 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022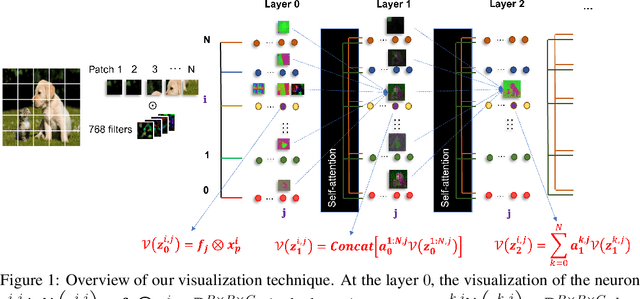
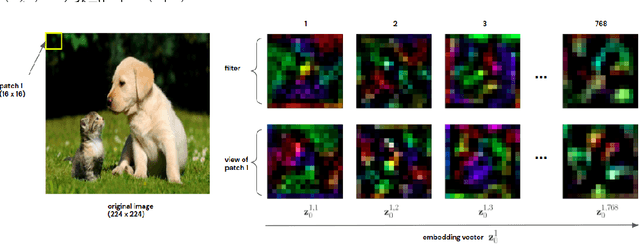


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization