 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZOGRASCOPE: A New Benchmark for Property Graphs
Mar 07, 2025Natural language interfaces to knowledge graphs have become increasingly important in recent years, enabling easy and efficient access to structured data. In particular property graphs have seen growing adoption. However, these kind of graphs remain relatively underrepresented in research, which has focused in large part on RDF-style graphs. As a matter of fact there is a lack of resources for evaluating systems on property graphs, with many existing datasets featuring relatively simple queries. To address this gap, we introduce ZOGRASCOPE, a benchmark designed specifically for the cypher query language. The benchmark includes a diverse set of manually annotated queries of varying complexity. We complement this paper with a set of experiments that test the performance of out-of-the-box LLMs of different sizes. Our experiments show that semantic parsing over graphs is still a challenging open problem that can not be solved by prompting LLMs alone.
Analyzing Text Representations by Measuring Task Alignment
May 31, 2023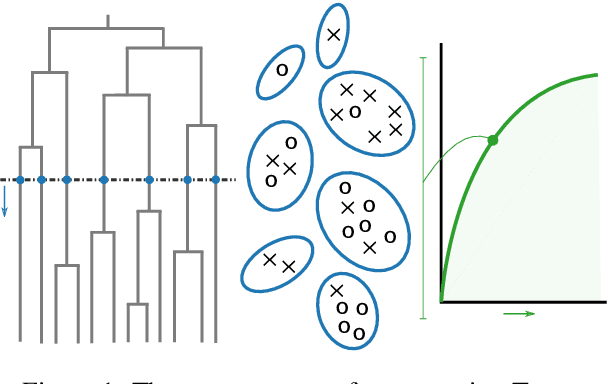
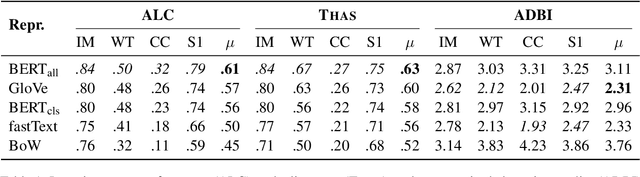
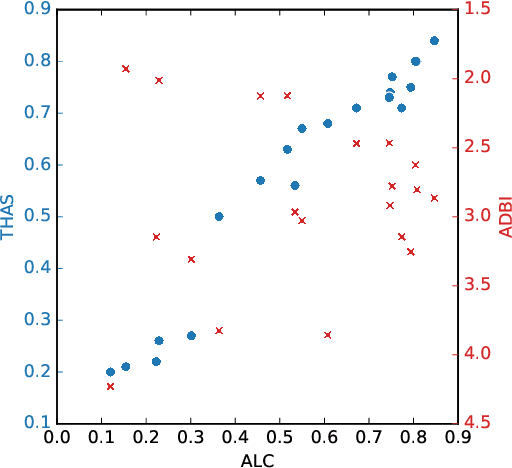

Textual representations based on pre-trained language models are key, especially in few-shot learning scenarios. What makes a representation good for text classification? Is it due to the geometric properties of the space or because it is well aligned with the task? We hypothesize the second claim. To test it, we develop a task alignment score based on hierarchical clustering that measures alignment at different levels of granularity. Our experiments on text classification validate our hypothesis by showing that task alignment can explain the classification performance of a given representation.
Are Deep Sequence Classifiers Good at Non-Trivial Generalization?
Oct 24, 2022Recent advances in deep learning models for sequence classification have greatly improved their classification accuracy, specially when large training sets are available. However, several works have suggested that under some settings the predictions made by these models are poorly calibrated. In this work we study binary sequence classification problems and we look at model calibration from a different perspective by asking the question: Are deep learning models capable of learning the underlying target class distribution? We focus on sparse sequence classification, that is problems in which the target class is rare and compare three deep learning sequence classification models. We develop an evaluation that measures how well a classifier is learning the target class distribution. In addition, our evaluation disentangles good performance achieved by mere compression of the training sequences versus performance achieved by proper model generalization. Our results suggest that in this binary setting the deep-learning models are indeed able to learn the underlying class distribution in a non-trivial manner, i.e. by proper generalization beyond data compression.
