 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Deep Sequence Classifiers Good at Non-Trivial Generalization?
Oct 24, 2022Recent advances in deep learning models for sequence classification have greatly improved their classification accuracy, specially when large training sets are available. However, several works have suggested that under some settings the predictions made by these models are poorly calibrated. In this work we study binary sequence classification problems and we look at model calibration from a different perspective by asking the question: Are deep learning models capable of learning the underlying target class distribution? We focus on sparse sequence classification, that is problems in which the target class is rare and compare three deep learning sequence classification models. We develop an evaluation that measures how well a classifier is learning the target class distribution. In addition, our evaluation disentangles good performance achieved by mere compression of the training sequences versus performance achieved by proper model generalization. Our results suggest that in this binary setting the deep-learning models are indeed able to learn the underlying class distribution in a non-trivial manner, i.e. by proper generalization beyond data compression.
Translate First Reorder Later: Leveraging Monotonicity in Semantic Parsing
Oct 10, 2022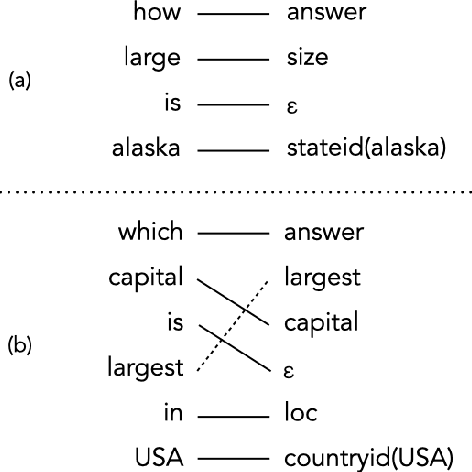
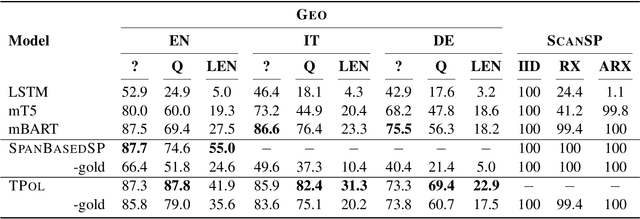
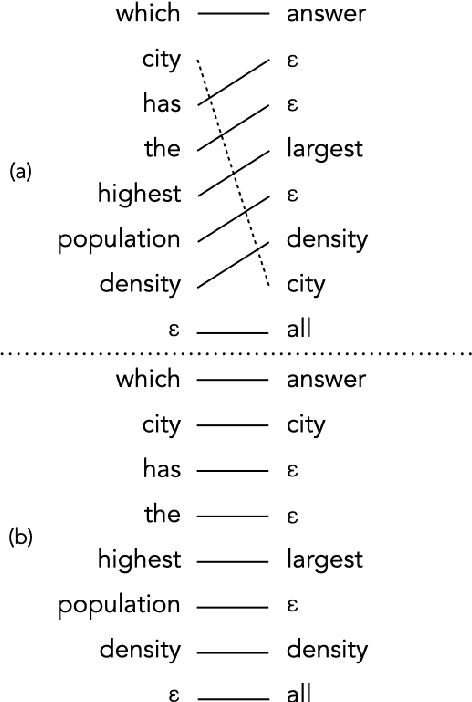

Prior work in semantic parsing has shown that conventional seq2seq models fail at compositional generalization tasks. This limitation led to a resurgence of methods that model alignments between sentences and their corresponding meaning representations, either implicitly through latent variables or explicitly by taking advantage of alignment annotations. We take the second direction and propose TPol, a two-step approach that first translates input sentences monotonically and then reorders them to obtain the correct output. This is achieved with a modular framework comprising a Translator and a Reorderer component. We test our approach on two popular semantic parsing datasets. Our experiments show that by means of the monotonic translations, TPol can learn reliable lexico-logical patterns from aligned data, significantly improving compositional generalization both over conventional seq2seq models, as well as over a recently proposed approach that exploits gold alignments.
