 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Precise Text-To-Cypher Via Grounded Knowledge Graph Data Generation
Jun 12, 2026Property Graphs are rapidly being adopted as database frameworks for representing heterogeneous data sources. To enable precise access to the information contained in them we need conversational interfaces based on Text-To-Cypher (Text2Cypher) parsers. This paper presents an automatic synthetic data generation method that can be leveraged to fine-tune small LLMs for this task. We conduct experiments on all the major Text-To-Cypher benchmarks, demonstrating that with our synthetic data generation approach we can significantly increase the performance of small LLMs, allowing them to compete with much larger proprietary models. This means that in settings in which models must be locally deployed we can ensure data-sovereignty without sacrificing accuracy and without costly annotation campaigns.
Domain Pre-training Impact on Representations
May 30, 2025This empirical study analyzes the effects of the pre-training corpus on the quality of learned transformer representations. We focus on the representation quality induced solely through pre-training. Our experiments show that pre-training on a small, specialized corpus can yield effective representations, and that the success of combining a generic and a specialized corpus depends on the distributional similarity between the target task and the specialized corpus.
ZOGRASCOPE: A New Benchmark for Property Graphs
Mar 07, 2025



Natural language interfaces to knowledge graphs have become increasingly important in recent years, enabling easy and efficient access to structured data. In particular property graphs have seen growing adoption. However, these kind of graphs remain relatively underrepresented in research, which has focused in large part on RDF-style graphs. As a matter of fact there is a lack of resources for evaluating systems on property graphs, with many existing datasets featuring relatively simple queries. To address this gap, we introduce ZOGRASCOPE, a benchmark designed specifically for the cypher query language. The benchmark includes a diverse set of manually annotated queries of varying complexity. We complement this paper with a set of experiments that test the performance of out-of-the-box LLMs of different sizes. Our experiments show that semantic parsing over graphs is still a challenging open problem that can not be solved by prompting LLMs alone.
Analyzing Text Representations by Measuring Task Alignment
May 31, 2023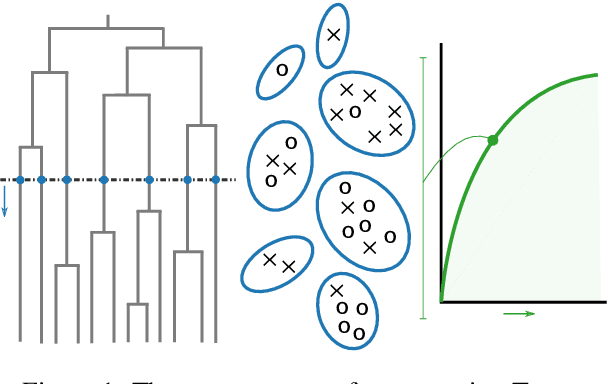
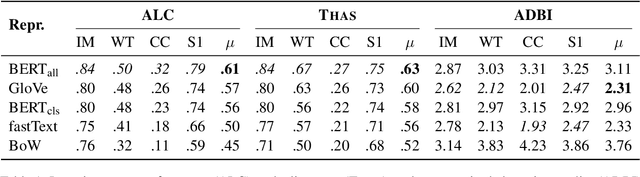
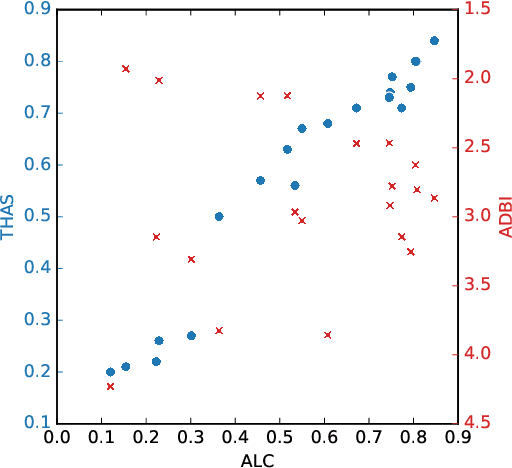

Textual representations based on pre-trained language models are key, especially in few-shot learning scenarios. What makes a representation good for text classification? Is it due to the geometric properties of the space or because it is well aligned with the task? We hypothesize the second claim. To test it, we develop a task alignment score based on hierarchical clustering that measures alignment at different levels of granularity. Our experiments on text classification validate our hypothesis by showing that task alignment can explain the classification performance of a given representation.
