 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025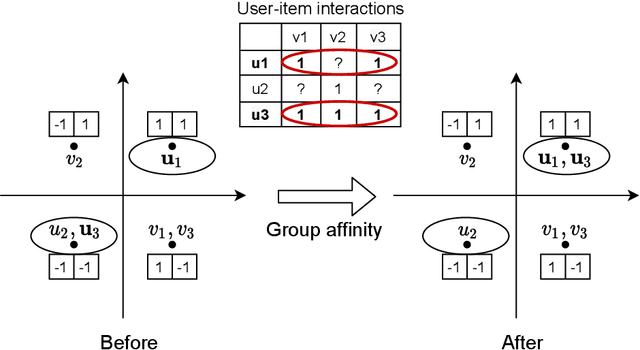

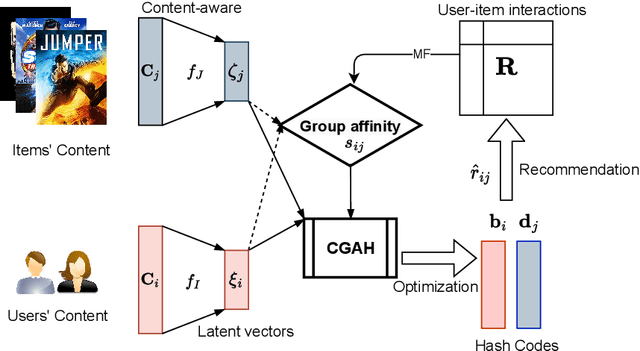
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
Discrete Scale-invariant Metric Learning for Efficient Collaborative Filtering
Jun 11, 2025Metric learning has attracted extensive interest for its ability to provide personalized recommendations based on the importance of observed user-item interactions. Current metric learning methods aim to push negative items away from the corresponding users and positive items by an absolute geometrical distance margin. However, items may come from imbalanced categories with different intra-class variations. Thus, the absolute distance margin may not be ideal for estimating the difference between user preferences over imbalanced items. To this end, we propose a new method, named discrete scale-invariant metric learning (DSIML), by adding binary constraints to users and items, which maps users and items into binary codes of a shared Hamming subspace to speed up the online recommendation. Specifically, we firstly propose a scale-invariant margin based on angles at the negative item points in the shared Hamming subspace. Then, we derive a scale-invariant triple hinge loss based on the margin. To capture more preference difference information, we integrate a pairwise ranking loss into the scale-invariant loss in the proposed model. Due to the difficulty of directly optimizing the mixed integer optimization problem formulated with \textit{log-sum-exp} functions, we seek to optimize its variational quadratic upper bound and learn hash codes with an alternating optimization strategy. Experiments on benchmark datasets clearly show that our proposed method is superior to competitive metric learning and hashing-based baselines for recommender systems. The implementation code is available at https://github.com/AnonyFeb/dsml.
Trusting Language Models in Education
Aug 07, 2023
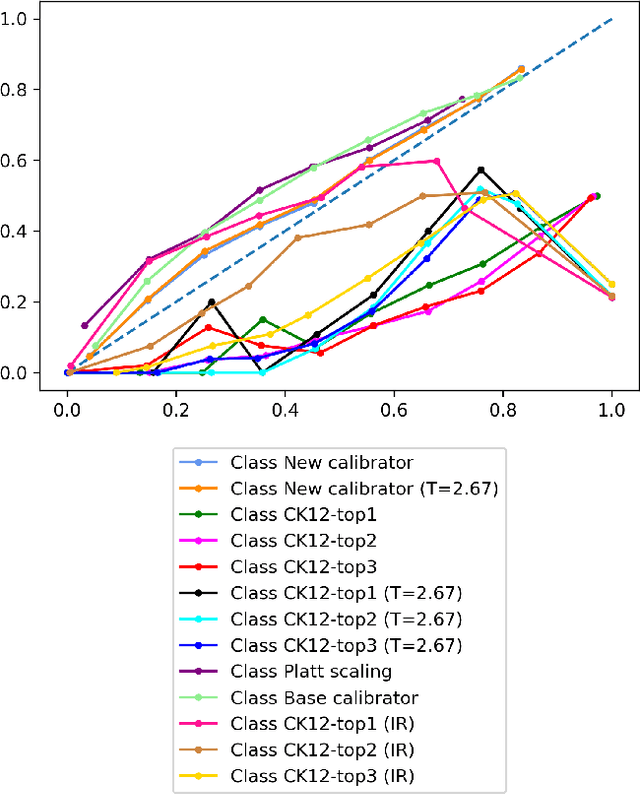
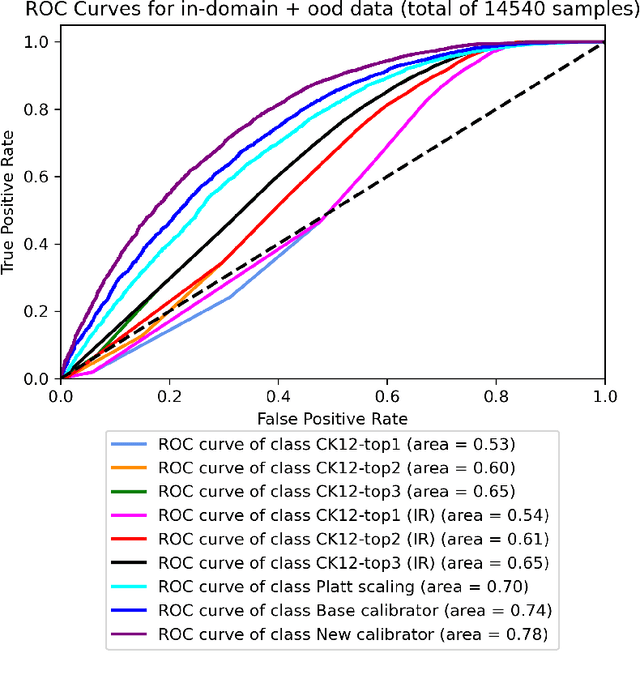
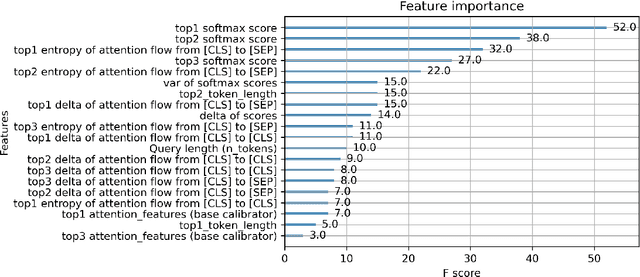