A Maximum Matching Algorithm for Basis Selection in Spectral Learning
Jun 09, 2017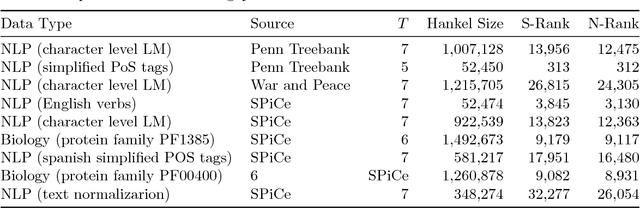
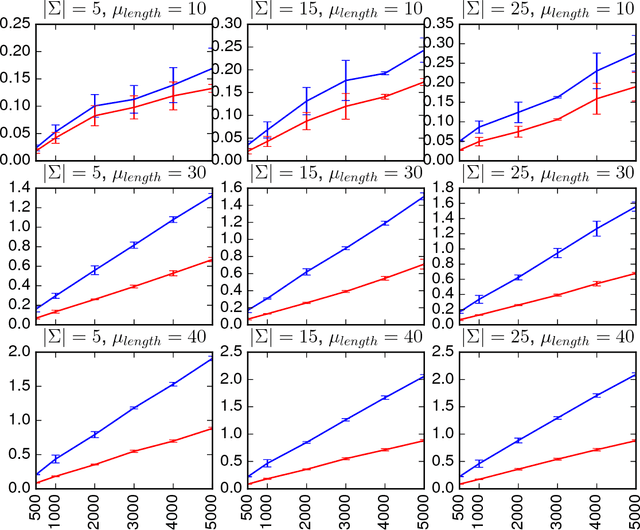
We present a solution to scale spectral algorithms for learning sequence functions. We are interested in the case where these functions are sparse (that is, for most sequences they return 0). Spectral algorithms reduce the learning problem to the task of computing an SVD decomposition over a special type of matrix called the Hankel matrix. This matrix is designed to capture the relevant statistics of the training sequences. What is crucial is that to capture long range dependencies we must consider very large Hankel matrices. Thus the computation of the SVD becomes a critical bottleneck. Our solution finds a subset of rows and columns of the Hankel that realizes a compact and informative Hankel submatrix. The novelty lies in the way that this subset is selected: we exploit a maximal bipartite matching combinatorial algorithm to look for a sub-block with full structural rank, and show how computation of this sub-block can be further improved by exploiting the specific structure of Hankel matrices.
Tailoring Word Embeddings for Bilexical Predictions: An Experimental Comparison
Apr 10, 2015


We investigate the problem of inducing word embeddings that are tailored for a particular bilexical relation. Our learning algorithm takes an existing lexical vector space and compresses it such that the resulting word embeddings are good predictors for a target bilexical relation. In experiments we show that task-specific embeddings can benefit both the quality and efficiency in lexical prediction tasks.
