 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGym: A Framework for A/B Test Simulation in E-Commerce with Traffic-Grounded VLM Agents
May 19, 2026A/B testing remains the gold standard for evaluating modifications to e-commerce storefronts, yet it diverts traffic, requires weeks to reach statistical significance, and risks degrading user experience. We present SimGym, a framework for simulating A/B tests on e-commerce storefronts using vision-language model (VLM) agents operating in a live browser. The framework comprises three key components: (a) a traffic-grounded persona generation pipeline that derives per-shop buyer archetypes and intents from production clickstream data; (b) a live-browser agent architecture that combines multimodal perception over visual and browser-structured observations with episodic memory and guardrails to conduct coherent shopping sessions across control and treatment storefronts; and (c) an evaluation protocol that compares simulated outcome shifts with observed shifts in real buyer behavior. We validate SimGym on A/B tests of visually driven UI theme changes from a major e-commerce platform across diverse storefronts and product categories. Empirical results show that SimGym agents achieve strong agreement with observed outcome shifts, attaining 77% directional alignment with add-to-cart shifts observed across interface variants in real-buyer traffic. It reduces experimental cycles from weeks to under an hour, enabling rapid experimentation without exposing real buyers to candidate variants.
SimGym: Traffic-Grounded Browser Agents for Offline A/B Testing in E-Commerce
Feb 01, 2026A/B testing remains the gold standard for evaluating e-commerce UI changes, yet it diverts traffic, takes weeks to reach significance, and risks harming user experience. We introduce SimGym, a scalable system for rapid offline A/B testing using traffic-grounded synthetic buyers powered by Large Language Model agents operating in a live browser. SimGym extracts per-shop buyer profiles and intents from production interaction data, identifies distinct behavioral archetypes, and simulates cohort-weighted sessions across control and treatment storefronts. We validate SimGym against real human outcomes from real UI changes on a major e-commerce platform under confounder control. Even without alignment post training, SimGym agents achieve state of the art alignment with observed outcome shifts and reduces experiment cycles from weeks to under an hour , enabling rapid experimentation without exposure to real buyers.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Improving Neural Question Generation using World Knowledge
Sep 10, 2019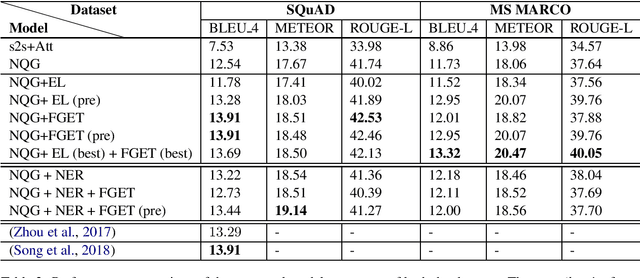
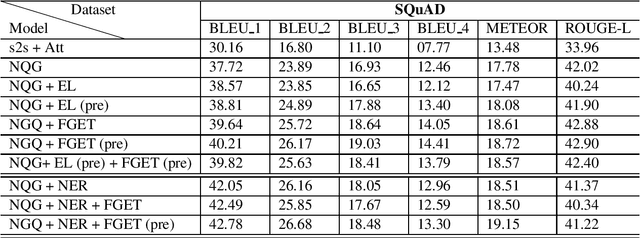
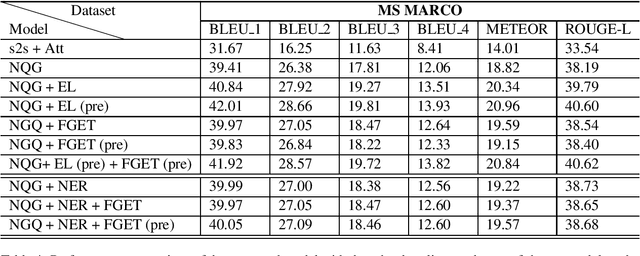
In this paper, we propose a method for incorporating world knowledge (linked entities and fine-grained entity types) into a neural question generation model. This world knowledge helps to encode additional information related to the entities present in the passage required to generate human-like questions. We evaluate our models on both SQuAD and MS MARCO to demonstrate the usefulness of the world knowledge features. The proposed world knowledge enriched question generation model is able to outperform the vanilla neural question generation model by 1.37 and 1.59 absolute BLEU 4 score on SQuAD and MS MARCO test dataset respectively.
