 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Physics-based Greenhouse Simulation
Nov 21, 2022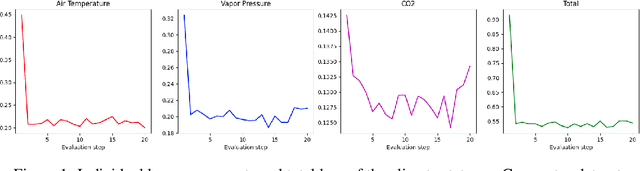
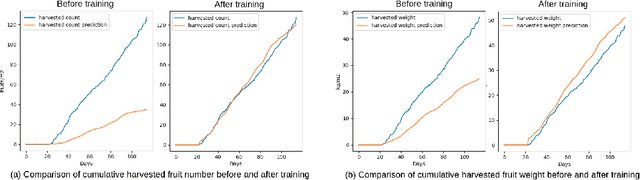
We present a differentiable greenhouse simulation model based on physical processes whose parameters can be obtained by training from real data. The physics-based simulation model is fully interpretable and is able to do state prediction for both climate and crop dynamics in the greenhouse over very a long time horizon. The model works by constructing a system of linear differential equations and solving them to obtain the next state. We propose a procedure to solve the differential equations, handle the problem of missing unobservable states in the data, and train the model efficiently. Our experiment shows the procedure is effective. The model improves significantly after training and can simulate a greenhouse that grows cucumbers accurately.
Uncertainty-aware Model-based Policy Optimization
Jun 25, 2019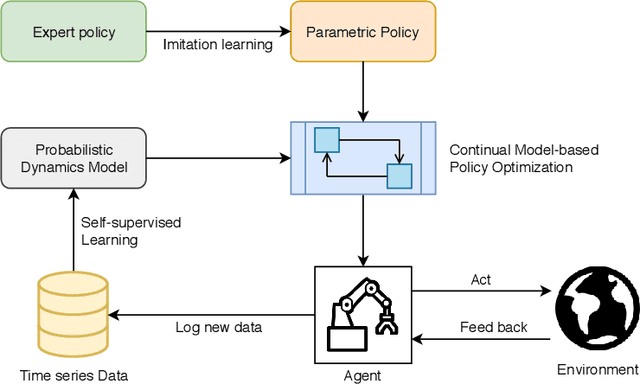

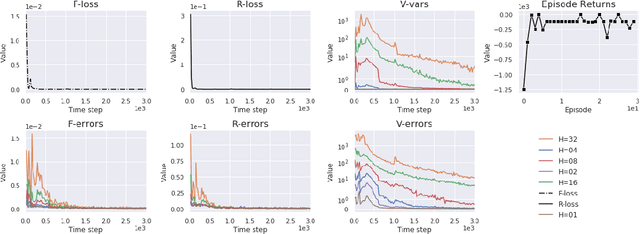
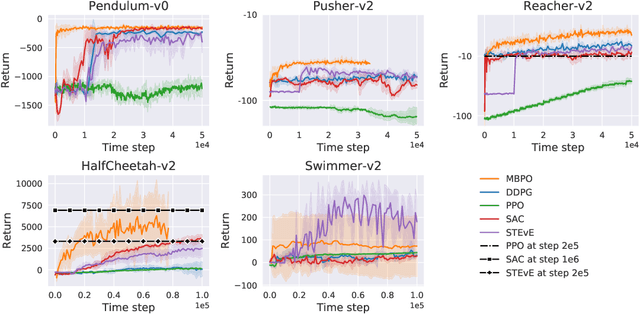
Model-based reinforcement learning has the potential to be more sample efficient than model-free approaches. However, existing model-based methods are vulnerable to model bias, which leads to poor generalization and asymptotic performance compared to model-free counterparts. In addition, they are typically based on the model predictive control (MPC) framework, which not only is computationally inefficient at decision time but also does not enable policy transfer due to the lack of an explicit policy representation. In this paper, we propose a novel uncertainty-aware model-based policy optimization framework which solves those issues. In this framework, the agent simultaneously learns an uncertainty-aware dynamics model and optimizes the policy according to these learned models. In the optimization step, the policy gradient is computed by automatic differentiation through the models. With respect to sample efficiency alone, our approach shows promising results on challenging continuous control benchmarks with competitive asymptotic performance and significantly lower sample complexity than state-of-the-art baselines.
Bias Correction of Learned Generative Models using Likelihood-Free Importance Weighting
Jun 23, 2019