Language Models are being widely used in Education. Even though modern deep learning models achieve very good performance on question-answering tasks, sometimes they make errors. To avoid misleading students by showing wrong answers, it is important to calibrate the confidence - that is, the prediction probability - of these models. In our work, we propose to use an XGBoost on top of BERT to output the corrected probabilities, using features based on the attention mechanism. Our hypothesis is that the level of uncertainty contained in the flow of attention is related to the quality of the model's response itself.
OSLAT: Open Set Label Attention Transformer for Medical Entity Span Extraction
Jul 12, 2022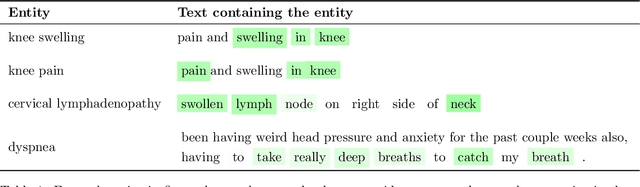
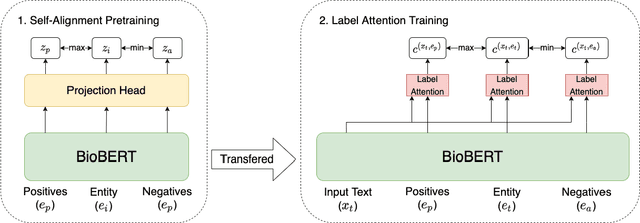

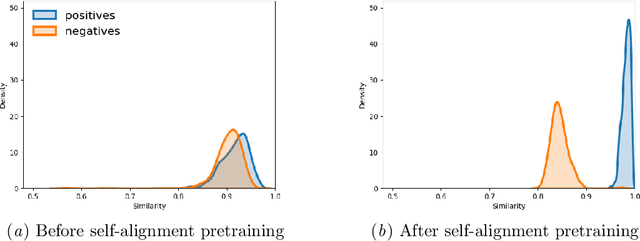
Identifying spans in medical texts that correspond to medical entities is one of the core steps for many healthcare NLP tasks such as ICD coding, medical finding extraction, medical note contextualization, to name a few. Existing entity extraction methods rely on a fixed and limited vocabulary of medical entities and have difficulty with extracting entities represented by disjoint spans. In this paper, we present a new transformer-based architecture called OSLAT, Open Set Label Attention Transformer, that addresses many of the limitations of the previous methods. Our approach uses the label-attention mechanism to implicitly learn spans associated with entities of interest. These entities can be provided as free text, including entities not seen during OSLAT's training, and the model can extract spans even when they are disjoint. To test the generalizability of our method, we train two separate models on two different datasets, which have very low entity overlap: (1) a public discharge notes dataset from hNLP, and (2) a much more challenging proprietary patient text dataset "Reasons for Encounter" (RFE). We find that OSLAT models trained on either dataset outperform rule-based and fuzzy string matching baselines when applied to the RFE dataset as well as to the portion of hNLP dataset where entities are represented by disjoint spans. Our code can be found at https://github.com/curai/curai-research/tree/main/OSLAT.
