 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Study on Decomposition-Based Deep Ensemble Learning for Traffic Flow Forecasting
Nov 06, 2024Traffic flow forecasting is a crucial task in intelligent transport systems. Deep learning offers an effective solution, capturing complex patterns in time-series traffic flow data to enable the accurate prediction. However, deep learning models are prone to overfitting the intricate details of flow data, leading to poor generalisation. Recent studies suggest that decomposition-based deep ensemble learning methods may address this issue by breaking down a time series into multiple simpler signals, upon which deep learning models are built and ensembled to generate the final prediction. However, few studies have compared the performance of decomposition-based ensemble methods with non-decomposition-based ones which directly utilise raw time-series data. This work compares several decomposition-based and non-decomposition-based deep ensemble learning methods. Experimental results on three traffic datasets demonstrate the superiority of decomposition-based ensemble methods, while also revealing their sensitivity to aggregation strategies and forecasting horizons.
Predicting the duration of traffic incidents for Sydney greater metropolitan area using machine learning methods
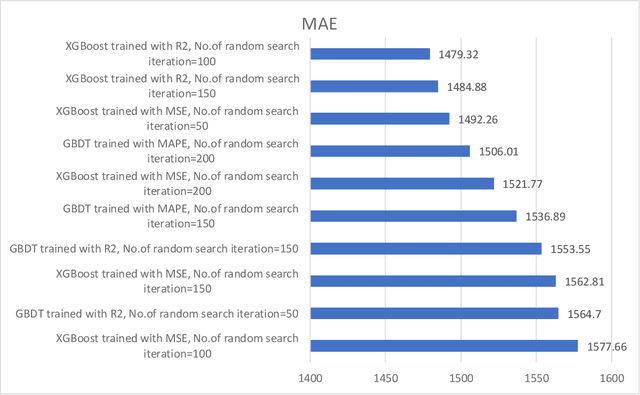
Jun 27, 2024This research presents a comprehensive approach to predicting the duration of traffic incidents and classifying them as short-term or long-term across the Sydney Metropolitan Area. Leveraging a dataset that encompasses detailed records of traffic incidents, road network characteristics, and socio-economic indicators, we train and evaluate a variety of advanced machine learning models including Gradient Boosted Decision Trees (GBDT), Random Forest, LightGBM, and XGBoost. The models are assessed using Root Mean Square Error (RMSE) for regression tasks and F1 score for classification tasks. Our experimental results demonstrate that XGBoost and LightGBM outperform conventional models with XGBoost achieving the lowest RMSE of 33.7 for predicting incident duration and highest classification F1 score of 0.62 for a 30-minute duration threshold. For classification, the 30-minute threshold balances performance with 70.84\% short-term duration classification accuracy and 62.72\% long-term duration classification accuracy. Feature importance analysis, employing both tree split counts and SHAP values, identifies the number of affected lanes, traffic volume, and types of primary and secondary vehicles as the most influential features. The proposed methodology not only achieves high predictive accuracy but also provides stakeholders with vital insights into factors contributing to incident durations. These insights enable more informed decision-making for traffic management and response strategies. The code is available by the link: https://github.com/Future-Mobility-Lab/SydneyIncidents
Integrating Large Language Models for Severity Classification in Traffic Incident Management: A Machine Learning Approach
Mar 20, 2024This study evaluates the impact of large language models on enhancing machine learning processes for managing traffic incidents. It examines the extent to which features generated by modern language models improve or match the accuracy of predictions when classifying the severity of incidents using accident reports. Multiple comparisons performed between combinations of language models and machine learning algorithms, including Gradient Boosted Decision Trees, Random Forests, and Extreme Gradient Boosting. Our research uses both conventional and language model-derived features from texts and incident reports, and their combinations to perform severity classification. Incorporating features from language models with those directly obtained from incident reports has shown to improve, or at least match, the performance of machine learning techniques in assigning severity levels to incidents, particularly when employing Random Forests and Extreme Gradient Boosting methods. This comparison was quantified using the F1-score over uniformly sampled data sets to obtain balanced severity classes. The primary contribution of this research is in the demonstration of how Large Language Models can be integrated into machine learning workflows for incident management, thereby simplifying feature extraction from unstructured text and enhancing or matching the precision of severity predictions using conventional machine learning pipeline. The engineering application of this research is illustrated through the effective use of these language processing models to refine the modelling process for incident severity classification. This work provides significant insights into the application of language processing capabilities in combination with traditional data for improving machine learning pipelines in the context of classifying incident severity.
