 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATO: Multi-objective Personalized Alignment with Test-time Optimization for Large Language Models
May 25, 2026Aligning large language models (LLMs) with diverse and multifaceted user preferences is a fundamental challenge in personalized AI systems. Existing multi-objective alignment methods either rely on costly training or require pre-trained reward models for each preference, making it difficult for them to adapt to evolving preferences. Prompt-based personalization offers a training-free alternative, but prompting alone often provides limited steerability, as LLMs may overemphasize or overlook certain preferences and fail to give users reliable control over the relative importance of different objectives when conflicts arise, leading to suboptimal alignment. In this paper, we introduce MATO, a training-free framework for Multi-objective personalized Alignment with Test-time Optimization. MATO formulates personalization as a test-time optimization problem that steers the relative importance of multiple objectives through controllable weights during decoding, without modifying model parameters or requiring external reward models. Specifically, a reward discovery module recovers preference rewards directly from the backbone LLM for diverse objectives specified in natural language, while a weight optimization module dynamically adjusts objective weights based on the user's initial preferences and the partially generated response to balance competing objectives during generation. The resulting rewards and weights jointly guide an online optimization procedure over the token distribution, enabling better alignment with the target objectives. Extensive experiments across multiple datasets and backbone LLMs show that MATO consistently outperforms strong baselines, achieving Pareto-improving multi-objective alignment and stronger steerability. These results highlight test-time optimization as a promising direction for scalable, controllable, and model-agnostic personalized alignment.
Optimizing Specific and Shared Parameters for Efficient Parameter Tuning
Apr 04, 2025Foundation models, with a vast number of parameters and pretraining on massive datasets, achieve state-of-the-art performance across various applications. However, efficiently adapting them to downstream tasks with minimal computational overhead remains a challenge. Parameter-Efficient Transfer Learning (PETL) addresses this by fine-tuning only a small subset of parameters while preserving pre-trained knowledge. In this paper, we propose SaS, a novel PETL method that effectively mitigates distributional shifts during fine-tuning. SaS integrates (1) a shared module that captures common statistical characteristics across layers using low-rank projections and (2) a layer-specific module that employs hypernetworks to generate tailored parameters for each layer. This dual design ensures an optimal balance between performance and parameter efficiency while introducing less than 0.05% additional parameters, making it significantly more compact than existing methods. Extensive experiments on diverse downstream tasks, few-shot settings and domain generalization demonstrate that SaS significantly enhances performance while maintaining superior parameter efficiency compared to existing methods, highlighting the importance of capturing both shared and layer-specific information in transfer learning. Code and data are available at https://anonymous.4open.science/r/SaS-PETL-3565.
Agnostic Sharpness-Aware Minimization
Jun 12, 2024


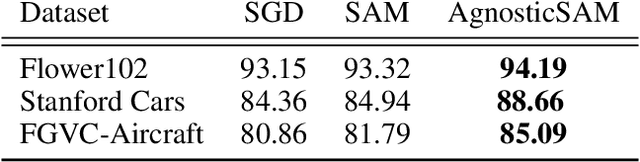
Sharpness-aware minimization (SAM) has been instrumental in improving deep neural network training by minimizing both the training loss and the sharpness of the loss landscape, leading the model into flatter minima that are associated with better generalization properties. In another aspect, Model-Agnostic Meta-Learning (MAML) is a framework designed to improve the adaptability of models. MAML optimizes a set of meta-models that are specifically tailored for quick adaptation to multiple tasks with minimal fine-tuning steps and can generalize well with limited data. In this work, we explore the connection between SAM and MAML, particularly in terms of enhancing model generalization. We introduce Agnostic-SAM, a novel approach that combines the principles of both SAM and MAML. Agnostic-SAM adapts the core idea of SAM by optimizing the model towards wider local minima using training data, while concurrently maintaining low loss values on validation data. By doing so, it seeks flatter minima that are not only robust to small perturbations but also less vulnerable to data distributional shift problems. Our experimental results demonstrate that Agnostic-SAM significantly improves generalization over baselines across a range of datasets and under challenging conditions such as noisy labels and data limitation.
Frequency Attention for Knowledge Distillation
Mar 09, 2024Knowledge distillation is an attractive approach for learning compact deep neural networks, which learns a lightweight student model by distilling knowledge from a complex teacher model. Attention-based knowledge distillation is a specific form of intermediate feature-based knowledge distillation that uses attention mechanisms to encourage the student to better mimic the teacher. However, most of the previous attention-based distillation approaches perform attention in the spatial domain, which primarily affects local regions in the input image. This may not be sufficient when we need to capture the broader context or global information necessary for effective knowledge transfer. In frequency domain, since each frequency is determined from all pixels of the image in spatial domain, it can contain global information about the image. Inspired by the benefits of the frequency domain, we propose a novel module that functions as an attention mechanism in the frequency domain. The module consists of a learnable global filter that can adjust the frequencies of student's features under the guidance of the teacher's features, which encourages the student's features to have patterns similar to the teacher's features. We then propose an enhanced knowledge review-based distillation model by leveraging the proposed frequency attention module. The extensive experiments with various teacher and student architectures on image classification and object detection benchmark datasets show that the proposed approach outperforms other knowledge distillation methods.
