 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow VLAs (Really) Work In Open-World Environments
Apr 23, 2026Vision-language-action models (VLAs) have been extensively used in robotics applications, achieving great success in various manipulation problems. More recently, VLAs have been used in long-horizon tasks and evaluated on benchmarks, such as BEHAVIOR1K (B1K), for solving complex household chores. The common metric for measuring progress in such benchmarks is success rate or partial score based on satisfaction of progress-agnostic criteria, meaning only the final states of the objects are considered, regardless of the events that lead to such states. In this paper, we argue that using such evaluation protocols say little about safety aspects of operation and can potentially exaggerate reported performance, undermining core challenges for future real-world deployment. To this end, we conduct a thorough analysis of state-of-the-art models on the B1K Challenge and evaluate policies in terms of robustness via reproducibility and consistency of performance, safety aspects of policies operations, task awareness, and key elements leading to the incompletion of tasks. We then propose evaluation protocols to capture safety violations to better measure the true performance of the policies in more complex and interactive scenarios. At the end, we discuss the limitations of the existing VLAs and motivate future research.
Do World Action Models Generalize Better than VLAs? A Robustness Study
Mar 23, 2026Robot action planning in the real world is challenging as it requires not only understanding the current state of the environment but also predicting how it will evolve in response to actions. Vision-language-action (VLA), which repurpose large-scale vision-language models for robot action generation using action experts, have achieved notable success across a variety of robotic tasks. Nevertheless, their performance remains constrained by the scope of their training data, exhibiting limited generalization to unseen scenarios and vulnerability to diverse contextual perturbations. More recently, world models have been revisited as an alternative to VLAs. These models, referred to as world action models (WAMs), are built upon world models that are trained on large corpora of video data to predict future states. With minor adaptations, their latent representation can be decoded into robot actions. It has been suggested that their explicit dynamic prediction capacity, combined with spatiotemporal priors acquired from web-scale video pretraining, enables WAMs to generalize more effectively than VLAs. In this paper, we conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations. Our results show that WAMs achieve strong robustness, with LingBot-VA reaching 74.2% success rate on RoboTwin 2.0-Plus and Cosmos-Policy achieving 82.2% on LIBERO-Plus. While VLAs such as $π_{0.5}$ can achieve comparable robustness on certain tasks, they typically require extensive training with diverse robotic datasets and varied learning objectives. Hybrid approaches that partially incorporate video-based dynamic learning exhibit intermediate robustness, highlighting the importance of how video priors are integrated.