Training Physics-Informed Neural Networks via Multi-Task Optimization for Traffic Density Prediction
Jul 08, 2023Physics-informed neural networks (PINNs) are a newly emerging research frontier in machine learning, which incorporate certain physical laws that govern a given data set, e.g., those described by partial differential equations (PDEs), into the training of the neural network (NN) based on such a data set. In PINNs, the NN acts as the solution approximator for the PDE while the PDE acts as the prior knowledge to guide the NN training, leading to the desired generalization performance of the NN when facing the limited availability of training data. However, training PINNs is a non-trivial task largely due to the complexity of the loss composed of both NN and physical law parts. In this work, we propose a new PINN training framework based on the multi-task optimization (MTO) paradigm. Under this framework, multiple auxiliary tasks are created and solved together with the given (main) task, where the useful knowledge from solving one task is transferred in an adaptive mode to assist in solving some other tasks, aiming to uplift the performance of solving the main task. We implement the proposed framework and apply it to train the PINN for addressing the traffic density prediction problem. Experimental results demonstrate that our proposed training framework leads to significant performance improvement in comparison to the traditional way of training the PINN.
Traffic Accident Risk Forecasting using Contextual Vision Transformers
Sep 20, 2022
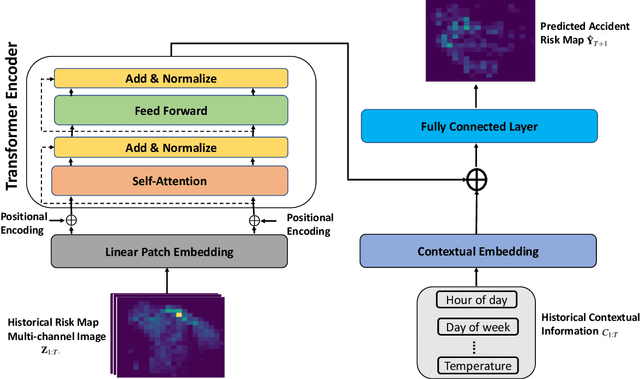
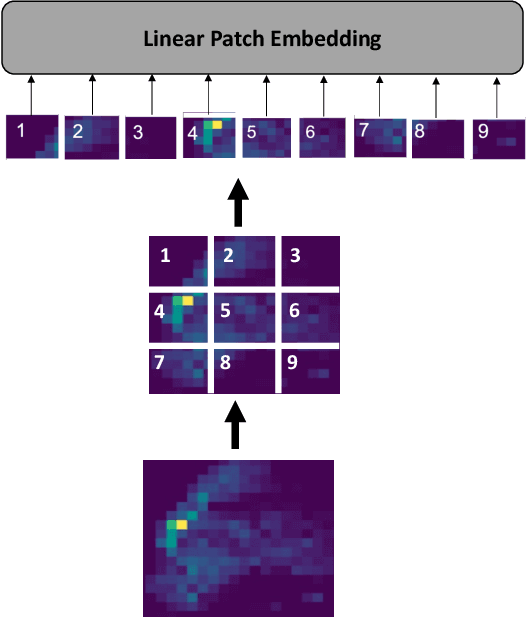
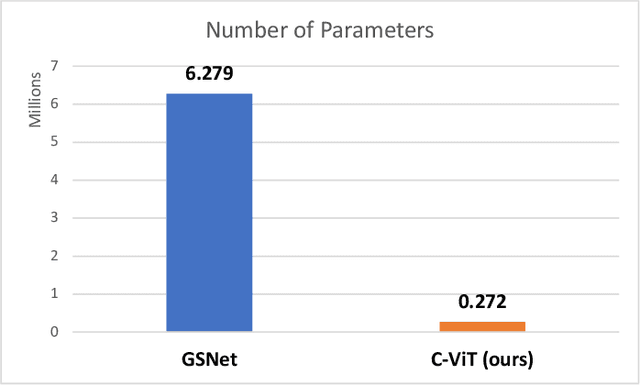
Recently, the problem of traffic accident risk forecasting has been getting the attention of the intelligent transportation systems community due to its significant impact on traffic clearance. This problem is commonly tackled in the literature by using data-driven approaches that model the spatial and temporal incident impact, since they were shown to be crucial for the traffic accident risk forecasting problem. To achieve this, most approaches build different architectures to capture the spatio-temporal correlations features, making them inefficient for large traffic accident datasets. Thus, in this work, we are proposing a novel unified framework, namely a contextual vision transformer, that can be trained in an end-to-end approach which can effectively reason about the spatial and temporal aspects of the problem while providing accurate traffic accident risk predictions. We evaluate and compare the performance of our proposed methodology against baseline approaches from the literature across two large-scale traffic accident datasets from two different geographical locations. The results have shown a significant improvement with roughly 2\% in RMSE score in comparison to previous state-of-art works (SoTA) in the literature. Moreover, our proposed approach has outperformed the SoTA technique over the two datasets while only requiring 23x fewer computational requirements.
Traffic incident duration prediction via a deep learning framework for text description encoding
