 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025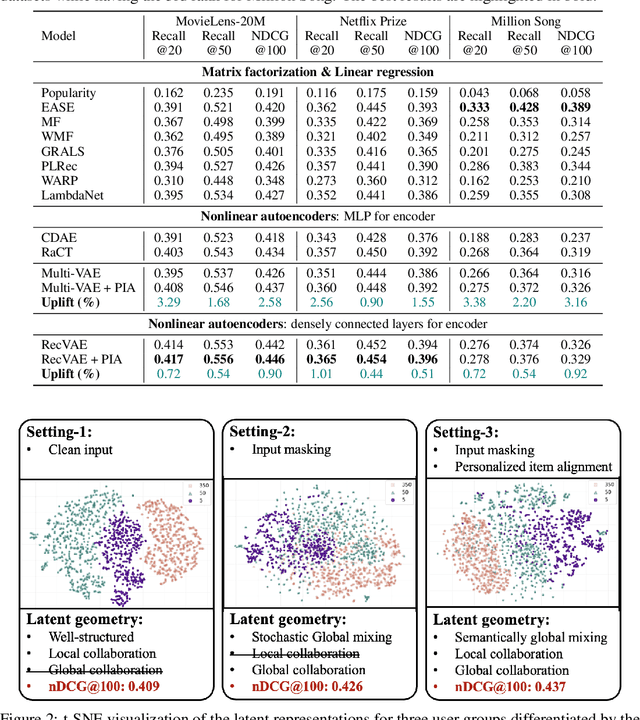
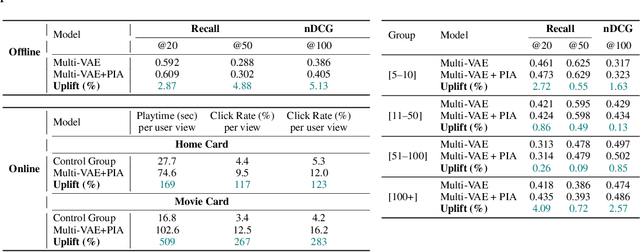

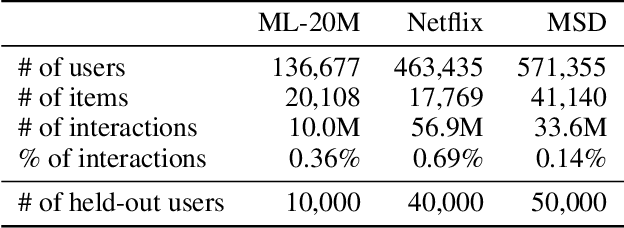
Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
Preserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
Task-Driven Discrete Representation Learning
Jun 13, 2025In recent years, deep discrete representation learning (DRL) has achieved significant success across various domains. Most DRL frameworks (e.g., the widely used VQ-VAE and its variants) have primarily focused on generative settings, where the quality of a representation is implicitly gauged by the fidelity of its generation. In fact, the goodness of a discrete representation remain ambiguously defined across the literature. In this work, we adopt a practical approach that examines DRL from a task-driven perspective. We propose a unified framework that explores the usefulness of discrete features in relation to downstream tasks, with generation naturally viewed as one possible application. In this context, the properties of discrete representations as well as the way they benefit certain tasks are also relatively understudied. We therefore provide an additional theoretical analysis of the trade-off between representational capacity and sample complexity, shedding light on how discrete representation utilization impacts task performance. Finally, we demonstrate the flexibility and effectiveness of our framework across diverse applications.
Vector Quantized Wasserstein Auto-Encoder
Feb 12, 2023Learning deep discrete latent presentations offers a promise of better symbolic and summarized abstractions that are more useful to subsequent downstream tasks. Inspired by the seminal Vector Quantized Variational Auto-Encoder (VQ-VAE), most of work in learning deep discrete representations has mainly focused on improving the original VQ-VAE form and none of them has studied learning deep discrete representations from the generative viewpoint. In this work, we study learning deep discrete representations from the generative viewpoint. Specifically, we endow discrete distributions over sequences of codewords and learn a deterministic decoder that transports the distribution over the sequences of codewords to the data distribution via minimizing a WS distance between them. We develop further theories to connect it with the clustering viewpoint of WS distance, allowing us to have a better and more controllable clustering solution. Finally, we empirically evaluate our method on several well-known benchmarks, where it achieves better qualitative and quantitative performances than the other VQ-VAE variants in terms of the codebook utilization and image reconstruction/generation.