Pseudo-keypoint RKHS Learning for Self-supervised 6DoF Pose Estimation
Nov 18, 2023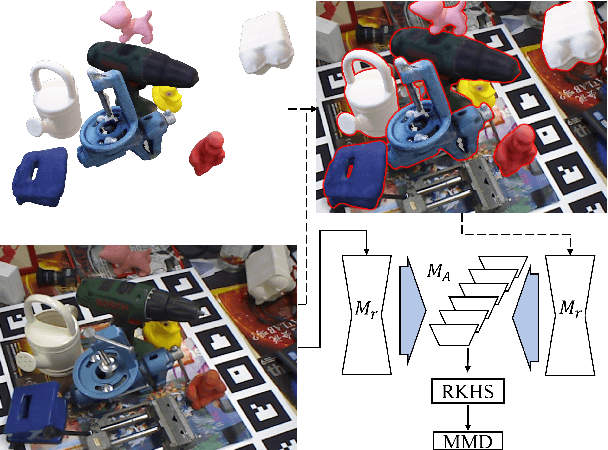
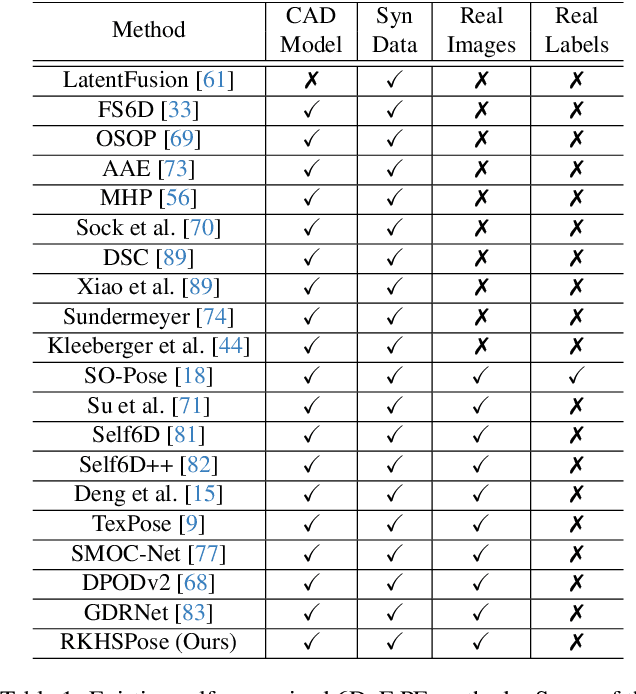
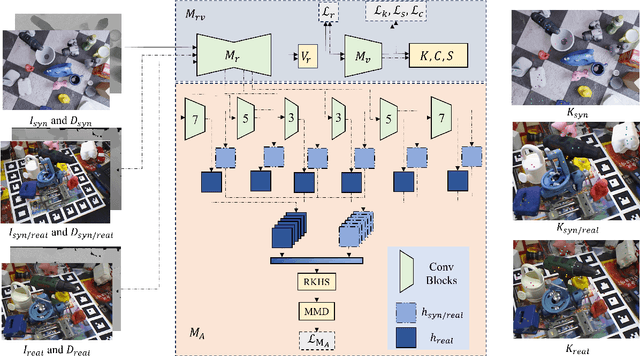
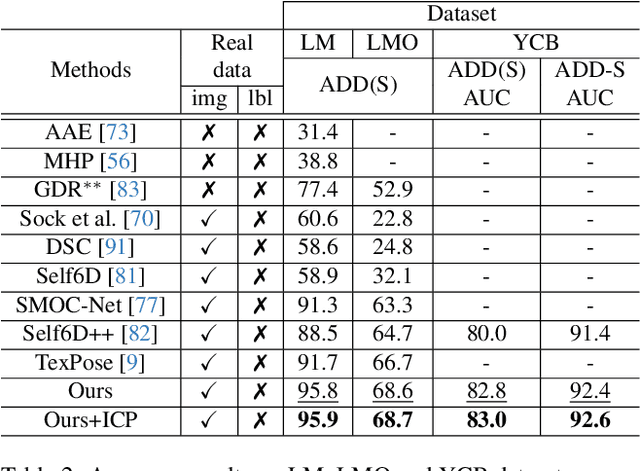
This paper addresses the simulation-to-real domain gap in 6DoF PE, and proposes a novel self-supervised keypoint radial voting-based 6DoF PE framework, effectively narrowing this gap using a learnable kernel in RKHS. We formulate this domain gap as a distance in high-dimensional feature space, distinct from previous iterative matching methods. We propose an adapter network, which evolves the network parameters from the source domain, which has been massively trained on synthetic data with synthetic poses, to the target domain, which is trained on real data. Importantly, the real data training only uses pseudo-poses estimated by pseudo-keypoints, and thereby requires no real groundtruth data annotations. RKHSPose achieves state-of-the-art performance on three commonly used 6DoF PE datasets including LINEMOD (+4.2%), Occlusion LINEMOD (+2%), and YCB-Video (+3%). It also compares favorably to fully supervised methods on all six applicable BOP core datasets, achieving within -10.8% to -0.3% of the top fully supervised results.
Learning Better Keypoints for Multi-Object 6DoF Pose Estimation
Aug 15, 2023


We investigate the impact of pre-defined keypoints for pose estimation, and found that accuracy and efficiency can be improved by training a graph network to select a set of disperse keypoints with similarly distributed votes. These votes, learned by a regression network to accumulate evidence for the keypoint locations, can be regressed more accurately compared to previous heuristic keypoint algorithms. The proposed KeyGNet, supervised by a combined loss measuring both Wassserstein distance and dispersion, learns the color and geometry features of the target objects to estimate optimal keypoint locations. Experiments demonstrate the keypoints selected by KeyGNet improved the accuracy for all evaluation metrics of all seven datasets tested, for three keypoint voting methods. The challenging Occlusion LINEMOD dataset notably improved ADD(S) by +16.4% on PVN3D, and all core BOP datasets showed an AR improvement for all objects, of between +1% and +21.5%. There was also a notable increase in performance when transitioning from single object to multiple object training using KeyGNet keypoints, essentially eliminating the SISO-MIMO gap for Occlusion LINEMOD.