Sep 19, 2022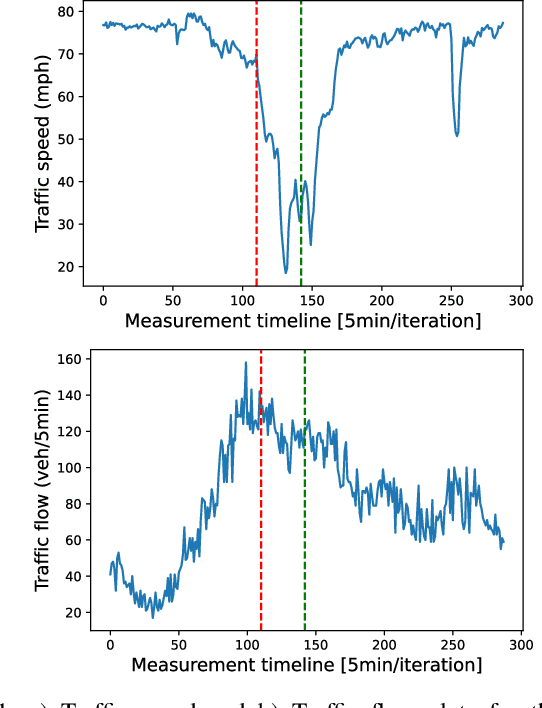
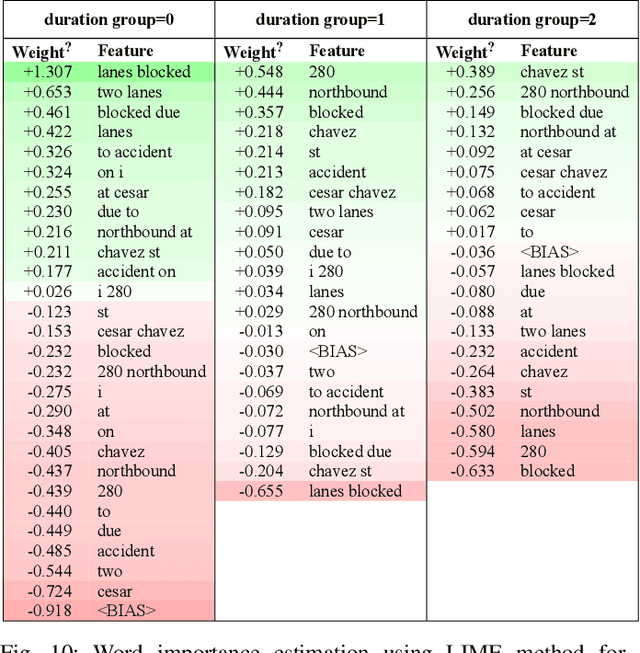
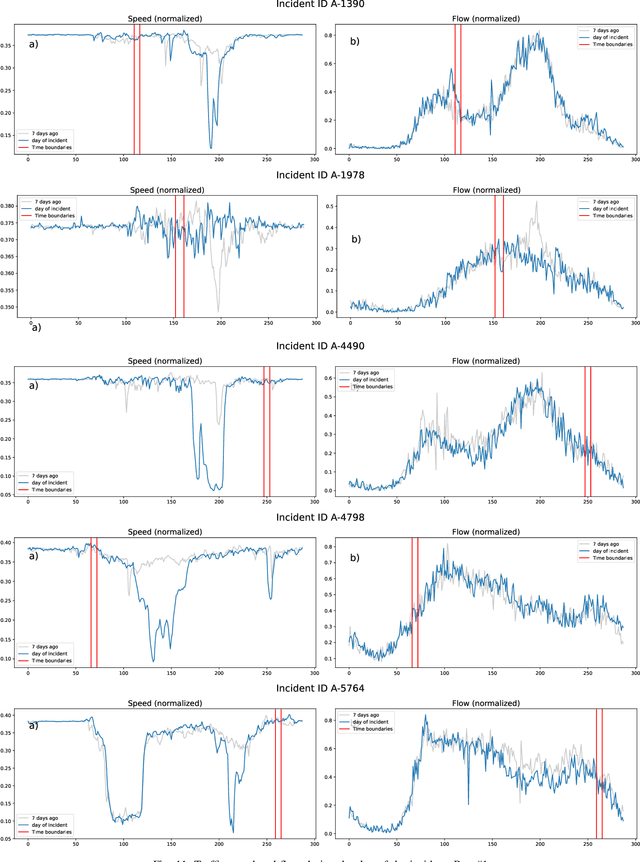
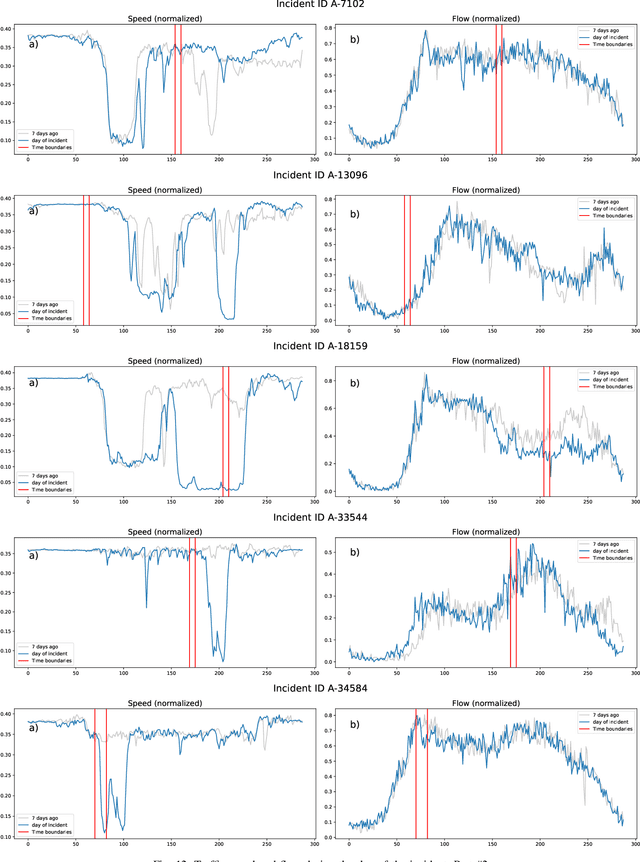
Predicting the traffic incident duration is a hard problem to solve due to the stochastic nature of incident occurrence in space and time, a lack of information at the beginning of a reported traffic disruption, and lack of advanced methods in transport engineering to derive insights from past accidents. This paper proposes a new fusion framework for predicting the incident duration from limited information by using an integration of machine learning with traffic flow/speed and incident description as features, encoded via several Deep Learning methods (ANN autoencoder and character-level LSTM-ANN sentiment classifier). The paper constructs a cross-disciplinary modelling approach in transport and data science. The approach improves the incident duration prediction accuracy over the top-performing ML models applied to baseline incident reports. Results show that our proposed method can improve the accuracy by $60\%$ when compared to standard linear or support vector regression models, and a further $7\%$ improvement with respect to the hybrid deep learning auto-encoded GBDT model which seems to outperform all other models. The application area is the city of San Francisco, rich in both traffic incident logs (Countrywide Traffic Accident Data set) and past historical traffic congestion information (5-minute precision measurements from Caltrans Performance Measurement System).