Optimal Transport Model Distributional Robustness
Jun 07, 2023Distributional robustness is a promising framework for training deep learning models that are less vulnerable to adversarial examples and data distribution shifts. Previous works have mainly focused on exploiting distributional robustness in data space. In this work, we explore an optimal transport-based distributional robustness framework on model spaces. Specifically, we examine a model distribution in a Wasserstein ball of a given center model distribution that maximizes the loss. We have developed theories that allow us to learn the optimal robust center model distribution. Interestingly, through our developed theories, we can flexibly incorporate the concept of sharpness awareness into training a single model, ensemble models, and Bayesian Neural Networks by considering specific forms of the center model distribution, such as a Dirac delta distribution over a single model, a uniform distribution over several models, and a general Bayesian Neural Network. Furthermore, we demonstrate that sharpness-aware minimization (SAM) is a specific case of our framework when using a Dirac delta distribution over a single model, while our framework can be viewed as a probabilistic extension of SAM. We conduct extensive experiments to demonstrate the usefulness of our framework in the aforementioned settings, and the results show remarkable improvements in our approaches to the baselines.
Flat Seeking Bayesian Neural Networks
Feb 09, 2023Bayesian Neural Networks (BNNs) offer a probabilistic interpretation for deep learning models by imposing a prior distribution over model parameters and inferencing a posterior distribution based on observed data. The model sampled from the posterior distribution can be used for providing ensemble predictions and quantifying prediction uncertainty. It is well-known that deep learning models with a lower sharpness have a better generalization ability. Nonetheless, existing posterior inferences are not aware of sharpness/flatness, hence possibly leading to high sharpness for the models sampled from it. In this paper, we develop theories, the Bayesian setting, and the variational inference approach for the sharpness-aware posterior. Specifically, the models sampled from our sharpness-aware posterior and the optimal approximate posterior estimating this sharpness-aware posterior have a better flatness, hence possibly possessing a higher generalization ability. We conduct experiments by leveraging the sharpness-aware posterior with the state-of-the-art Bayesian Neural Networks, showing that the flat-seeking counterparts outperform their baselines in all metrics of interest.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022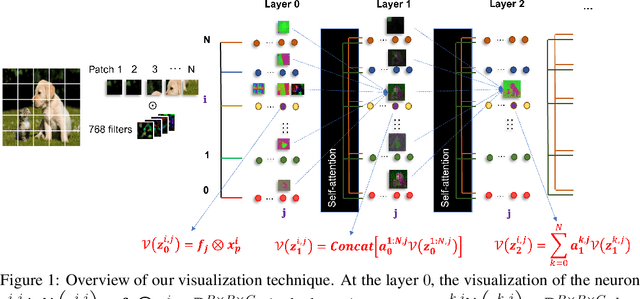
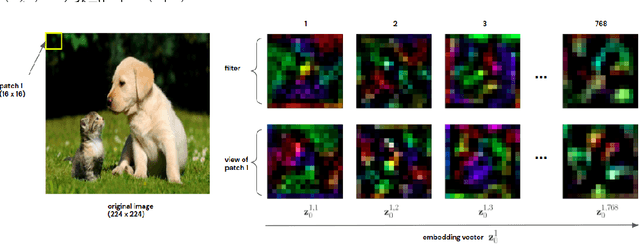


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization
ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection
Oct 14, 2021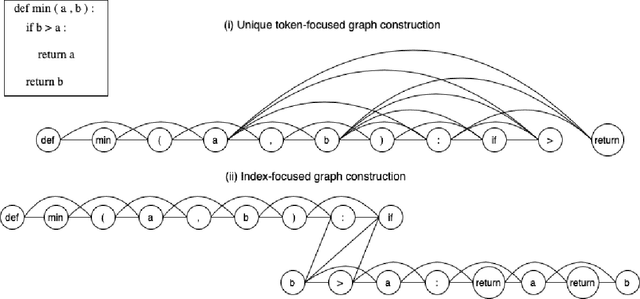
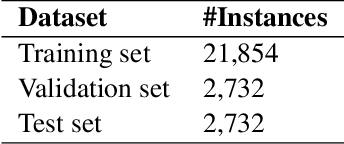
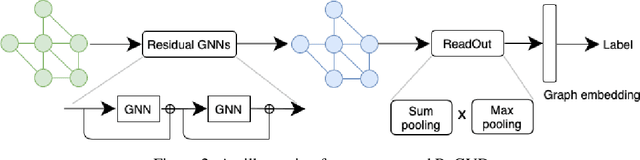
Identifying vulnerabilities in the source code is essential to protect the software systems from cyber security attacks. It, however, is also a challenging step that requires specialized expertise in security and code representation. Inspired by the successful applications of pre-trained programming language (PL) models such as CodeBERT and graph neural networks (GNNs), we propose ReGVD, a general and novel graph neural network-based model for vulnerability detection. In particular, ReGVD views a given source code as a flat sequence of tokens and then examines two effective methods of utilizing unique tokens and indexes respectively to construct a single graph as an input, wherein node features are initialized only by the embedding layer of a pre-trained PL model. Next, ReGVD leverages a practical advantage of residual connection among GNN layers and explores a beneficial mixture of graph-level sum and max poolings to return a graph embedding for the given source code. Experimental results demonstrate that ReGVD outperforms the existing state-of-the-art models and obtain the highest accuracy on the real-world benchmark dataset from CodeXGLUE for vulnerability detection.