 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Translate First Reorder Later: Leveraging Monotonicity in Semantic Parsing
Oct 10, 2022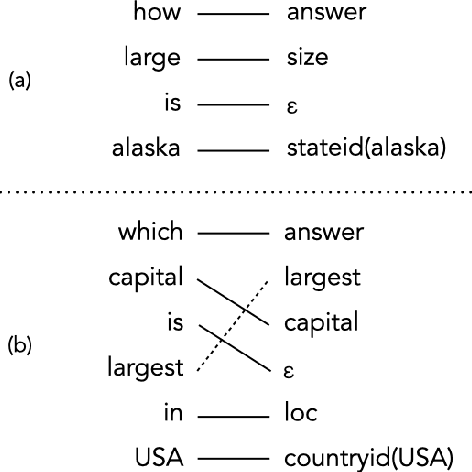
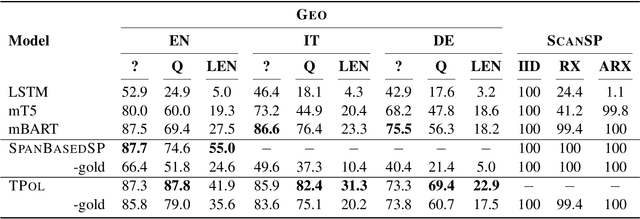

Prior work in semantic parsing has shown that conventional seq2seq models fail at compositional generalization tasks. This limitation led to a resurgence of methods that model alignments between sentences and their corresponding meaning representations, either implicitly through latent variables or explicitly by taking advantage of alignment annotations. We take the second direction and propose TPol, a two-step approach that first translates input sentences monotonically and then reorders them to obtain the correct output. This is achieved with a modular framework comprising a Translator and a Reorderer component. We test our approach on two popular semantic parsing datasets. Our experiments show that by means of the monotonic translations, TPol can learn reliable lexico-logical patterns from aligned data, significantly improving compositional generalization both over conventional seq2seq models, as well as over a recently proposed approach that exploits gold alignments.
Measuring Alignment Bias in Neural Seq2Seq Semantic Parsers
May 17, 2022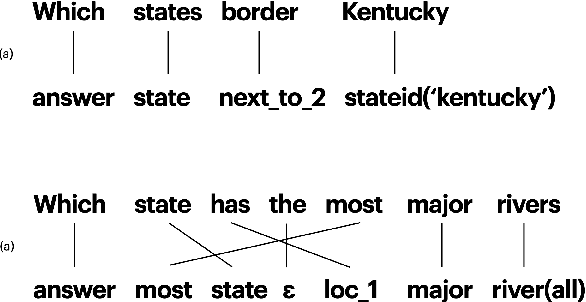
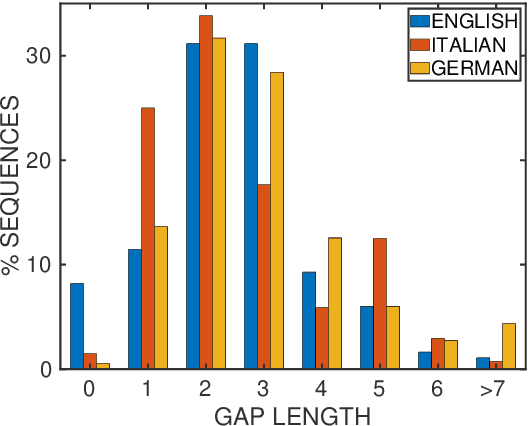
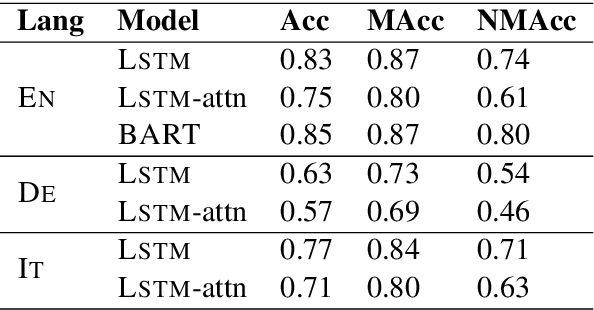
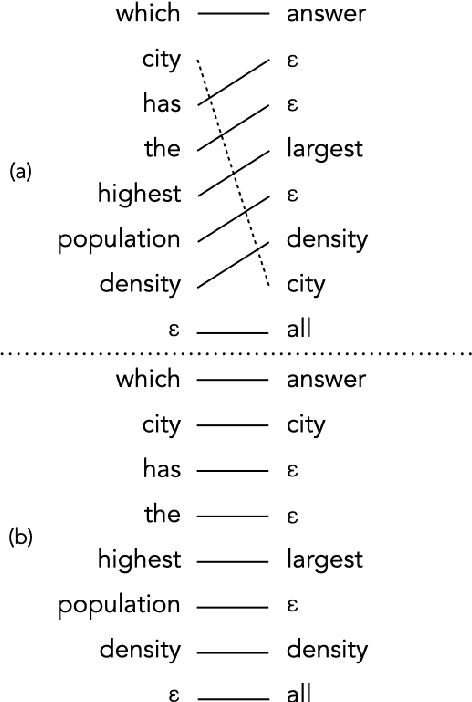
Prior to deep learning the semantic parsing community has been interested in understanding and modeling the range of possible word alignments between natural language sentences and their corresponding meaning representations. Sequence-to-sequence models changed the research landscape suggesting that we no longer need to worry about alignments since they can be learned automatically by means of an attention mechanism. More recently, researchers have started to question such premise. In this work we investigate whether seq2seq models can handle both simple and complex alignments. To answer this question we augment the popular Geo semantic parsing dataset with alignment annotations and create Geo-Aligned. We then study the performance of standard seq2seq models on the examples that can be aligned monotonically versus examples that require more complex alignments. Our empirical study shows that performance is significantly better over monotonic alignments.