Incident duration prediction using a bi-level machine learning framework with outlier removal and intra-extra joint optimisation
May 18, 2022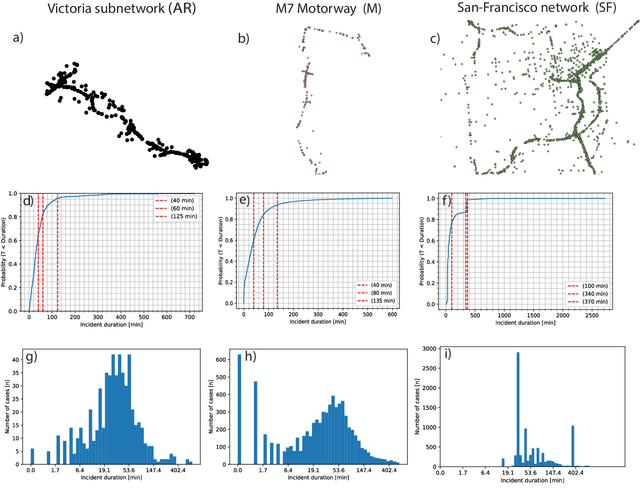

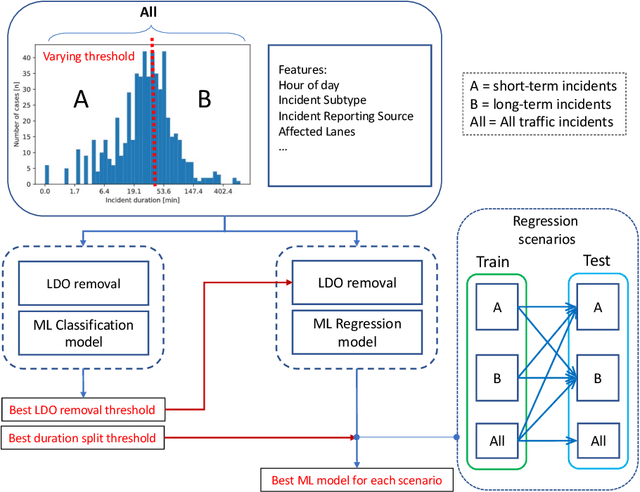

Predicting the duration of traffic incidents is a challenging task due to the stochastic nature of events. The ability to accurately predict how long accidents will last can provide significant benefits to both end-users in their route choice and traffic operation managers in handling of non-recurrent traffic congestion. This paper presents a novel bi-level machine learning framework enhanced with outlier removal and intra-extra joint optimisation for predicting the incident duration on three heterogeneous data sets collected for both arterial roads and motorways from Sydney, Australia and San-Francisco, U.S.A. Firstly, we use incident data logs to develop a binary classification prediction approach, which allows us to classify traffic incidents as short-term or long-term. We find the optimal threshold between short-term versus long-term traffic incident duration, targeting both class balance and prediction performance while also comparing the binary versus multi-class classification approaches. Secondly, for more granularity of the incident duration prediction to the minute level, we propose a new Intra-Extra Joint Optimisation algorithm (IEO-ML) which extends multiple baseline ML models tested against several regression scenarios across the data sets. Final results indicate that: a) 40-45 min is the best split threshold for identifying short versus long-term incidents and that these incidents should be modelled separately, b) our proposed IEO-ML approach significantly outperforms baseline ML models in $66\%$ of all cases showcasing its great potential for accurate incident duration prediction. Lastly, we evaluate the feature importance and show that time, location, incident type, incident reporting source and weather at among the top 10 critical factors which influence how long incidents will last.