Are Deep Sequence Classifiers Good at Non-Trivial Generalization?
Oct 24, 2022Recent advances in deep learning models for sequence classification have greatly improved their classification accuracy, specially when large training sets are available. However, several works have suggested that under some settings the predictions made by these models are poorly calibrated. In this work we study binary sequence classification problems and we look at model calibration from a different perspective by asking the question: Are deep learning models capable of learning the underlying target class distribution? We focus on sparse sequence classification, that is problems in which the target class is rare and compare three deep learning sequence classification models. We develop an evaluation that measures how well a classifier is learning the target class distribution. In addition, our evaluation disentangles good performance achieved by mere compression of the training sequences versus performance achieved by proper model generalization. Our results suggest that in this binary setting the deep-learning models are indeed able to learn the underlying class distribution in a non-trivial manner, i.e. by proper generalization beyond data compression.
Analyzing Text Representations under Tight Annotation Budgets: Measuring Structural Alignment
Oct 11, 2022
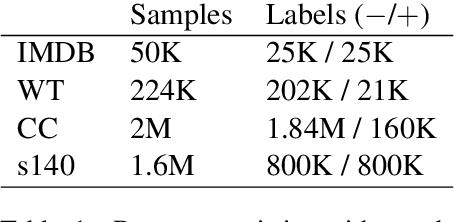
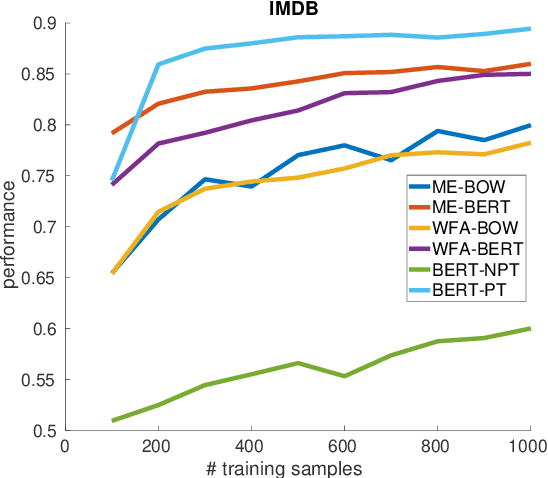
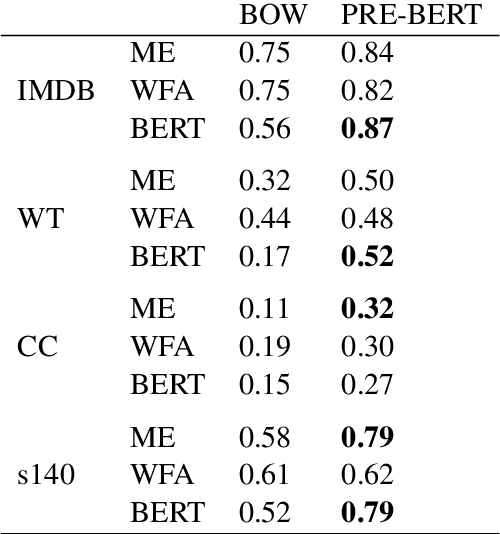
Annotating large collections of textual data can be time consuming and expensive. That is why the ability to train models with limited annotation budgets is of great importance. In this context, it has been shown that under tight annotation budgets the choice of data representation is key. The goal of this paper is to better understand why this is so. With this goal in mind, we propose a metric that measures the extent to which a given representation is structurally aligned with a task. We conduct experiments on several text classification datasets testing a variety of models and representations. Using our proposed metric we show that an efficient representation for a task (i.e. one that enables learning from few samples) is a representation that induces a good alignment between latent input structure and class structure.
