 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Text Representations by Measuring Task Alignment
May 31, 2023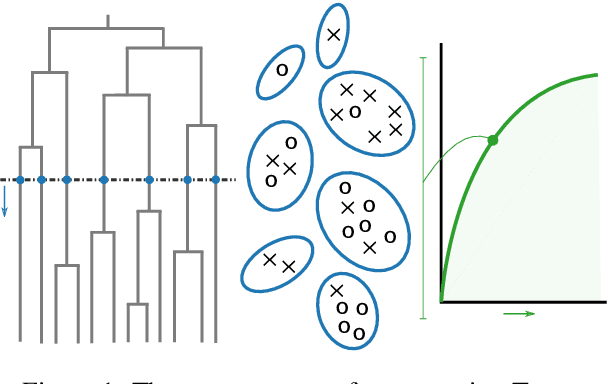
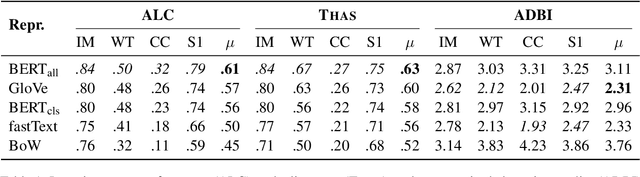
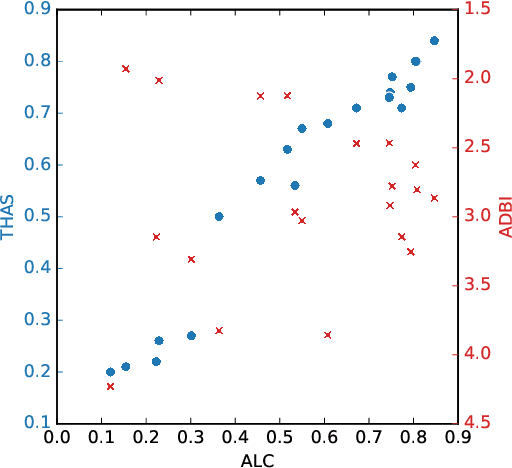

Textual representations based on pre-trained language models are key, especially in few-shot learning scenarios. What makes a representation good for text classification? Is it due to the geometric properties of the space or because it is well aligned with the task? We hypothesize the second claim. To test it, we develop a task alignment score based on hierarchical clustering that measures alignment at different levels of granularity. Our experiments on text classification validate our hypothesis by showing that task alignment can explain the classification performance of a given representation.
Analyzing Text Representations under Tight Annotation Budgets: Measuring Structural Alignment
Oct 11, 2022
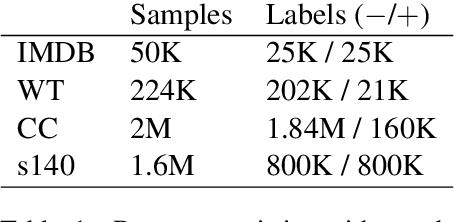
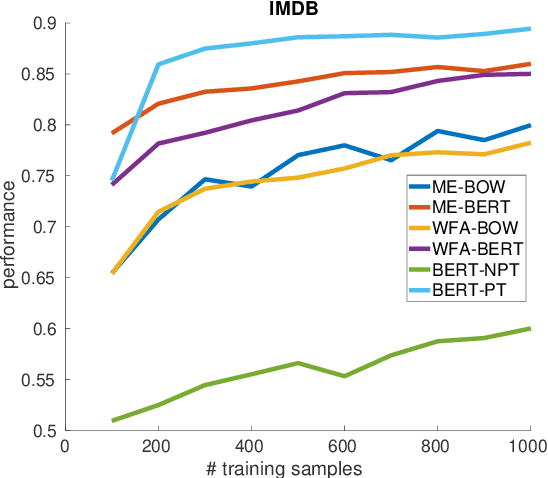
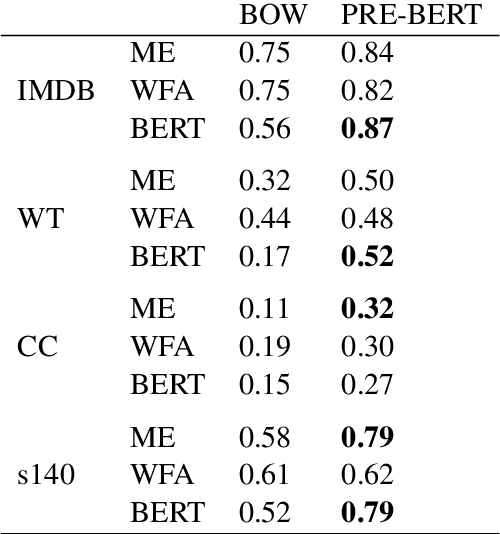
Annotating large collections of textual data can be time consuming and expensive. That is why the ability to train models with limited annotation budgets is of great importance. In this context, it has been shown that under tight annotation budgets the choice of data representation is key. The goal of this paper is to better understand why this is so. With this goal in mind, we propose a metric that measures the extent to which a given representation is structurally aligned with a task. We conduct experiments on several text classification datasets testing a variety of models and representations. Using our proposed metric we show that an efficient representation for a task (i.e. one that enables learning from few samples) is a representation that induces a good alignment between latent input structure and class structure.