 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Maximum Matching Algorithm for Basis Selection in Spectral Learning
Paper and Code
Jun 09, 2017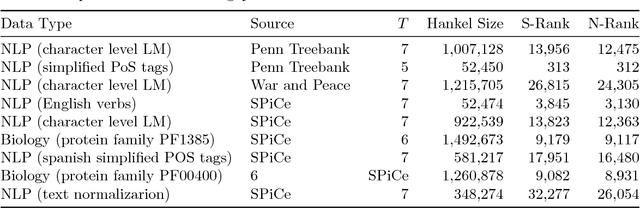
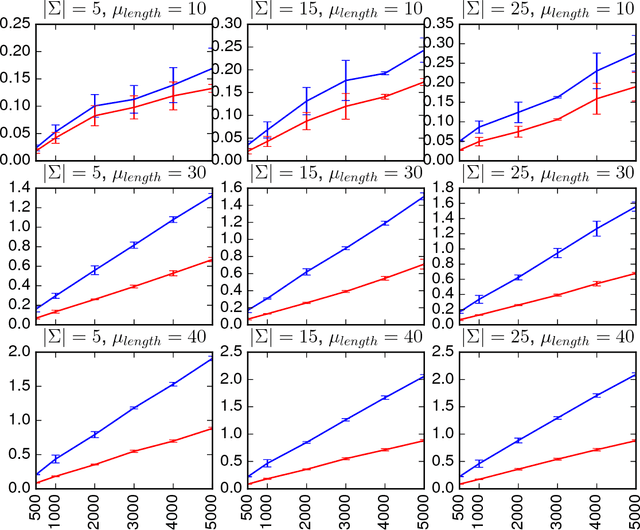
We present a solution to scale spectral algorithms for learning sequence functions. We are interested in the case where these functions are sparse (that is, for most sequences they return 0). Spectral algorithms reduce the learning problem to the task of computing an SVD decomposition over a special type of matrix called the Hankel matrix. This matrix is designed to capture the relevant statistics of the training sequences. What is crucial is that to capture long range dependencies we must consider very large Hankel matrices. Thus the computation of the SVD becomes a critical bottleneck. Our solution finds a subset of rows and columns of the Hankel that realizes a compact and informative Hankel submatrix. The novelty lies in the way that this subset is selected: we exploit a maximal bipartite matching combinatorial algorithm to look for a sub-block with full structural rank, and show how computation of this sub-block can be further improved by exploiting the specific structure of Hankel matrices.