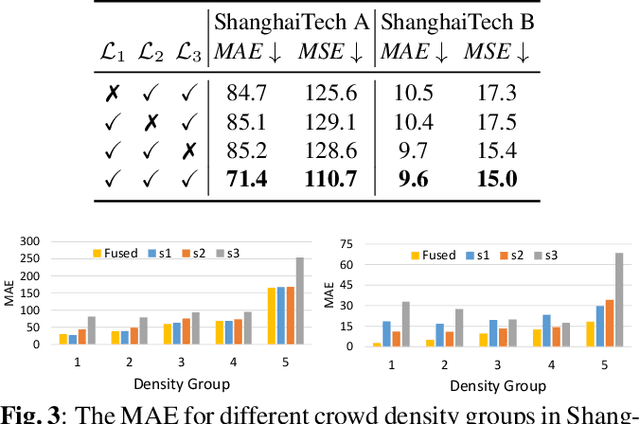
We propose a multitask approach for crowd counting and person localization in a unified framework. As the detection and localization tasks are well-correlated and can be jointly tackled, our model benefits from a multitask solution by learning multiscale representations of encoded crowd images, and subsequently fusing them. In contrast to the relatively more popular density-based methods, our model uses point supervision to allow for crowd locations to be accurately identified. We test our model on two popular crowd counting datasets, ShanghaiTech A and B, and demonstrate that our method achieves strong results on both counting and localization tasks, with MSE measures of 110.7 and 15.0 for crowd counting and AP measures of 0.71 and 0.75 for localization, on ShanghaiTech A and B respectively. Our detailed ablation experiments show the impact of our multiscale approach as well as the effectiveness of the fusion module embedded in our network. Our code is available at: https://github.com/RCVLab-AiimLab/crowd_counting.
Multistream ValidNet: Improving 6D Object Pose Estimation by Automatic Multistream Validation
Jun 12, 2021

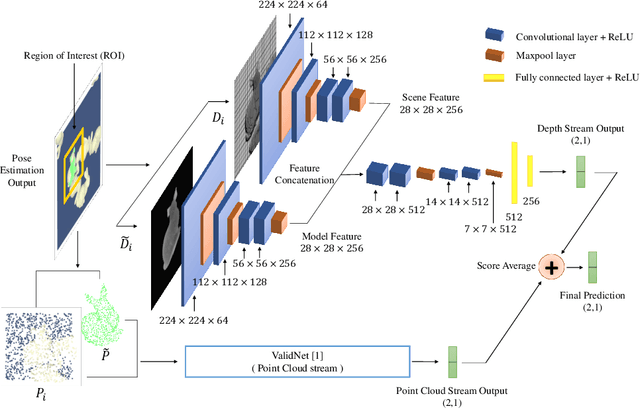

This work presents a novel approach to improve the results of pose estimation by detecting and distinguishing between the occurrence of True and False Positive results. It achieves this by training a binary classifier on the output of an arbitrary pose estimation algorithm, and returns a binary label indicating the validity of the result. We demonstrate that our approach improves upon a state-of-the-art pose estimation result on the Sil\'eane dataset, outperforming a variation of the alternative CullNet method by 4.15% in average class accuracy and 0.73% in overall accuracy at validation. Applying our method can also improve the pose estimation average precision results of Op-Net by 6.06% on average.
Oriented Bounding Boxes for Small and Freely Rotated Objects
Apr 24, 2021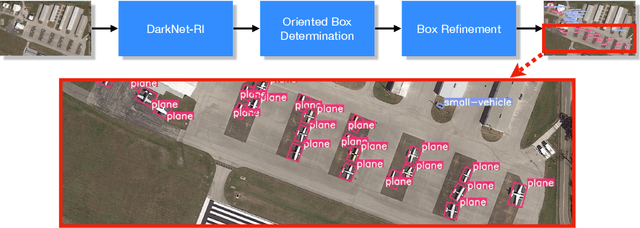

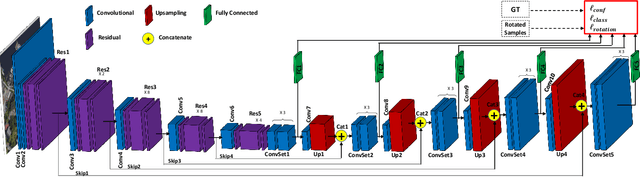

A novel object detection method is presented that handles freely rotated objects of arbitrary sizes, including tiny objects as small as $2\times 2$ pixels. Such tiny objects appear frequently in remotely sensed images, and present a challenge to recent object detection algorithms. More importantly, current object detection methods have been designed originally to accommodate axis-aligned bounding box detection, and therefore fail to accurately localize oriented boxes that best describe freely rotated objects. In contrast, the proposed CNN-based approach uses potential pixel information at multiple scale levels without the need for any external resources, such as anchor boxes.The method encodes the precise location and orientation of features of the target objects at grid cell locations. Unlike existing methods which regress the bounding box location and dimension,the proposed method learns all the required information by classification, which has the added benefit of enabling oriented bounding box detection without any extra computation. It thus infers the bounding boxes only at inference time by finding the minimum surrounding box for every set of the same predicted class labels. Moreover, a rotation-invariant feature representation is applied to each scale, which imposes a regularization constraint to enforce covering the 360 degree range of in-plane rotation of the training samples to share similar features. Evaluations on the xView and DOTA datasets show that the proposed method uniformly improves performance over existing state-of-the-art methods.
Flow-based Autoregressive Structured Prediction of Human Motion
Apr 09, 2021



A new method is proposed for human motion predition by learning temporal and spatial dependencies in an end-to-end deep neural network. The joint connectivity is explicitly modeled using a novel autoregressive structured prediction representation based on flow-based generative models. We learn a latent space of complex body poses in consecutive frames which is conditioned on the high-dimensional structure input sequence. To construct each latent variable, the general and local smoothness of the joint positions are considered in a generative process using conditional normalizing flows. As a result, all frame-level and joint-level continuities in the sequence are preserved in the model. This enables us to parameterize the inter-frame and intra-frame relationships and joint connectivity for robust long-term predictions as well as short-term prediction. Our experiments on two challenging benchmark datasets of Human3.6M and AMASS demonstrate that our proposed method is able to effectively model the sequence information for motion prediction and outperform other techniques in 42 of the 48 total experiment scenarios to set a new state-of-the-art.