 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Accident Risk Forecasting using Contextual Vision Transformers
Paper and Code
Sep 20, 2022
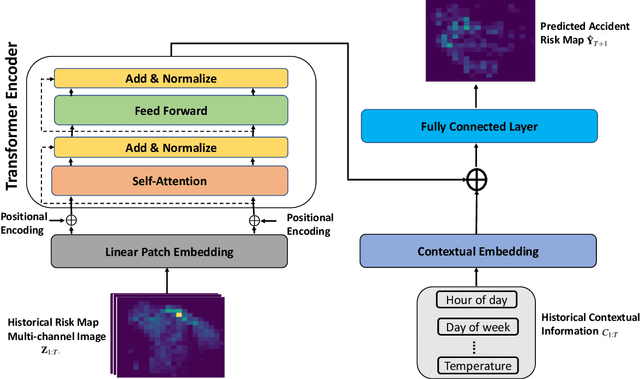
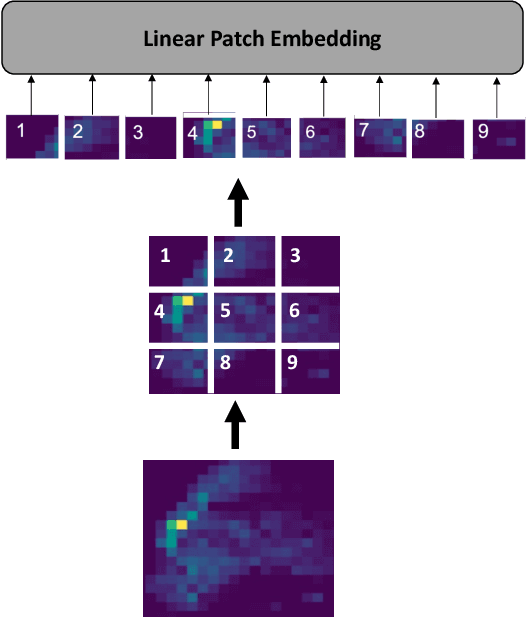
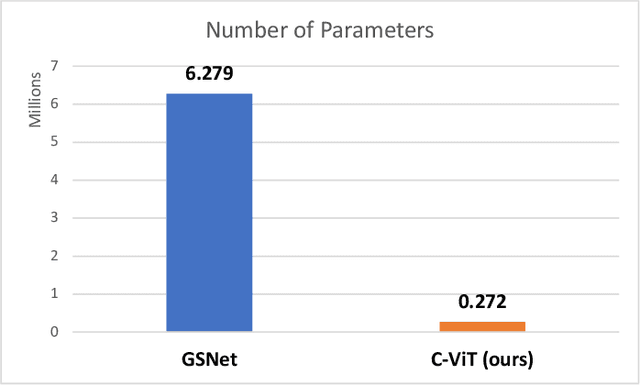
Recently, the problem of traffic accident risk forecasting has been getting the attention of the intelligent transportation systems community due to its significant impact on traffic clearance. This problem is commonly tackled in the literature by using data-driven approaches that model the spatial and temporal incident impact, since they were shown to be crucial for the traffic accident risk forecasting problem. To achieve this, most approaches build different architectures to capture the spatio-temporal correlations features, making them inefficient for large traffic accident datasets. Thus, in this work, we are proposing a novel unified framework, namely a contextual vision transformer, that can be trained in an end-to-end approach which can effectively reason about the spatial and temporal aspects of the problem while providing accurate traffic accident risk predictions. We evaluate and compare the performance of our proposed methodology against baseline approaches from the literature across two large-scale traffic accident datasets from two different geographical locations. The results have shown a significant improvement with roughly 2\% in RMSE score in comparison to previous state-of-art works (SoTA) in the literature. Moreover, our proposed approach has outperformed the SoTA technique over the two datasets while only requiring 23x fewer computational requirements.