 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Model-based Policy Optimization
Paper and Code
Jun 25, 2019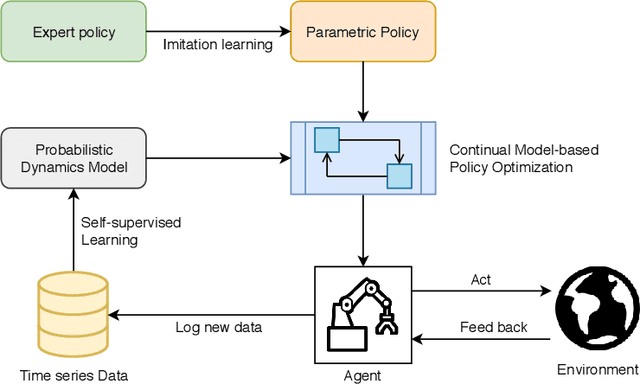

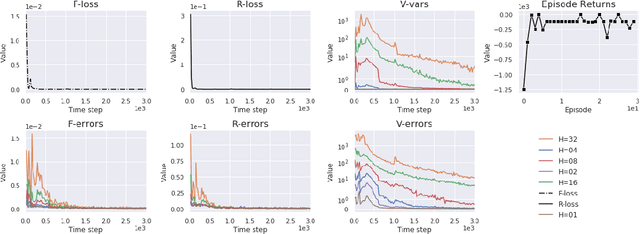
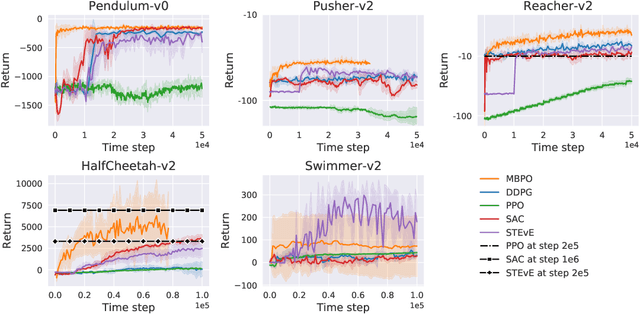
Model-based reinforcement learning has the potential to be more sample efficient than model-free approaches. However, existing model-based methods are vulnerable to model bias, which leads to poor generalization and asymptotic performance compared to model-free counterparts. In addition, they are typically based on the model predictive control (MPC) framework, which not only is computationally inefficient at decision time but also does not enable policy transfer due to the lack of an explicit policy representation. In this paper, we propose a novel uncertainty-aware model-based policy optimization framework which solves those issues. In this framework, the agent simultaneously learns an uncertainty-aware dynamics model and optimizes the policy according to these learned models. In the optimization step, the policy gradient is computed by automatic differentiation through the models. With respect to sample efficiency alone, our approach shows promising results on challenging continuous control benchmarks with competitive asymptotic performance and significantly lower sample complexity than state-of-the-art baselines.