MEDCOD: A Medically-Accurate, Emotive, Diverse, and Controllable Dialog System
Nov 17, 2021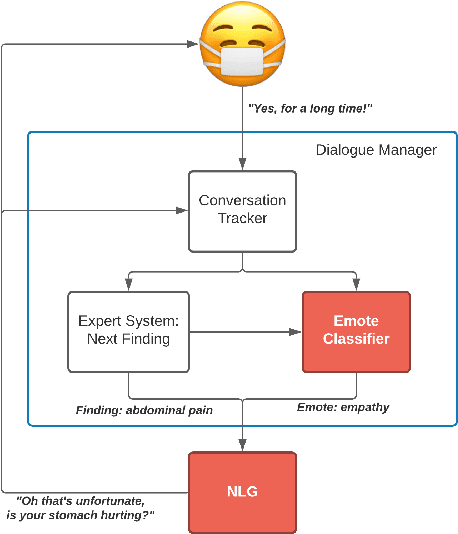



We present MEDCOD, a Medically-Accurate, Emotive, Diverse, and Controllable Dialog system with a unique approach to the natural language generator module. MEDCOD has been developed and evaluated specifically for the history taking task. It integrates the advantage of a traditional modular approach to incorporate (medical) domain knowledge with modern deep learning techniques to generate flexible, human-like natural language expressions. Two key aspects of MEDCOD's natural language output are described in detail. First, the generated sentences are emotive and empathetic, similar to how a doctor would communicate to the patient. Second, the generated sentence structures and phrasings are varied and diverse while maintaining medical consistency with the desired medical concept (provided by the dialogue manager module of MEDCOD). Experimental results demonstrate the effectiveness of our approach in creating a human-like medical dialogue system. Relevant code is available at https://github.com/curai/curai-research/tree/main/MEDCOD
Multimodal Intelligence: Representation Learning, Information Fusion, and Applications
Nov 10, 2019Deep learning has revolutionized speech recognition, image recognition, and natural language processing since 2010, each involving a single modality in the input signal. However, many applications in artificial intelligence involve more than one modality. It is therefore of broad interest to study the more difficult and complex problem of modeling and learning across multiple modalities. In this paper, a technical review of the models and learning methods for multimodal intelligence is provided. The main focus is the combination of vision and natural language, which has become an important area in both computer vision and natural language processing research communities. This review provides a comprehensive analysis of recent work on multimodal deep learning from three new angles - learning multimodal representations, the fusion of multimodal signals at various levels, and multimodal applications. On multimodal representation learning, we review the key concept of embedding, which unifies the multimodal signals into the same vector space and thus enables cross-modality signal processing. We also review the properties of the many types of embedding constructed and learned for general downstream tasks. On multimodal fusion, this review focuses on special architectures for the integration of the representation of unimodal signals for a particular task. On applications, selected areas of a broad interest in current literature are covered, including caption generation, text-to-image generation, and visual question answering. We believe this review can facilitate future studies in the emerging field of multimodal intelligence for the community.