Local Loss Optimization in Operator Models: A New Insight into Spectral Learning
Jun 27, 2012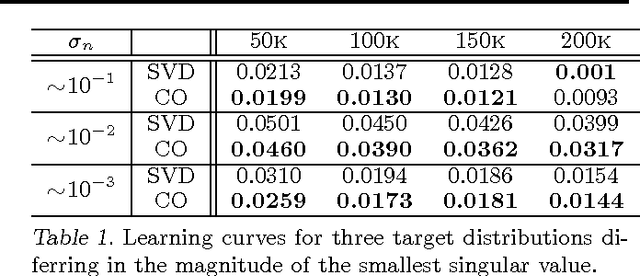
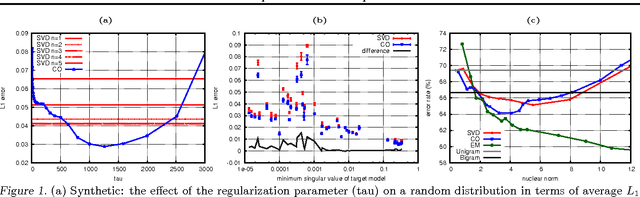
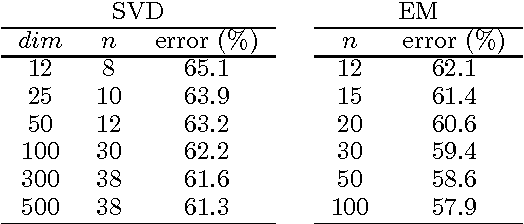
This paper re-visits the spectral method for learning latent variable models defined in terms of observable operators. We give a new perspective on the method, showing that operators can be recovered by minimizing a loss defined on a finite subset of the domain. A non-convex optimization similar to the spectral method is derived. We also propose a regularized convex relaxation of this optimization. We show that in practice the availabilty of a continuous regularization parameter (in contrast with the discrete number of states in the original method) allows a better trade-off between accuracy and model complexity. We also prove that in general, a randomized strategy for choosing the local loss will succeed with high probability.
Boosting Trees for Anti-Spam Email Filtering
Sep 13, 2001
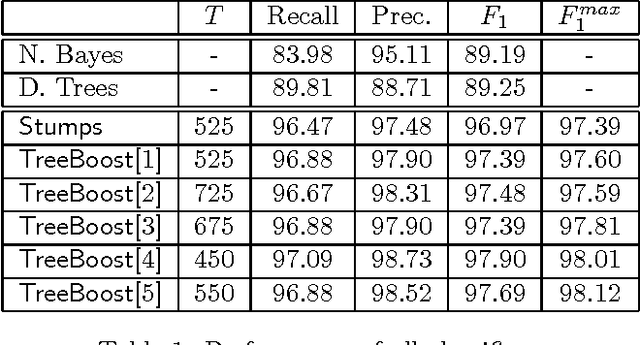
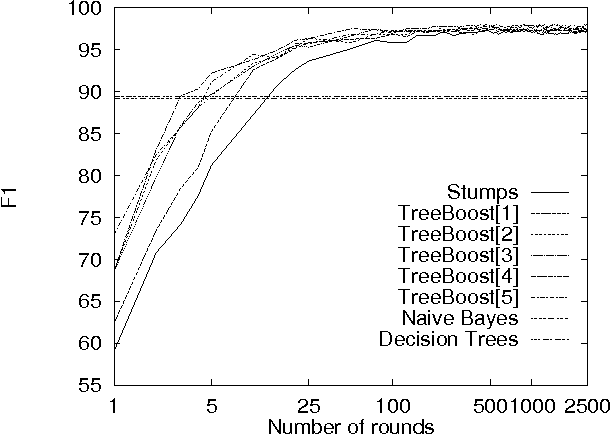
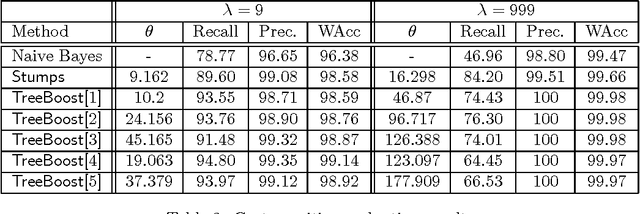
This paper describes a set of comparative experiments for the problem of automatically filtering unwanted electronic mail messages. Several variants of the AdaBoost algorithm with confidence-rated predictions [Schapire & Singer, 99] have been applied, which differ in the complexity of the base learners considered. Two main conclusions can be drawn from our experiments: a) The boosting-based methods clearly outperform the baseline learning algorithms (Naive Bayes and Induction of Decision Trees) on the PU1 corpus, achieving very high levels of the F1 measure; b) Increasing the complexity of the base learners allows to obtain better ``high-precision'' classifiers, which is a very important issue when misclassification costs are considered.
* 7 pages, 13 figures