Flat Seeking Bayesian Neural Networks
Feb 09, 2023Bayesian Neural Networks (BNNs) offer a probabilistic interpretation for deep learning models by imposing a prior distribution over model parameters and inferencing a posterior distribution based on observed data. The model sampled from the posterior distribution can be used for providing ensemble predictions and quantifying prediction uncertainty. It is well-known that deep learning models with a lower sharpness have a better generalization ability. Nonetheless, existing posterior inferences are not aware of sharpness/flatness, hence possibly leading to high sharpness for the models sampled from it. In this paper, we develop theories, the Bayesian setting, and the variational inference approach for the sharpness-aware posterior. Specifically, the models sampled from our sharpness-aware posterior and the optimal approximate posterior estimating this sharpness-aware posterior have a better flatness, hence possibly possessing a higher generalization ability. We conduct experiments by leveraging the sharpness-aware posterior with the state-of-the-art Bayesian Neural Networks, showing that the flat-seeking counterparts outperform their baselines in all metrics of interest.
Uncertainty-aware Model-based Policy Optimization
Jun 25, 2019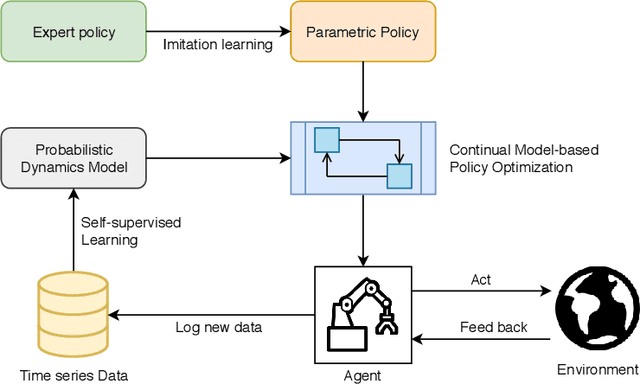

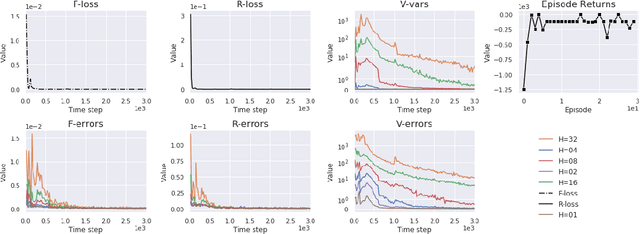
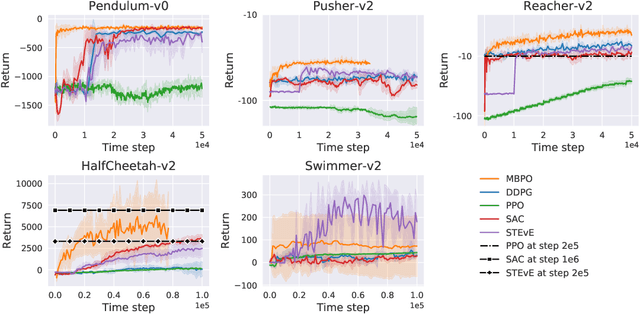
Model-based reinforcement learning has the potential to be more sample efficient than model-free approaches. However, existing model-based methods are vulnerable to model bias, which leads to poor generalization and asymptotic performance compared to model-free counterparts. In addition, they are typically based on the model predictive control (MPC) framework, which not only is computationally inefficient at decision time but also does not enable policy transfer due to the lack of an explicit policy representation. In this paper, we propose a novel uncertainty-aware model-based policy optimization framework which solves those issues. In this framework, the agent simultaneously learns an uncertainty-aware dynamics model and optimizes the policy according to these learned models. In the optimization step, the policy gradient is computed by automatic differentiation through the models. With respect to sample efficiency alone, our approach shows promising results on challenging continuous control benchmarks with competitive asymptotic performance and significantly lower sample complexity than state-of-the-art baselines.