From Caesar Cipher to Unsupervised Learning: A New Method for Classifier Parameter Estimation
Jun 06, 2019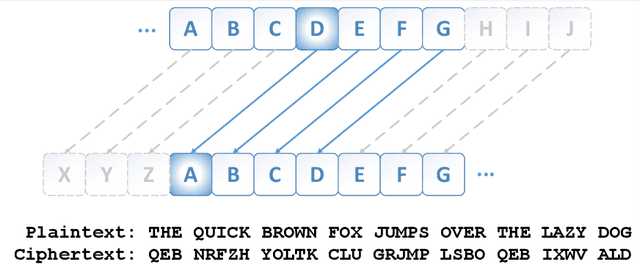

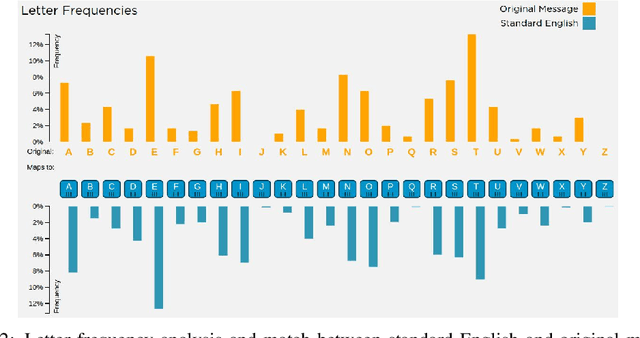
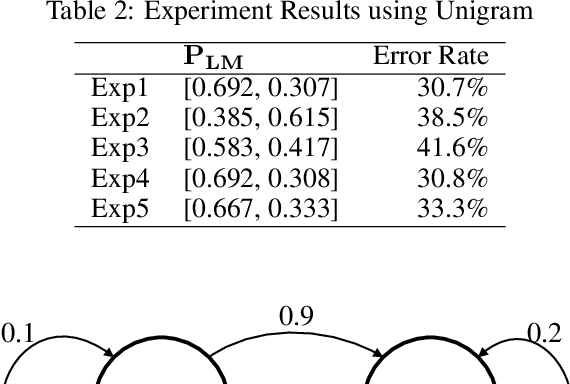
Many important classification problems, such as object classification, speech recognition, and machine translation, have been tackled by the supervised learning paradigm in the past, where training corpora of parallel input-output pairs are required with high cost. To remove the need for the parallel training corpora has practical significance for real-world applications, and it is one of the main goals of unsupervised learning. Recently, encouraging progress in unsupervised learning for solving such classification problems has been made and the nature of the challenges has been clarified. In this article, we review this progress and disseminate a class of promising new methods to facilitate understanding the methods for machine learning researchers. In particular, we emphasize the key information that enables the success of unsupervised learning - the sequential statistics as the distributional prior in the labels. Exploitation of such sequential statistics makes it possible to estimate parameters of classifiers without the need of paired input-output data. In this paper, we first introduce the concept of Caesar Cipher and its decryption, which motivated the construction of the novel loss function for unsupervised learning we use throughout the paper. Then we use a simple but representative binary classification task as an example to derive and describe the unsupervised learning algorithm in a step-by-step, easy-to-understand fashion. We include two cases, one with Bigram language model as the sequential statistics for use in unsupervised parameter estimation, and another with a simpler Unigram language model. For both cases, detailed derivation steps for the learning algorithm are included. Further, a summary table compares computational steps of the two cases in executing the unsupervised learning algorithm for learning binary classifiers.
Table2Vec: Neural Word and Entity Embeddings for Table Population and Retrieval
May 31, 2019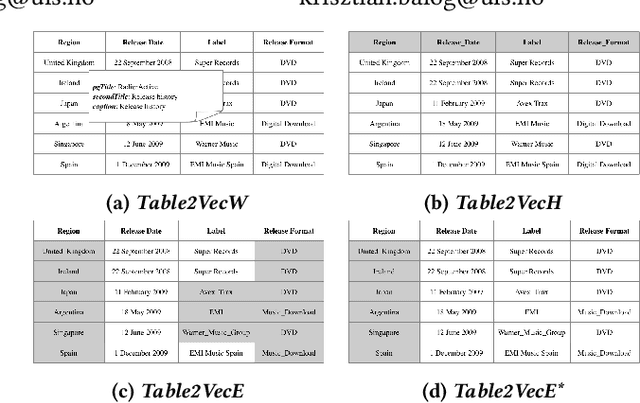



Tables contain valuable knowledge in a structured form. We employ neural language modeling approaches to embed tabular data into vector spaces. Specifically, we consider different table elements, such caption, column headings, and cells, for training word and entity embeddings. These embeddings are then utilized in three particular table-related tasks, row population, column population, and table retrieval, by incorporating them into existing retrieval models as additional semantic similarity signals. Evaluation results show that table embeddings can significantly improve upon the performance of state-of-the-art baselines.