Keypoint Cascade Voting for Point Cloud Based 6DoF Pose Estimation
Oct 14, 2022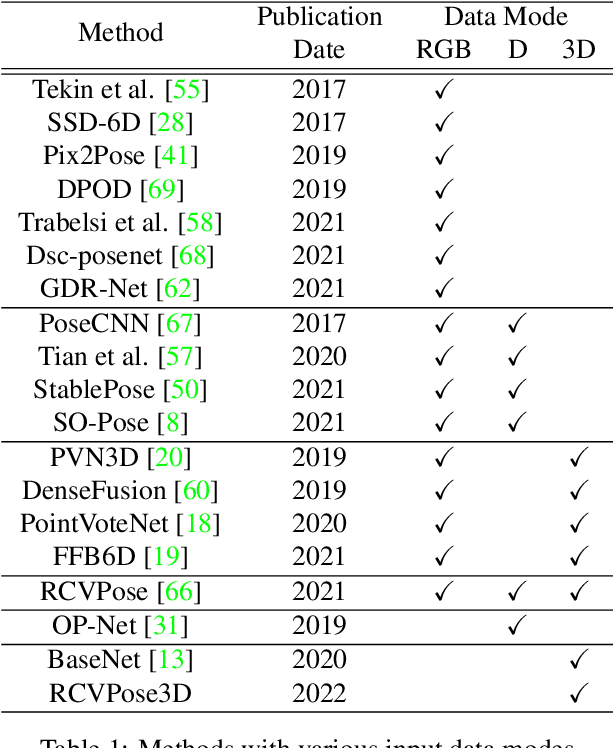
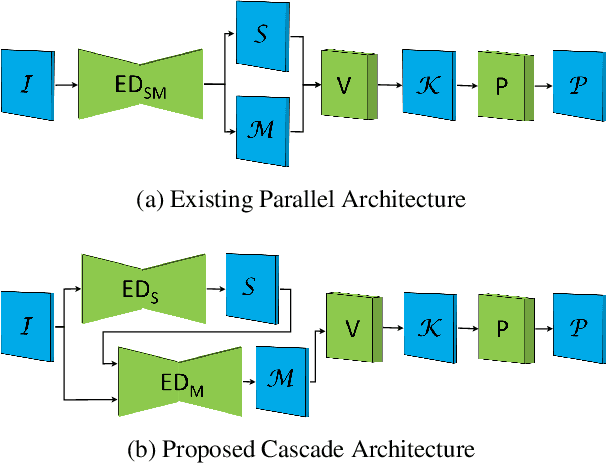
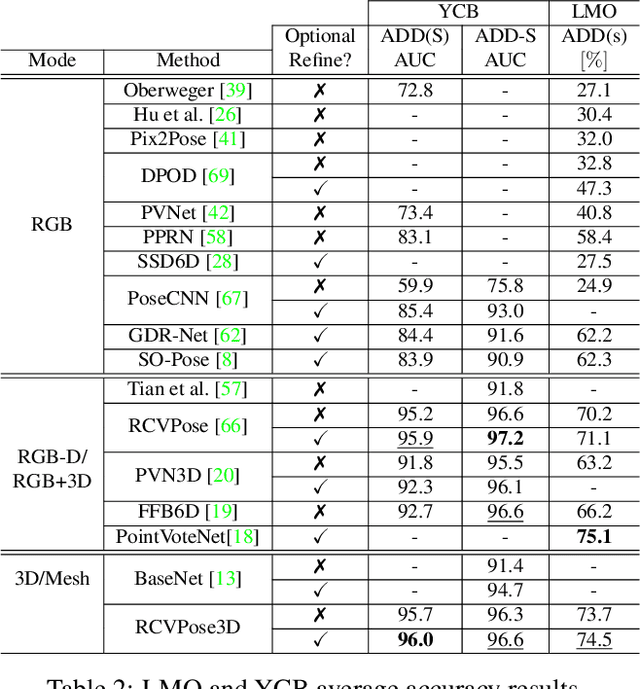
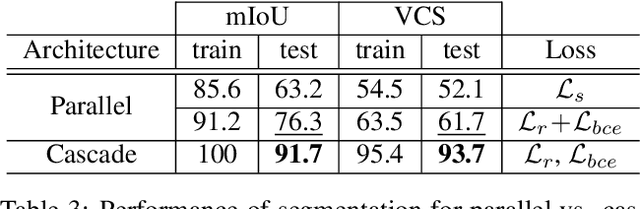
We propose a novel keypoint voting 6DoF object pose estimation method, which takes pure unordered point cloud geometry as input without RGB information. The proposed cascaded keypoint voting method, called RCVPose3D, is based upon a novel architecture which separates the task of semantic segmentation from that of keypoint regression, thereby increasing the effectiveness of both and improving the ultimate performance. The method also introduces a pairwise constraint in between different keypoints to the loss function when regressing the quantity for keypoint estimation, which is shown to be effective, as well as a novel Voter Confident Score which enhances both the learning and inference stages. Our proposed RCVPose3D achieves state-of-the-art performance on the Occlusion LINEMOD (74.5%) and YCB-Video (96.9%) datasets, outperforming existing pure RGB and RGB-D based methods, as well as being competitive with RGB plus point cloud methods.
