 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Pedestrian Trajectory Prediction with Multimodal Transformer
Paper and Code

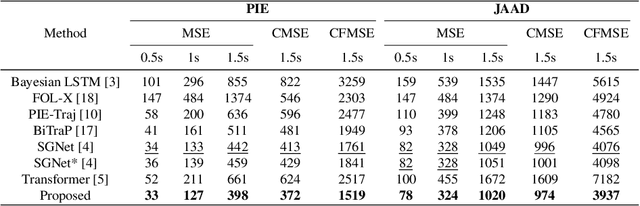

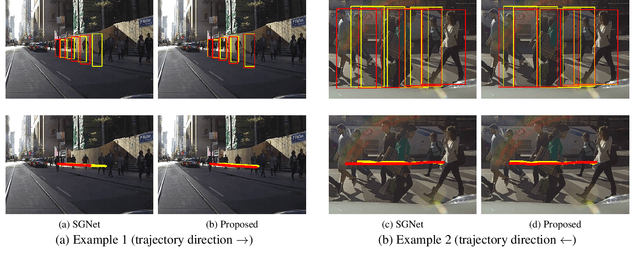
We propose a novel solution for predicting future trajectories of pedestrians. Our method uses a multimodal encoder-decoder transformer architecture, which takes as input both pedestrian locations and ego-vehicle speeds. Notably, our decoder predicts the entire future trajectory in a single-pass and does not perform one-step-ahead prediction, which makes the method effective for embedded edge deployment. We perform detailed experiments and evaluate our method on two popular datasets, PIE and JAAD. Quantitative results demonstrate the superiority of our proposed model over the current state-of-the-art, which consistently achieves the lowest error for 3 time horizons of 0.5, 1.0 and 1.5 seconds. Moreover, the proposed method is significantly faster than the state-of-the-art for the two datasets of PIE and JAAD. Lastly, ablation experiments demonstrate the impact of the key multimodal configuration of our method.