Attentive Tensor Product Learning
Nov 01, 2018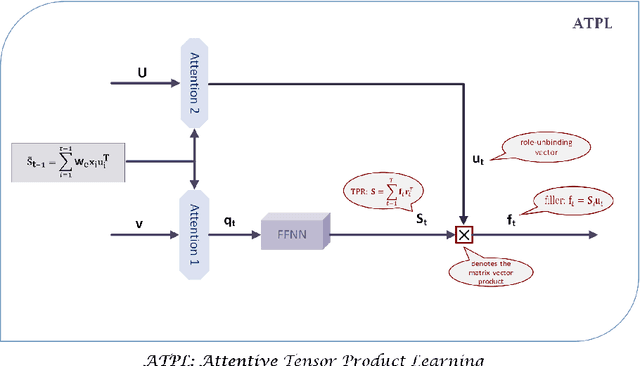



This paper proposes a new architecture - Attentive Tensor Product Learning (ATPL) - to represent grammatical structures in deep learning models. ATPL is a new architecture to bridge this gap by exploiting Tensor Product Representations (TPR), a structured neural-symbolic model developed in cognitive science, aiming to integrate deep learning with explicit language structures and rules. The key ideas of ATPL are: 1) unsupervised learning of role-unbinding vectors of words via TPR-based deep neural network; 2) employing attention modules to compute TPR; and 3) integration of TPR with typical deep learning architectures including Long Short-Term Memory (LSTM) and Feedforward Neural Network (FFNN). The novelty of our approach lies in its ability to extract the grammatical structure of a sentence by using role-unbinding vectors, which are obtained in an unsupervised manner. This ATPL approach is applied to 1) image captioning, 2) part of speech (POS) tagging, and 3) constituency parsing of a sentence. Experimental results demonstrate the effectiveness of the proposed approach.
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Oct 31, 2018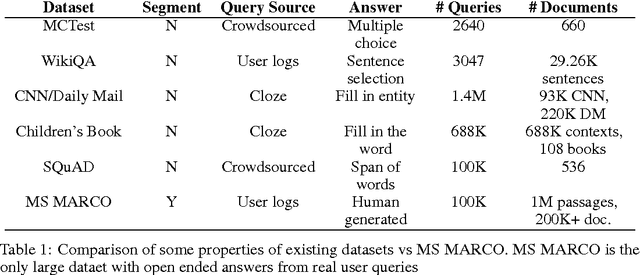
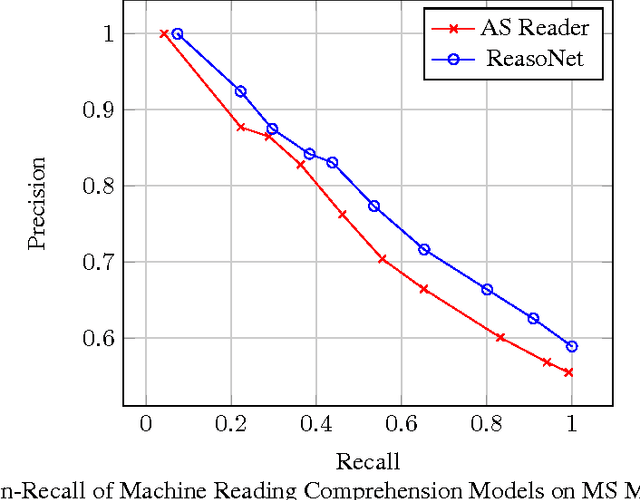

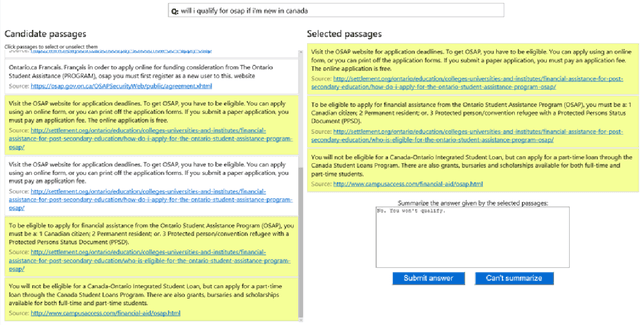
We introduce a large scale MAchine Reading COmprehension dataset, which we name MS MARCO. The dataset comprises of 1,010,916 anonymized questions---sampled from Bing's search query logs---each with a human generated answer and 182,669 completely human rewritten generated answers. In addition, the dataset contains 8,841,823 passages---extracted from 3,563,535 web documents retrieved by Bing---that provide the information necessary for curating the natural language answers. A question in the MS MARCO dataset may have multiple answers or no answers at all. Using this dataset, we propose three different tasks with varying levels of difficulty: (i) predict if a question is answerable given a set of context passages, and extract and synthesize the answer as a human would (ii) generate a well-formed answer (if possible) based on the context passages that can be understood with the question and passage context, and finally (iii) rank a set of retrieved passages given a question. The size of the dataset and the fact that the questions are derived from real user search queries distinguishes MS MARCO from other well-known publicly available datasets for machine reading comprehension and question-answering. We believe that the scale and the real-world nature of this dataset makes it attractive for benchmarking machine reading comprehension and question-answering models.