Vote from the Center: 6 DoF Pose Estimation in RGB-D Images by Radial Keypoint Voting
Apr 07, 2021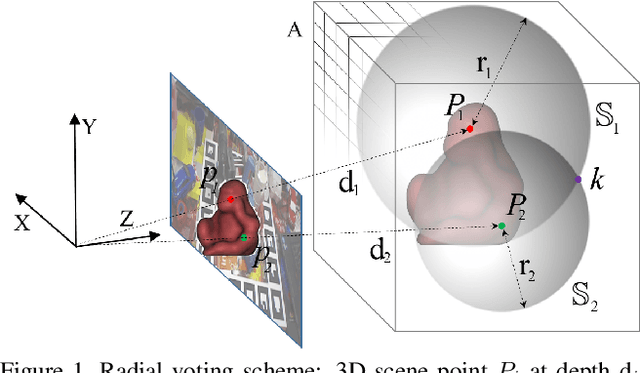
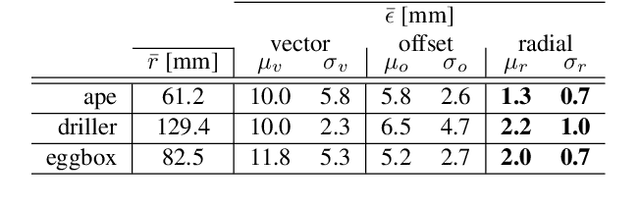
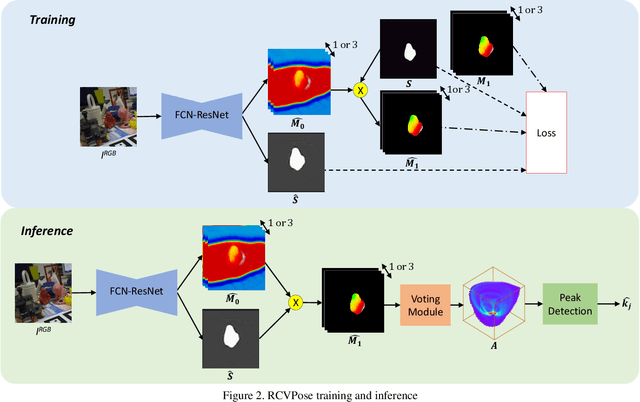
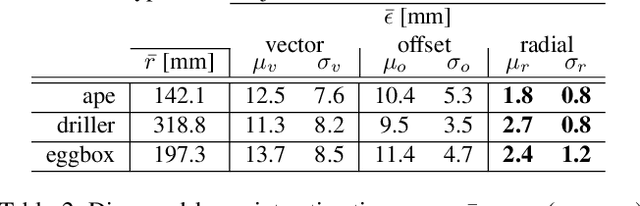
We propose a novel keypoint voting scheme based on intersecting spheres, that is more accurate than existing schemes and allows for a smaller set of more disperse keypoints. The scheme forms the basis of the proposed RCVPose method for 6 DoF pose estimation of 3D objects in RGB-D data, which is particularly effective at handling occlusions. A CNN is trained to estimate the distance between the 3D point corresponding to the depth mode of each RGB pixel, and a set of 3 disperse keypoints defined in the object frame. At inference, a sphere of radius equal to this estimated distance is generated, centered at each 3D point. The surface of these spheres votes to increment a 3D accumulator space, the peaks of which indicate keypoint locations. The proposed radial voting scheme is more accurate than previous vector or offset schemes, and robust to disperse keypoints. Experiments demonstrate RCVPose to be highly accurate and competitive, achieving state-of-the-art results on LINEMOD 99.7%, YCB-Video 97.2% datasets, and notably scoring +7.9% higher than previous methods on the challenging Occlusion LINEMOD 71.1% dataset.