Boosted Genetic Algorithm using Machine Learning for traffic control optimization
Mar 11, 2021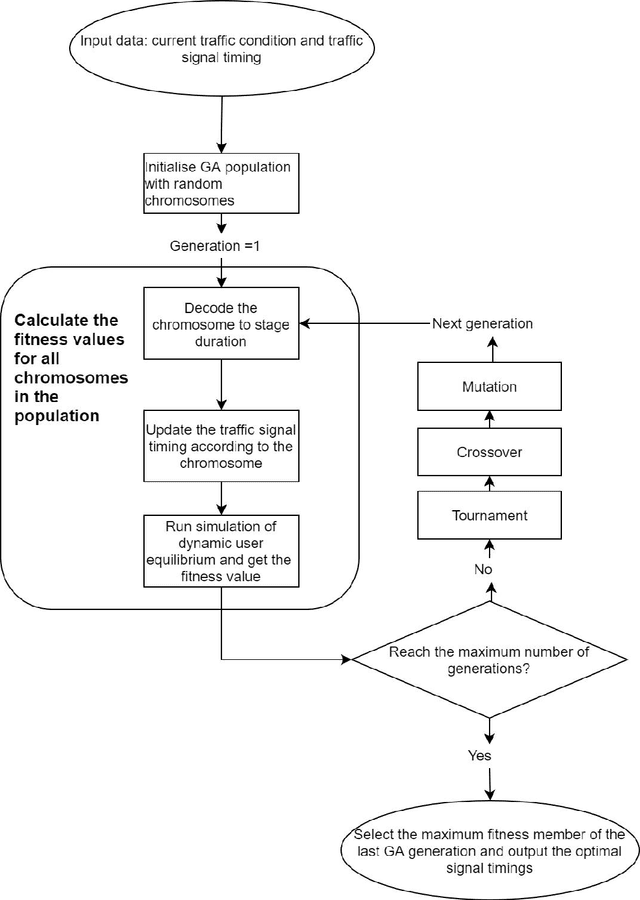
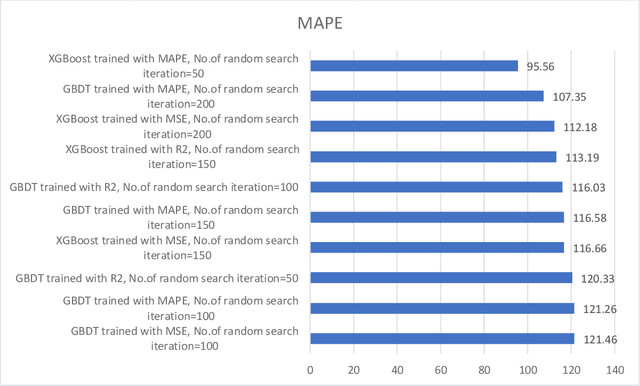
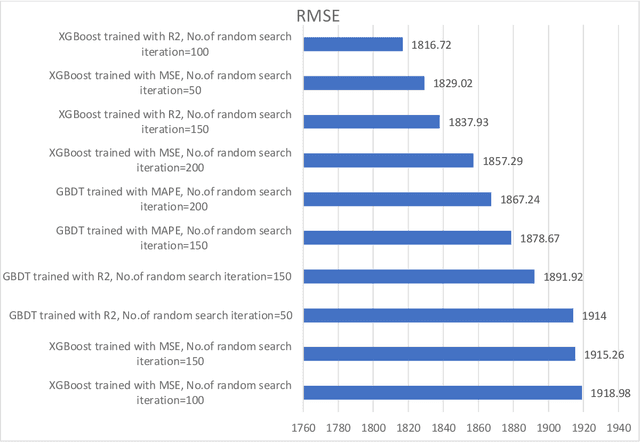
Traffic control optimization is a challenging task for various traffic centers around the world and the majority of existing approaches focus only on developing adaptive methods under normal (recurrent) traffic conditions. Optimizing the control plans when severe incidents occur still remains an open problem, especially when a high number of lanes or entire intersections are affected. This paper aims at tackling this problem and presents a novel methodology for optimizing the traffic signal timings in signalized urban intersections, under non-recurrent traffic incidents. With the purpose of producing fast and reliable decisions, we combine the fast running Machine Learning (ML) algorithms and the reliable Genetic Algorithms (GA) into a single optimization framework. As a benchmark, we first start with deploying a typical GA algorithm by considering the phase duration as the decision variable and the objective function to minimize the total travel time in the network. We fine tune the GA for crossover, mutation, fitness calculation and obtain the optimal parameters. Secondly, we train various machine learning regression models to predict the total travel time of the studied traffic network, and select the best performing regressor which we further hyper-tune to find the optimal training parameters. Lastly, we propose a new algorithm BGA-ML combining the GA algorithm and the extreme-gradient decision-tree, which is the best performing regressor, together in a single optimization framework. Comparison and results show that the new BGA-ML is much faster than the original GA algorithm and can be successfully applied under non-recurrent incident conditions.
