 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially-Informed Reconstruction for Pedestrian Trajectory Forecasting
Dec 05, 2024



Pedestrian trajectory prediction remains a challenge for autonomous systems, particularly due to the intricate dynamics of social interactions. Accurate forecasting requires a comprehensive understanding not only of each pedestrian's previous trajectory but also of their interaction with the surrounding environment, an important part of which are other pedestrians moving dynamically in the scene. To learn effective socially-informed representations, we propose a model that uses a reconstructor alongside a conditional variational autoencoder-based trajectory forecasting module. This module generates pseudo-trajectories, which we use as augmentations throughout the training process. To further guide the model towards social awareness, we propose a novel social loss that aids in forecasting of more stable trajectories. We validate our approach through extensive experiments, demonstrating strong performances in comparison to state of-the-art methods on the ETH/UCY and SDD benchmarks.
Context-aware Pedestrian Trajectory Prediction with Multimodal Transformer
Jul 07, 2023
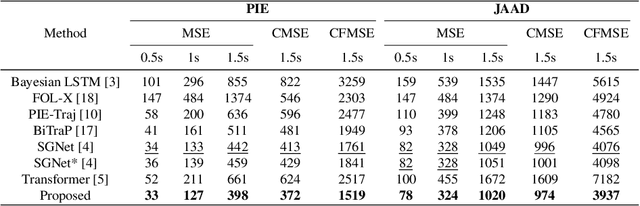

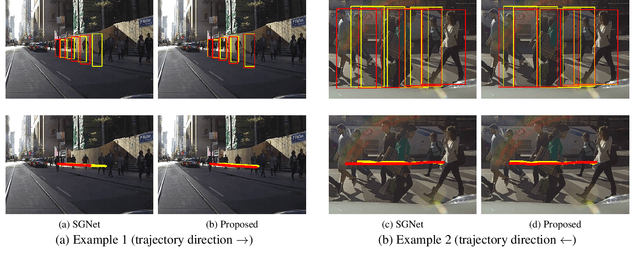
We propose a novel solution for predicting future trajectories of pedestrians. Our method uses a multimodal encoder-decoder transformer architecture, which takes as input both pedestrian locations and ego-vehicle speeds. Notably, our decoder predicts the entire future trajectory in a single-pass and does not perform one-step-ahead prediction, which makes the method effective for embedded edge deployment. We perform detailed experiments and evaluate our method on two popular datasets, PIE and JAAD. Quantitative results demonstrate the superiority of our proposed model over the current state-of-the-art, which consistently achieves the lowest error for 3 time horizons of 0.5, 1.0 and 1.5 seconds. Moreover, the proposed method is significantly faster than the state-of-the-art for the two datasets of PIE and JAAD. Lastly, ablation experiments demonstrate the impact of the key multimodal configuration of our method.
Multiscale Crowd Counting and Localization By Multitask Point Supervision
Feb 21, 2022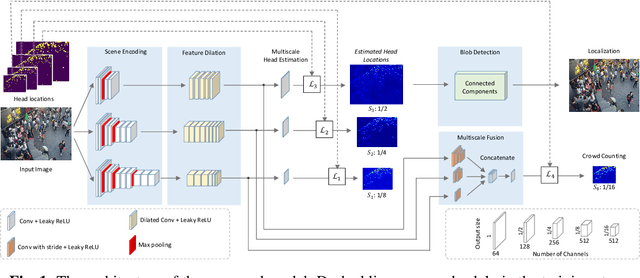
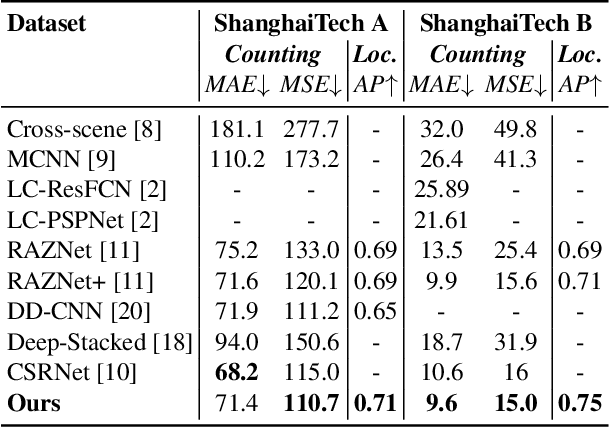

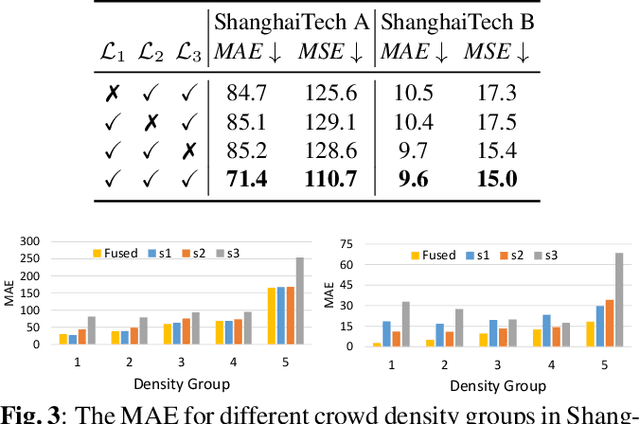
We propose a multitask approach for crowd counting and person localization in a unified framework. As the detection and localization tasks are well-correlated and can be jointly tackled, our model benefits from a multitask solution by learning multiscale representations of encoded crowd images, and subsequently fusing them. In contrast to the relatively more popular density-based methods, our model uses point supervision to allow for crowd locations to be accurately identified. We test our model on two popular crowd counting datasets, ShanghaiTech A and B, and demonstrate that our method achieves strong results on both counting and localization tasks, with MSE measures of 110.7 and 15.0 for crowd counting and AP measures of 0.71 and 0.75 for localization, on ShanghaiTech A and B respectively. Our detailed ablation experiments show the impact of our multiscale approach as well as the effectiveness of the fusion module embedded in our network. Our code is available at: https://github.com/RCVLab-AiimLab/crowd_counting.