Translate First Reorder Later: Leveraging Monotonicity in Semantic Parsing
Oct 10, 2022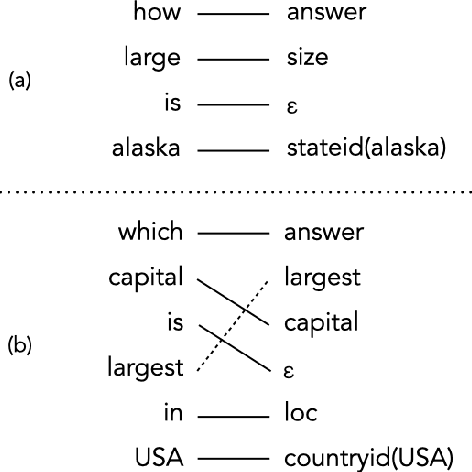
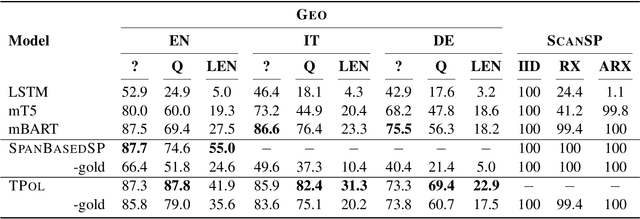
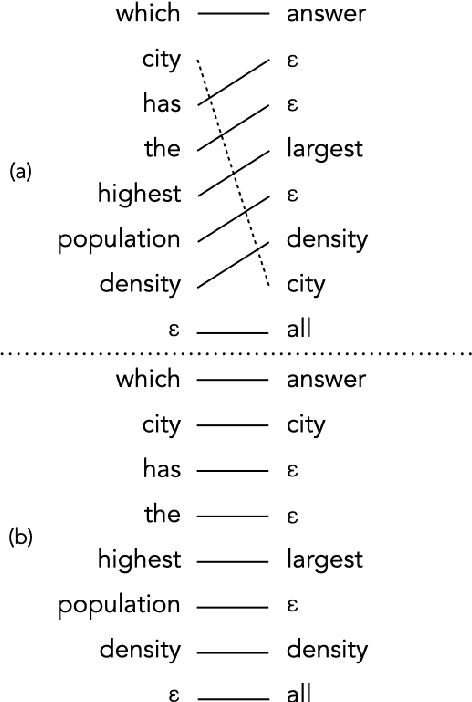

Prior work in semantic parsing has shown that conventional seq2seq models fail at compositional generalization tasks. This limitation led to a resurgence of methods that model alignments between sentences and their corresponding meaning representations, either implicitly through latent variables or explicitly by taking advantage of alignment annotations. We take the second direction and propose TPol, a two-step approach that first translates input sentences monotonically and then reorders them to obtain the correct output. This is achieved with a modular framework comprising a Translator and a Reorderer component. We test our approach on two popular semantic parsing datasets. Our experiments show that by means of the monotonic translations, TPol can learn reliable lexico-logical patterns from aligned data, significantly improving compositional generalization both over conventional seq2seq models, as well as over a recently proposed approach that exploits gold alignments.
Measuring Alignment Bias in Neural Seq2Seq Semantic Parsers
May 17, 2022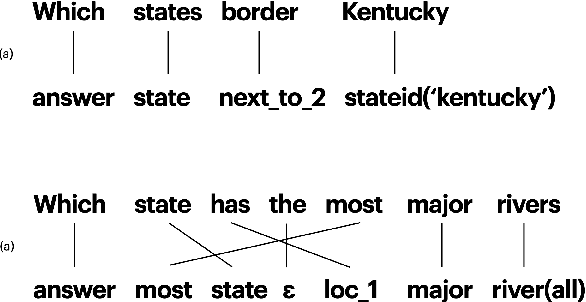
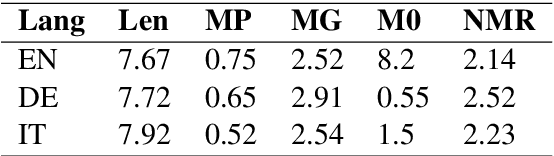
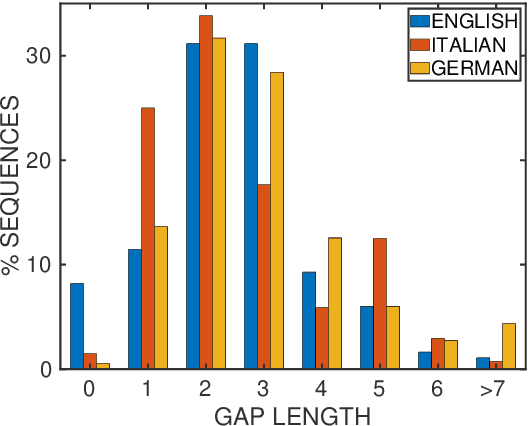
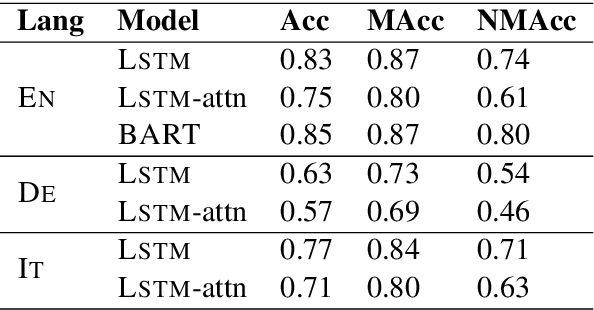
Prior to deep learning the semantic parsing community has been interested in understanding and modeling the range of possible word alignments between natural language sentences and their corresponding meaning representations. Sequence-to-sequence models changed the research landscape suggesting that we no longer need to worry about alignments since they can be learned automatically by means of an attention mechanism. More recently, researchers have started to question such premise. In this work we investigate whether seq2seq models can handle both simple and complex alignments. To answer this question we augment the popular Geo semantic parsing dataset with alignment annotations and create Geo-Aligned. We then study the performance of standard seq2seq models on the examples that can be aligned monotonically versus examples that require more complex alignments. Our empirical study shows that performance is significantly better over monotonic alignments.
