 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Continuous Control of DDPG Actors via Parametrised Activation
Paper and Code
Jun 04, 2020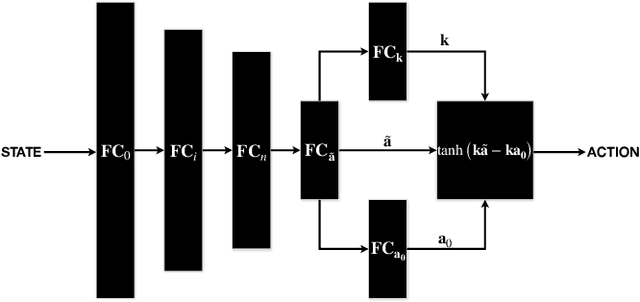
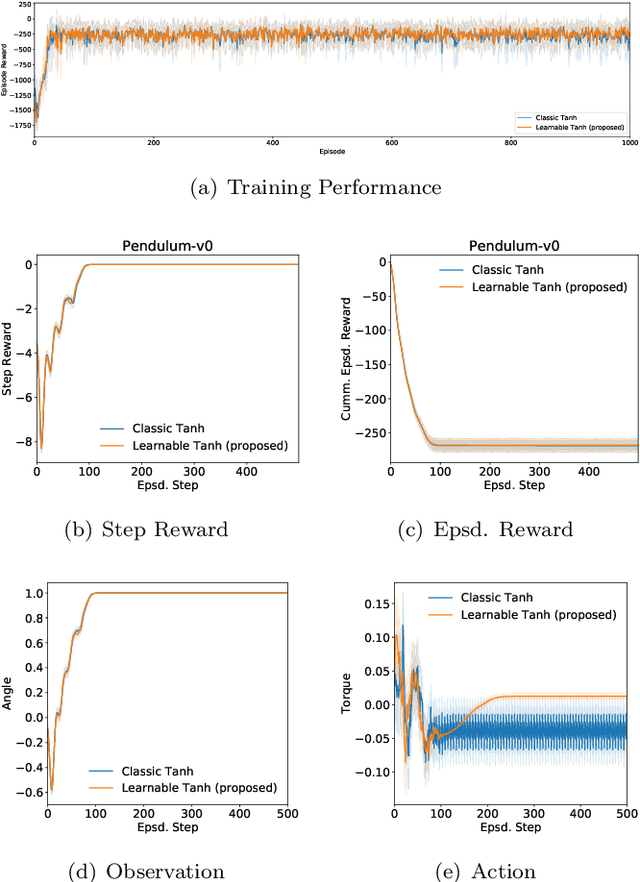
In this paper, we propose enhancing actor-critic reinforcement learning agents by parameterising the final actor layer which produces the actions in order to accommodate the behaviour discrepancy of different actuators, under different load conditions during interaction with the environment. We propose branching the action producing layer in the actor to learn the tuning parameter controlling the activation layer (e.g. Tanh and Sigmoid). The learned parameters are then used to create tailored activation functions for each actuator. We ran experiments on three OpenAI Gym environments, i.e. Pendulum-v0, LunarLanderContinuous-v2 and BipedalWalker-v2. Results have shown an average of 23.15% and 33.80% increase in total episode reward of the LunarLanderContinuous-v2 and BipedalWalker-v2 environments, respectively. There was no significant improvement in Pendulum-v0 environment but the proposed method produces a more stable actuation signal compared to the state-of-the-art method. The proposed method allows the reinforcement learning actor to produce more robust actions that accommodate the discrepancy in the actuators' response functions. This is particularly useful for real life scenarios where actuators exhibit different response functions depending on the load and the interaction with the environment. This also simplifies the transfer learning problem by fine tuning the parameterised activation layers instead of retraining the entire policy every time an actuator is replaced. Finally, the proposed method would allow better accommodation to biological actuators (e.g. muscles) in biomechanical systems.