Graph modelling approaches for motorway traffic flow prediction
Jul 04, 2020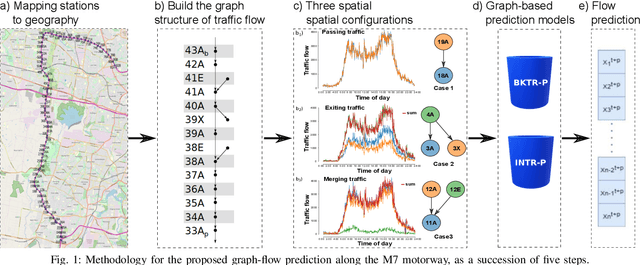

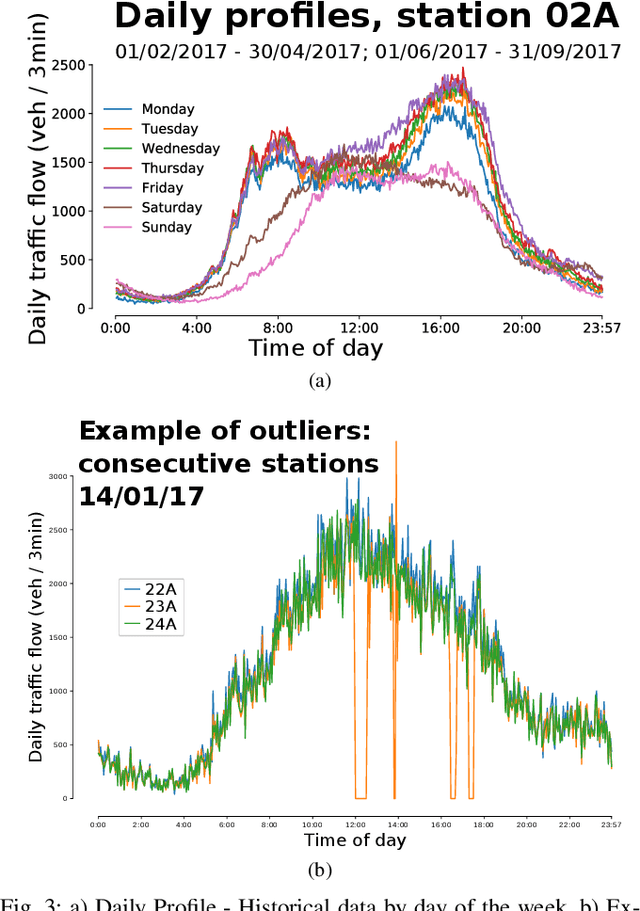
Traffic flow prediction, particularly in areas that experience highly dynamic flows such as motorways, is a major issue faced in traffic management. Due to increasingly large volumes of data sets being generated every minute, deep learning methods have been used extensively in the latest years for both short and long term prediction. However, such models, despite their efficiency, need large amounts of historical information to be provided, and they take a considerable amount of time and computing resources to train, validate and test. This paper presents two new spatial-temporal approaches for building accurate short-term prediction along a popular motorway in Sydney, by making use of the graph structure of the motorway network (including exits and entries). The methods are built on proximity-based approaches, denoted backtracking and interpolation, which uses the most recent and closest traffic flow information for each of the target counting stations along the motorway. The results indicate that for short-term predictions (less than 10 minutes into the future), the proposed graph-based approaches outperform state-of-the-art deep learning models, such as long-term short memory, convolutional neuronal networks or hybrid models.