A Maximum Matching Algorithm for Basis Selection in Spectral Learning
Jun 09, 2017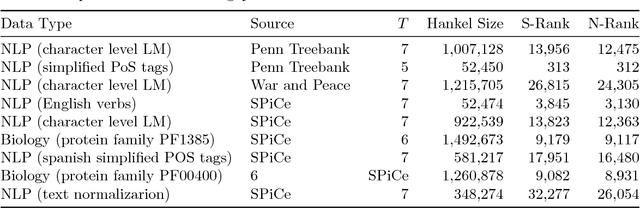
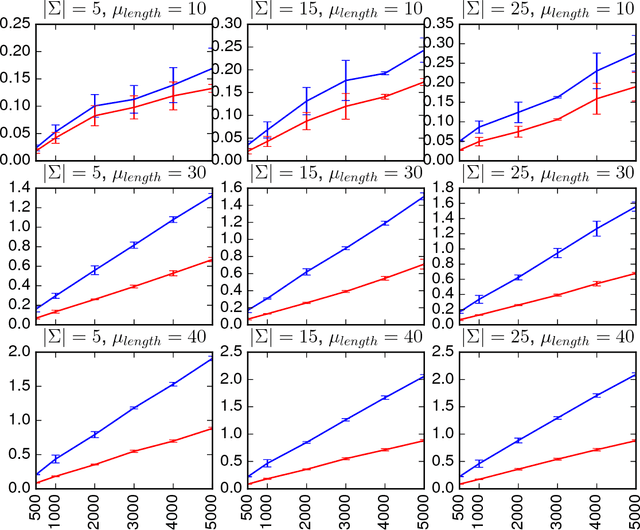
We present a solution to scale spectral algorithms for learning sequence functions. We are interested in the case where these functions are sparse (that is, for most sequences they return 0). Spectral algorithms reduce the learning problem to the task of computing an SVD decomposition over a special type of matrix called the Hankel matrix. This matrix is designed to capture the relevant statistics of the training sequences. What is crucial is that to capture long range dependencies we must consider very large Hankel matrices. Thus the computation of the SVD becomes a critical bottleneck. Our solution finds a subset of rows and columns of the Hankel that realizes a compact and informative Hankel submatrix. The novelty lies in the way that this subset is selected: we exploit a maximal bipartite matching combinatorial algorithm to look for a sub-block with full structural rank, and show how computation of this sub-block can be further improved by exploiting the specific structure of Hankel matrices.
Structured Prediction with Output Embeddings for Semantic Image Annotation
Sep 07, 2015



We address the task of annotating images with semantic tuples. Solving this problem requires an algorithm which is able to deal with hundreds of classes for each argument of the tuple. In such contexts, data sparsity becomes a key challenge, as there will be a large number of classes for which only a few examples are available. We propose handling this by incorporating feature representations of both the inputs (images) and outputs (argument classes) into a factorized log-linear model, and exploiting the flexibility of scoring functions based on bilinear forms. Experiments show that integrating feature representations of the outputs in the structured prediction model leads to better overall predictions. We also conclude that the best output representation is specific for each type of argument.