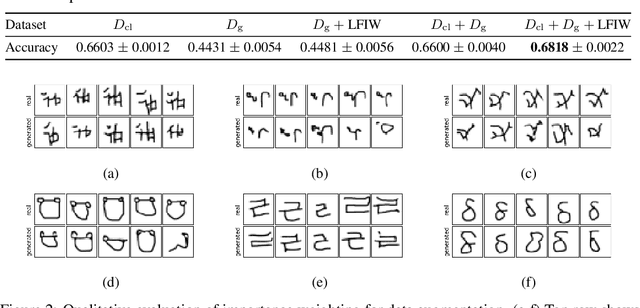

A learned generative model often produces biased statistics relative to the underlying data distribution. A standard technique to correct this bias is importance sampling, where samples from the model are weighted by the likelihood ratio under model and true distributions. When the likelihood ratio is unknown, it can be estimated by training a probabilistic classifier to distinguish samples from the two distributions. In this paper, we employ this likelihood-free importance weighting framework to correct for the bias in state-of-the-art deep generative models. We find that this technique consistently improves standard goodness-of-fit metrics for evaluating the sample quality of state-of-the-art generative models, suggesting reduced bias. Finally, we demonstrate its utility on representative applications in a) data augmentation for classification using generative adversarial networks, and b) model-based policy evaluation using off-policy data.
Semantic Compositional Networks for Visual Captioning
Mar 28, 2017
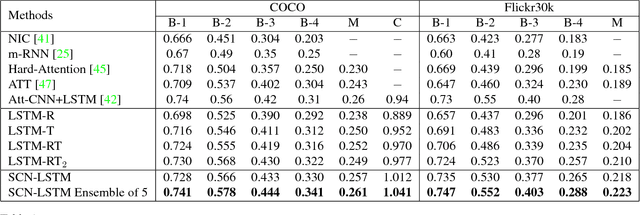


A Semantic Compositional Network (SCN) is developed for image captioning, in which semantic concepts (i.e., tags) are detected from the image, and the probability of each tag is used to compose the parameters in a long short-term memory (LSTM) network. The SCN extends each weight matrix of the LSTM to an ensemble of tag-dependent weight matrices. The degree to which each member of the ensemble is used to generate an image caption is tied to the image-dependent probability of the corresponding tag. In addition to captioning images, we also extend the SCN to generate captions for video clips. We qualitatively analyze semantic composition in SCNs, and quantitatively evaluate the algorithm on three benchmark datasets: COCO, Flickr30k, and Youtube2Text. Experimental results show that the proposed method significantly outperforms prior state-of-the-art approaches, across multiple evaluation metrics.
Rich Image Captioning in the Wild
Mar 31, 2016
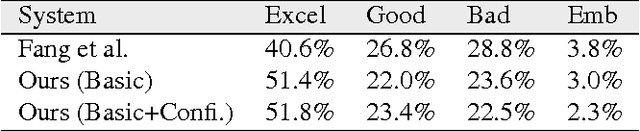
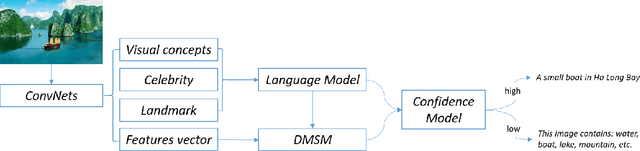
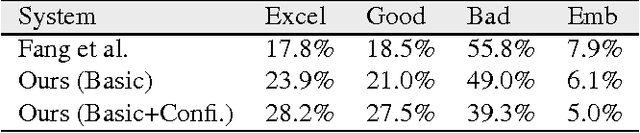
We present an image caption system that addresses new challenges of automatically describing images in the wild. The challenges include high quality caption quality with respect to human judgments, out-of-domain data handling, and low latency required in many applications. Built on top of a state-of-the-art framework, we developed a deep vision model that detects a broad range of visual concepts, an entity recognition model that identifies celebrities and landmarks, and a confidence model for the caption output. Experimental results show that our caption engine outperforms previous state-of-the-art systems significantly on both in-domain dataset (i.e. MS COCO) and out of-domain datasets.