Traffic congestion anomaly detection and prediction using deep learning
Jun 23, 2020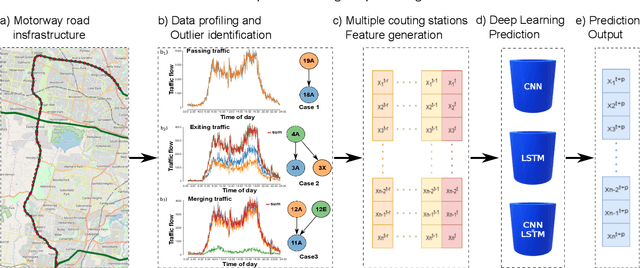

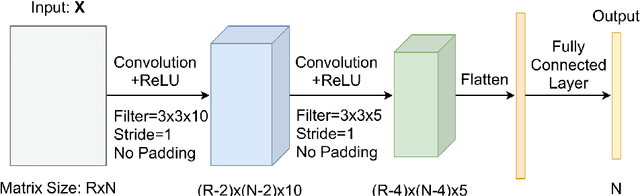
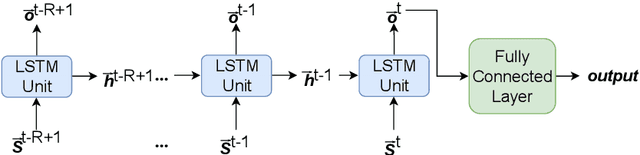
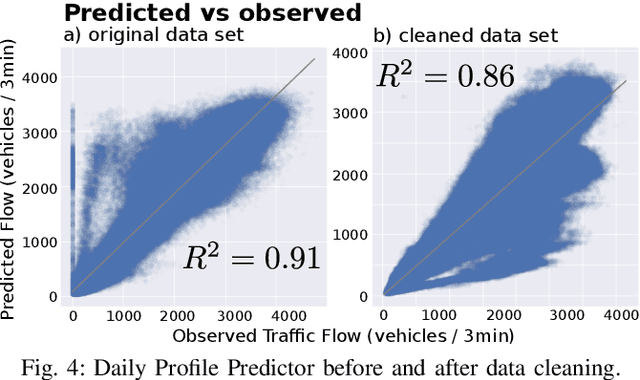
Congestion prediction represents a major priority for traffic management centres around the world to ensure timely incident response handling. The increasing amounts of generated traffic data have been used to train machine learning predictors for traffic, however, this is a challenging task due to inter-dependencies of traffic flow both in time and space. Recently, deep learning techniques have shown significant prediction improvements over traditional models, however, open questions remain around their applicability, accuracy and parameter tuning. This paper brings two contributions in terms of: 1) applying an outlier detection an anomaly adjustment method based on incoming and historical data streams, and 2) proposing an advanced deep learning framework for simultaneously predicting the traffic flow, speed and occupancy on a large number of monitoring stations along a highly circulated motorway in Sydney, Australia, including exit and entry loop count stations, and over varying training and prediction time horizons. The spatial and temporal features extracted from the 36.34 million data points are used in various deep learning architectures that exploit their spatial structure (convolutional neuronal networks), their temporal dynamics (recurrent neuronal networks), or both through a hybrid spatio-temporal modelling (CNN-LSTM). We show that our deep learning models consistently outperform traditional methods, and we conduct a comparative analysis of the optimal time horizon of historical data required to predict traffic flow at different time points in the future. Lastly, we prove that the anomaly adjustment method brings significant improvements to using deep learning in both time and space.