Analyzing Text Representations under Tight Annotation Budgets: Measuring Structural Alignment
Oct 11, 2022
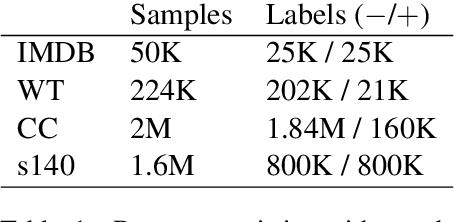
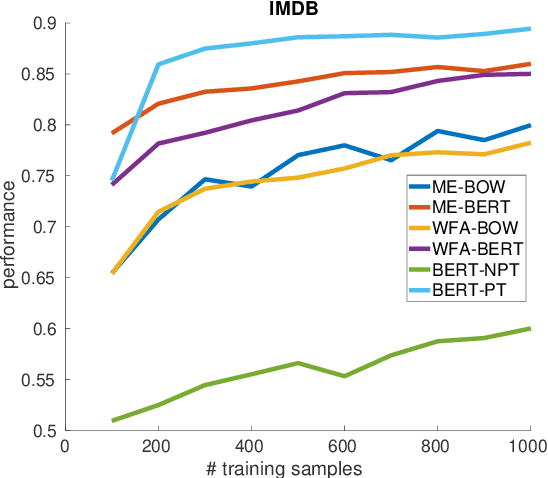
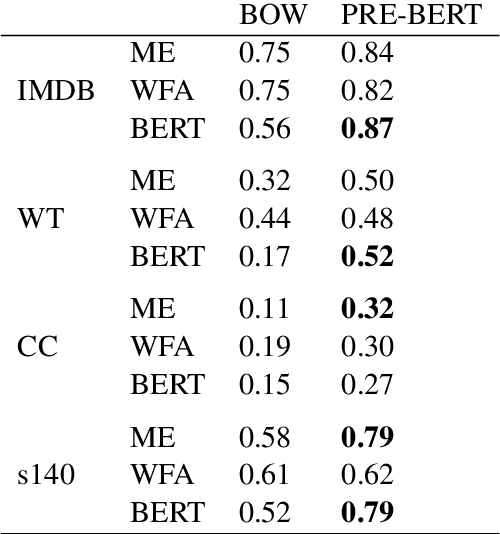
Annotating large collections of textual data can be time consuming and expensive. That is why the ability to train models with limited annotation budgets is of great importance. In this context, it has been shown that under tight annotation budgets the choice of data representation is key. The goal of this paper is to better understand why this is so. With this goal in mind, we propose a metric that measures the extent to which a given representation is structurally aligned with a task. We conduct experiments on several text classification datasets testing a variety of models and representations. Using our proposed metric we show that an efficient representation for a task (i.e. one that enables learning from few samples) is a representation that induces a good alignment between latent input structure and class structure.
Translate First Reorder Later: Leveraging Monotonicity in Semantic Parsing
Oct 10, 2022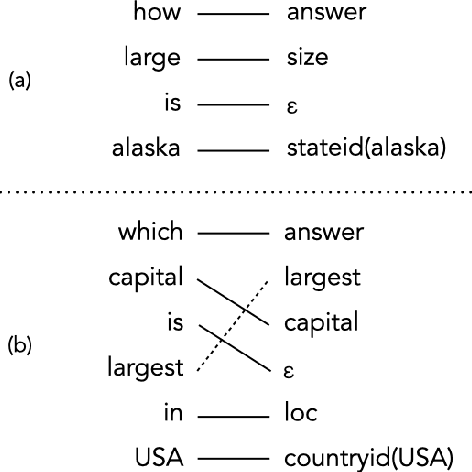
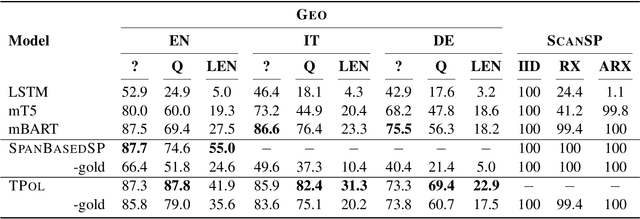
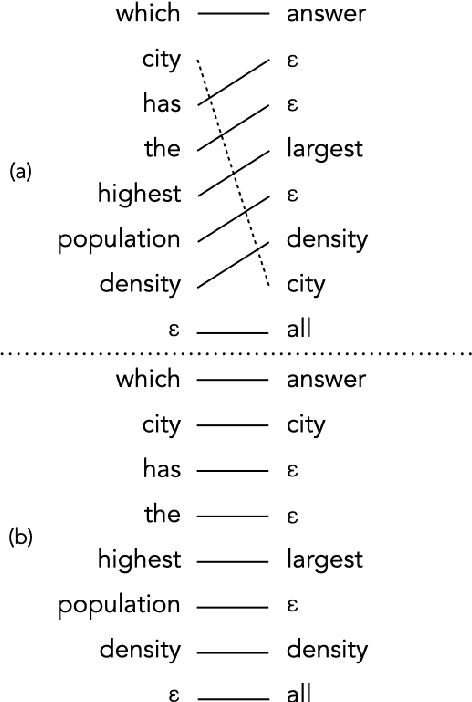

Prior work in semantic parsing has shown that conventional seq2seq models fail at compositional generalization tasks. This limitation led to a resurgence of methods that model alignments between sentences and their corresponding meaning representations, either implicitly through latent variables or explicitly by taking advantage of alignment annotations. We take the second direction and propose TPol, a two-step approach that first translates input sentences monotonically and then reorders them to obtain the correct output. This is achieved with a modular framework comprising a Translator and a Reorderer component. We test our approach on two popular semantic parsing datasets. Our experiments show that by means of the monotonic translations, TPol can learn reliable lexico-logical patterns from aligned data, significantly improving compositional generalization both over conventional seq2seq models, as well as over a recently proposed approach that exploits gold alignments.