 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Pre-training Impact on Representations
May 30, 2025This empirical study analyzes the effects of the pre-training corpus on the quality of learned transformer representations. We focus on the representation quality induced solely through pre-training. Our experiments show that pre-training on a small, specialized corpus can yield effective representations, and that the success of combining a generic and a specialized corpus depends on the distributional similarity between the target task and the specialized corpus.
Analyzing Text Representations by Measuring Task Alignment
May 31, 2023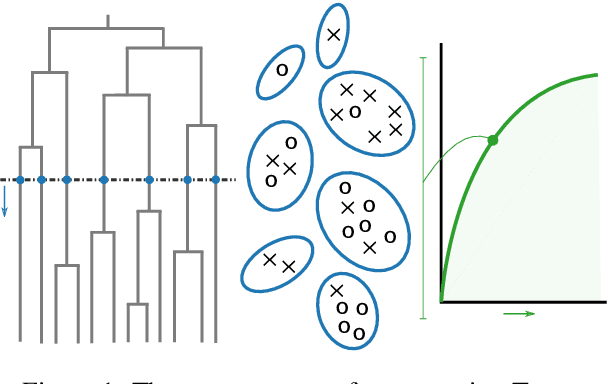
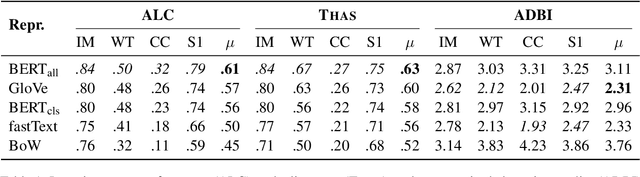
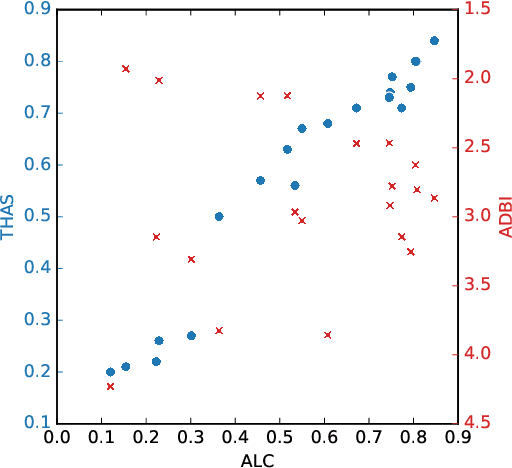

Textual representations based on pre-trained language models are key, especially in few-shot learning scenarios. What makes a representation good for text classification? Is it due to the geometric properties of the space or because it is well aligned with the task? We hypothesize the second claim. To test it, we develop a task alignment score based on hierarchical clustering that measures alignment at different levels of granularity. Our experiments on text classification validate our hypothesis by showing that task alignment can explain the classification performance of a given representation.