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Oct 31, 2018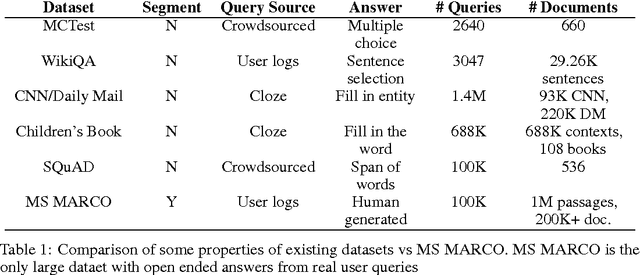
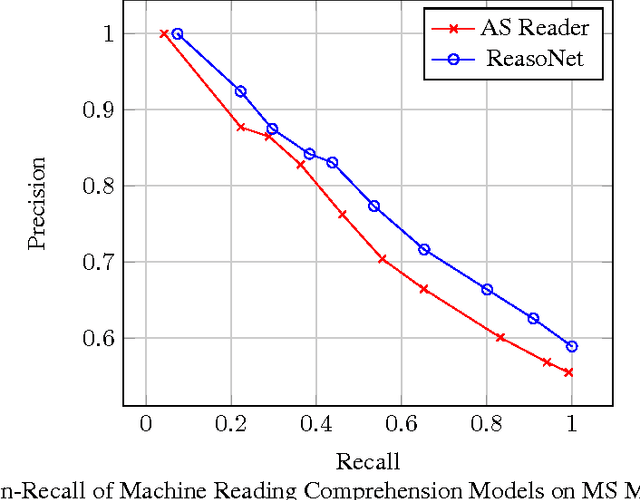

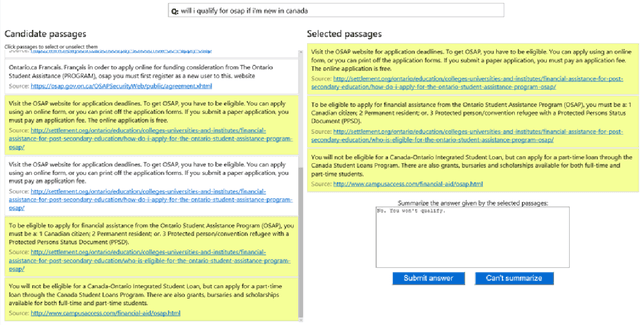
We introduce a large scale MAchine Reading COmprehension dataset, which we name MS MARCO. The dataset comprises of 1,010,916 anonymized questions---sampled from Bing's search query logs---each with a human generated answer and 182,669 completely human rewritten generated answers. In addition, the dataset contains 8,841,823 passages---extracted from 3,563,535 web documents retrieved by Bing---that provide the information necessary for curating the natural language answers. A question in the MS MARCO dataset may have multiple answers or no answers at all. Using this dataset, we propose three different tasks with varying levels of difficulty: (i) predict if a question is answerable given a set of context passages, and extract and synthesize the answer as a human would (ii) generate a well-formed answer (if possible) based on the context passages that can be understood with the question and passage context, and finally (iii) rank a set of retrieved passages given a question. The size of the dataset and the fact that the questions are derived from real user search queries distinguishes MS MARCO from other well-known publicly available datasets for machine reading comprehension and question-answering. We believe that the scale and the real-world nature of this dataset makes it attractive for benchmarking machine reading comprehension and question-answering models.